 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023



Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
CoMaL: Conditional Maximum Likelihood Approach to Self-supervised Domain Adaptation in Long-tail Semantic Segmentation
Apr 14, 2023



The research in self-supervised domain adaptation in semantic segmentation has recently received considerable attention. Although GAN-based methods have become one of the most popular approaches to domain adaptation, they have suffered from some limitations. They are insufficient to model both global and local structures of a given image, especially in small regions of tail classes. Moreover, they perform bad on the tail classes containing limited number of pixels or less training samples. In order to address these issues, we present a new self-supervised domain adaptation approach to tackle long-tail semantic segmentation in this paper. Firstly, a new metric is introduced to formulate long-tail domain adaptation in the segmentation problem. Secondly, a new Conditional Maximum Likelihood (CoMaL) approach in an autoregressive framework is presented to solve the problem of long-tail domain adaptation. Although other segmentation methods work under the pixel independence assumption, the long-tailed pixel distributions in CoMaL are generally solved in the context of structural dependency, as that is more realistic. Finally, the proposed method is evaluated on popular large-scale semantic segmentation benchmarks, i.e., "SYNTHIA to Cityscapes" and "GTA to Cityscapes", and outperforms the prior methods by a large margin in both the standard and the proposed evaluation protocols.
Fairness in Visual Clustering: A Novel Transformer Clustering Approach
Apr 14, 2023



Promoting fairness for deep clustering models in unsupervised clustering settings to reduce demographic bias is a challenging goal. This is because of the limitation of large-scale balanced data with well-annotated labels for sensitive or protected attributes. In this paper, we first evaluate demographic bias in deep clustering models from the perspective of cluster purity, which is measured by the ratio of positive samples within a cluster to their correlation degree. This measurement is adopted as an indication of demographic bias. Then, a novel loss function is introduced to encourage a purity consistency for all clusters to maintain the fairness aspect of the learned clustering model. Moreover, we present a novel attention mechanism, Cross-attention, to measure correlations between multiple clusters, strengthening faraway positive samples and improving the purity of clusters during the learning process. Experimental results on a large-scale dataset with numerous attribute settings have demonstrated the effectiveness of the proposed approach on both clustering accuracy and fairness enhancement on several sensitive attributes.
Micron-BERT: BERT-based Facial Micro-Expression Recognition
Apr 06, 2023



Micro-expression recognition is one of the most challenging topics in affective computing. It aims to recognize tiny facial movements difficult for humans to perceive in a brief period, i.e., 0.25 to 0.5 seconds. Recent advances in pre-training deep Bidirectional Transformers (BERT) have significantly improved self-supervised learning tasks in computer vision. However, the standard BERT in vision problems is designed to learn only from full images or videos, and the architecture cannot accurately detect details of facial micro-expressions. This paper presents Micron-BERT ($\mu$-BERT), a novel approach to facial micro-expression recognition. The proposed method can automatically capture these movements in an unsupervised manner based on two key ideas. First, we employ Diagonal Micro-Attention (DMA) to detect tiny differences between two frames. Second, we introduce a new Patch of Interest (PoI) module to localize and highlight micro-expression interest regions and simultaneously reduce noisy backgrounds and distractions. By incorporating these components into an end-to-end deep network, the proposed $\mu$-BERT significantly outperforms all previous work in various micro-expression tasks. $\mu$-BERT can be trained on a large-scale unlabeled dataset, i.e., up to 8 million images, and achieves high accuracy on new unseen facial micro-expression datasets. Empirical experiments show $\mu$-BERT consistently outperforms state-of-the-art performance on four micro-expression benchmarks, including SAMM, CASME II, SMIC, and CASME3, by significant margins. Code will be available at \url{https://github.com/uark-cviu/Micron-BERT}
FREDOM: Fairness Domain Adaptation Approach to Semantic Scene Understanding
Apr 04, 2023



Although Domain Adaptation in Semantic Scene Segmentation has shown impressive improvement in recent years, the fairness concerns in the domain adaptation have yet to be well defined and addressed. In addition, fairness is one of the most critical aspects when deploying the segmentation models into human-related real-world applications, e.g., autonomous driving, as any unfair predictions could influence human safety. In this paper, we propose a novel Fairness Domain Adaptation (FREDOM) approach to semantic scene segmentation. In particular, from the proposed formulated fairness objective, a new adaptation framework will be introduced based on the fair treatment of class distributions. Moreover, to generally model the context of structural dependency, a new conditional structural constraint is introduced to impose the consistency of predicted segmentation. Thanks to the proposed Conditional Structure Network, the self-attention mechanism has sufficiently modeled the structural information of segmentation. Through the ablation studies, the proposed method has shown the performance improvement of the segmentation models and promoted fairness in the model predictions. The experimental results on the two standard benchmarks, i.e., SYNTHIA $\to$ Cityscapes and GTA5 $\to$ Cityscapes, have shown that our method achieved State-of-the-Art (SOTA) performance.
Contextual Explainable Video Representation: Human Perception-based Understanding
Dec 17, 2022



