 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Document Revision: Grammatical Error Correction, Fluency Edits, and Beyond
May 23, 2022


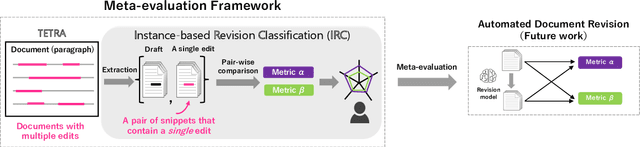
Natural language processing technology has rapidly improved automated grammatical error correction tasks, and the community begins to explore document-level revision as one of the next challenges. To go beyond sentence-level automated grammatical error correction to NLP-based document-level revision assistant, there are two major obstacles: (1) there are few public corpora with document-level revisions being annotated by professional editors, and (2) it is not feasible to elicit all possible references and evaluate the quality of revision with such references because there are infinite possibilities of revision. This paper tackles these challenges. First, we introduce a new document-revision corpus, TETRA, where professional editors revised academic papers sampled from the ACL anthology which contain few trivial grammatical errors that enable us to focus more on document- and paragraph-level edits such as coherence and consistency. Second, we explore reference-less and interpretable methods for meta-evaluation that can detect quality improvements by document revision. We show the uniqueness of TETRA compared with existing document revision corpora and demonstrate that a fine-tuned pre-trained language model can discriminate the quality of documents after revision even when the difference is subtle. This promising result will encourage the community to further explore automated document revision models and metrics in future.
Context Limitations Make Neural Language Models More Human-Like
May 23, 2022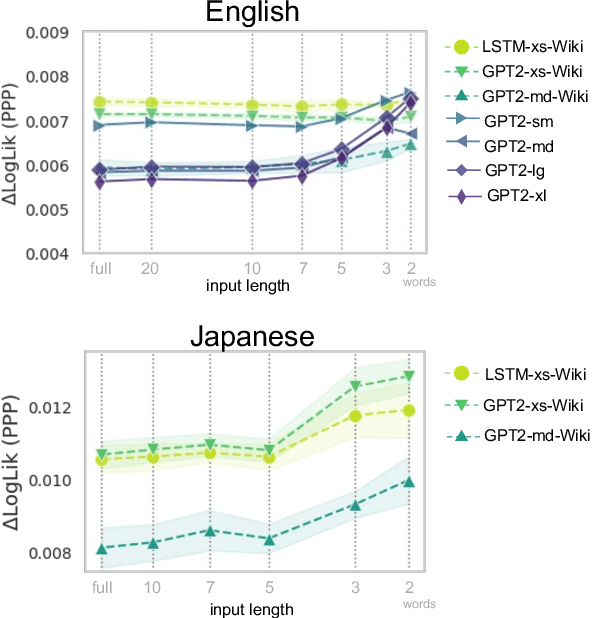


