 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2026 Competition on Low-Resolution License Plate Recognition
Apr 24, 2026Low-Resolution License Plate Recognition (LRLPR) remains a challenging problem in real-world surveillance scenarios, where long capture distances, compression artifacts, and adverse imaging conditions can severely degrade license plate legibility. To promote progress in this area, we organized the ICPR 2026 Competition on Low-Resolution License Plate Recognition, the first competition specifically dedicated to LRLPR using real low-quality data collected under operationally relevant conditions. The competition was based on the LRLPR-26 dataset, which comprises 20,000 training tracks and 3,000 test tracks; each training track contains five low-resolution and five high-resolution images of the same license plate. Notably, a total of 269 teams from 41 countries registered for the competition, and 99 teams submitted valid entries in the Blind Test Phase. The winning team achieved a Recognition Rate of 82.13%, and four teams surpassed the 80% mark, highlighting both the high level of competition at the top of the leaderboard and the continued difficulty of the task. In addition to presenting the competition design, evaluation protocol, and main results, this paper summarizes the methods adopted by the top-5 teams and discusses current trends and promising directions for future research on LRLPR. The competition webpage is available at https://icpr26lrlpr.github.io/
U-Singer: Multi-Singer Singing Voice Synthesizer that Controls Emotional Intensity
Mar 02, 2022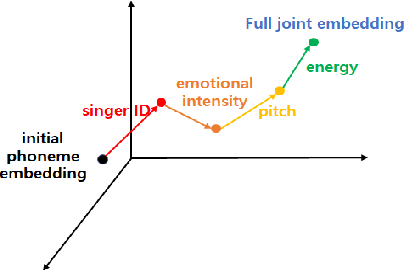
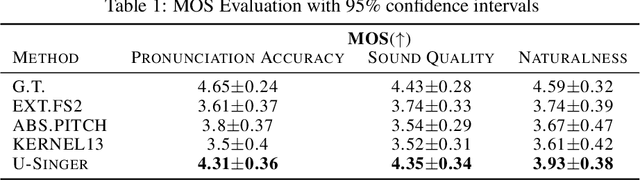
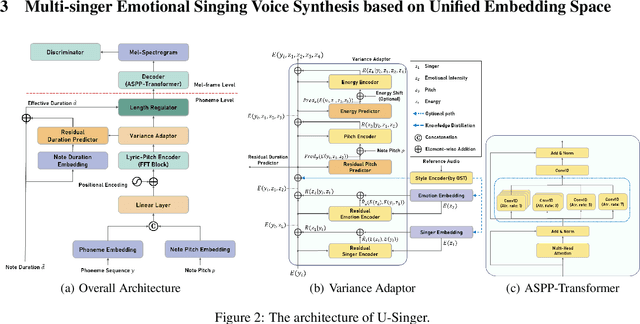
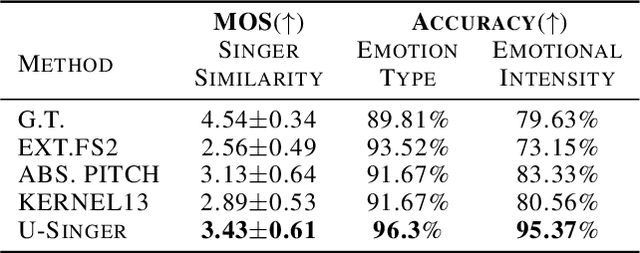
We propose U-Singer, the first multi-singer emotional singing voice synthesizer that expresses various levels of emotional intensity. During synthesizing singing voices according to the lyrics, pitch, and duration of the music score, U-Singer reflects singer characteristics and emotional intensity by adding variances in pitch, energy, and phoneme duration according to singer ID and emotional intensity. Representing all attributes by conditional residual embeddings in a single unified embedding space, U-Singer controls mutually correlated style attributes, minimizing interference. Additionally, we apply emotion embedding interpolation and extrapolation techniques that lead the model to learn a linear embedding space and allow the model to express emotional intensity levels not included in the training data. In experiments, U-Singer synthesized high-fidelity singing voices reflecting the singer ID and emotional intensity. The visualization of the unified embedding space exhibits that U-singer estimates the correct variations in pitch and energy highly correlated with the singer ID and emotional intensity level. The audio samples are presented at https://u-singer.github.io.