Video understanding is a growing field and a subject of intense research, which includes many interesting tasks to understanding both spatial and temporal information, e.g., action detection, action recognition, video captioning, video retrieval. One of the most challenging problems in video understanding is dealing with feature extraction, i.e. extract contextual visual representation from given untrimmed video due to the long and complicated temporal structure of unconstrained videos. Different from existing approaches, which apply a pre-trained backbone network as a black-box to extract visual representation, our approach aims to extract the most contextual information with an explainable mechanism. As we observed, humans typically perceive a video through the interactions between three main factors, i.e., the actors, the relevant objects, and the surrounding environment. Therefore, it is very crucial to design a contextual explainable video representation extraction that can capture each of such factors and model the relationships between them. In this paper, we discuss approaches, that incorporate the human perception process into modeling actors, objects, and the environment. We choose video paragraph captioning and temporal action detection to illustrate the effectiveness of human perception based-contextual representation in video understanding. Source code is publicly available at https://github.com/UARK-AICV/Video_Representation.
Neural Cell Video Synthesis via Optical-Flow Diffusion
Dec 06, 2022



The biomedical imaging world is notorious for working with small amounts of data, frustrating state-of-the-art efforts in the computer vision and deep learning worlds. With large datasets, it is easier to make progress we have seen from the natural image distribution. It is the same with microscopy videos of neuron cells moving in a culture. This problem presents several challenges as it can be difficult to grow and maintain the culture for days, and it is expensive to acquire the materials and equipment. In this work, we explore how to alleviate this data scarcity problem by synthesizing the videos. We, therefore, take the recent work of the video diffusion model to synthesize videos of cells from our training dataset. We then analyze the model's strengths and consistent shortcomings to guide us on improving video generation to be as high-quality as possible. To improve on such a task, we propose modifying the denoising function and adding motion information (dense optical flow) so that the model has more context regarding how video frames transition over time and how each pixel changes over time.
CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars
Dec 01, 2022



Although unsupervised domain adaptation methods have achieved remarkable performance in semantic scene segmentation in visual perception for self-driving cars, these approaches remain impractical in real-world use cases. In practice, the segmentation models may encounter new data that have not been seen yet. Also, the previous data training of segmentation models may be inaccessible due to privacy problems. Therefore, to address these problems, in this work, we propose a Continual Unsupervised Domain Adaptation (CONDA) approach that allows the model to continuously learn and adapt with respect to the presence of the new data. Moreover, our proposed approach is designed without the requirement of accessing previous training data. To avoid the catastrophic forgetting problem and maintain the performance of the segmentation models, we present a novel Bijective Maximum Likelihood loss to impose the constraint of predicted segmentation distribution shifts. The experimental results on the benchmark of continual unsupervised domain adaptation have shown the advanced performance of the proposed CONDA method.
Multi-Camera Multi-Object Tracking on the Move via Single-Stage Global Association Approach
Nov 17, 2022



The development of autonomous vehicles generates a tremendous demand for a low-cost solution with a complete set of camera sensors capturing the environment around the car. It is essential for object detection and tracking to address these new challenges in multi-camera settings. In order to address these challenges, this work introduces novel Single-Stage Global Association Tracking approaches to associate one or more detection from multi-cameras with tracked objects. These approaches aim to solve fragment-tracking issues caused by inconsistent 3D object detection. Moreover, our models also improve the detection accuracy of the standard vision-based 3D object detectors in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method by outperforming prior vision-based tracking methods in multi-camera settings.
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022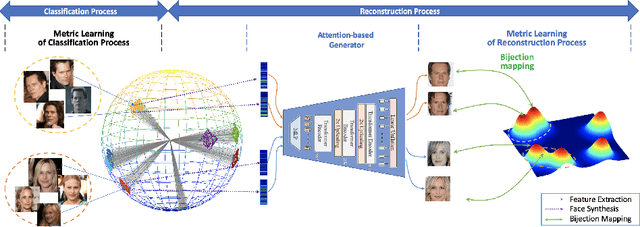

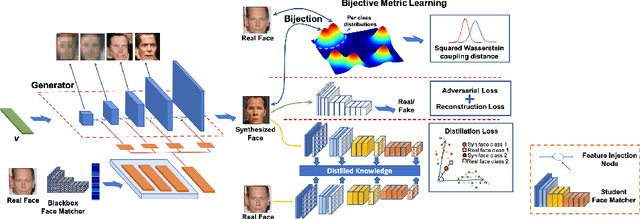
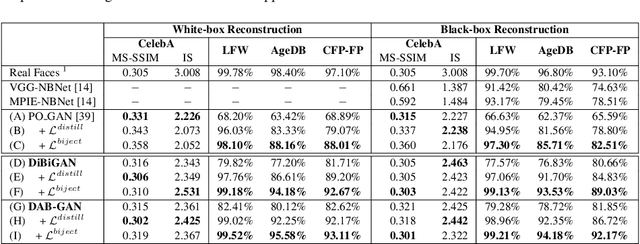
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.