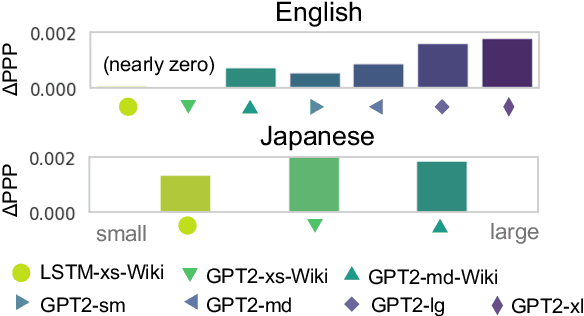
Do modern natural language processing (NLP) models exhibit human-like language processing? How can they be made more human-like? These questions are motivated by psycholinguistic studies for understanding human language processing as well as engineering efforts. In this study, we demonstrate the discrepancies in context access between modern neural language models (LMs) and humans in incremental sentence processing. Additional context limitation was needed to make LMs better simulate human reading behavior. Our analyses also showed that human-LM gaps in memory access are associated with specific syntactic constructions; incorporating additional syntactic factors into LMs' context access could enhance their cognitive plausibility.
LPAttack: A Feasible Annotation Scheme for Capturing Logic Pattern of Attacks in Arguments
Apr 04, 2022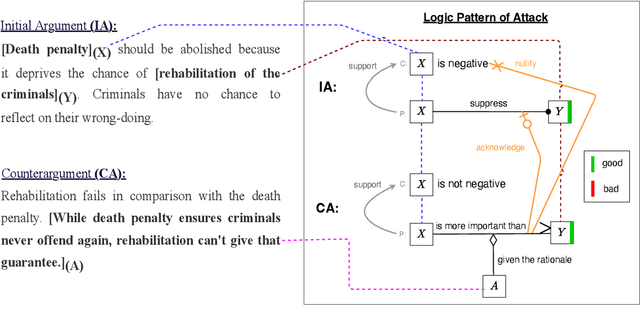
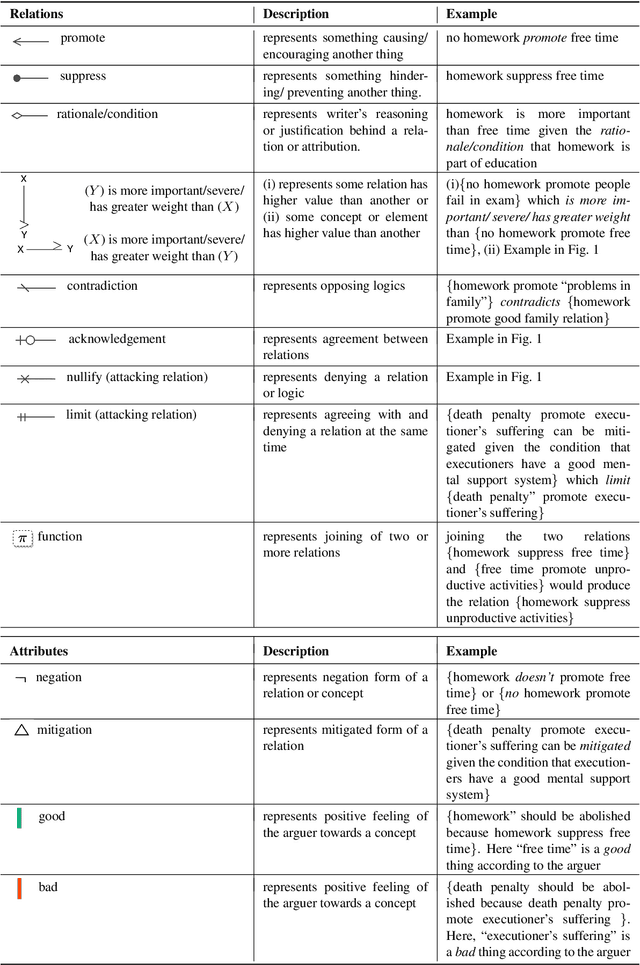

In argumentative discourse, persuasion is often achieved by refuting or attacking others arguments. Attacking is not always straightforward and often comprise complex rhetorical moves such that arguers might agree with a logic of an argument while attacking another logic. Moreover, arguer might neither deny nor agree with any logics of an argument, instead ignore them and attack the main stance of the argument by providing new logics and presupposing that the new logics have more value or importance than the logics present in the attacked argument. However, no existing studies in the computational argumentation capture such complex rhetorical moves in attacks or the presuppositions or value judgements in them. In order to address this gap, we introduce LPAttack, a novel annotation scheme that captures the common modes and complex rhetorical moves in attacks along with the implicit presuppositions and value judgements in them. Our annotation study shows moderate inter-annotator agreement, indicating that human annotation for the proposed scheme is feasible. We publicly release our annotated corpus and the annotation guidelines.
COPA-SSE: Semi-structured Explanations for Commonsense Reasoning
Jan 19, 2022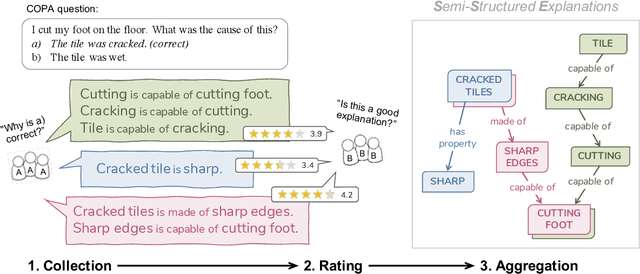


We present Semi-Structured Explanations for COPA (COPA-SSE), a new crowdsourced dataset of 9,747 semi-structured, English common sense explanations for COPA questions. The explanations are formatted as a set of triple-like common sense statements with ConceptNet relations but freely written concepts. This semi-structured format strikes a balance between the high quality but low coverage of structured data and the lower quality but high coverage of free-form crowdsourcing. Each explanation also includes a set of human-given quality ratings. With their familiar format, the explanations are geared towards commonsense reasoners operating on knowledge graphs and serve as a starting point for ongoing work on improving such systems.
TYPIC: A Corpus of Template-Based Diagnostic Comments on Argumentation
Jan 18, 2022



Providing feedback on the argumentation of learner is essential for development of critical thinking skills, but it takes a lot of time and effort. To reduce the burden on teachers, we aim to automate a process of giving feedback, especially giving diagnostic comments which point out the weaknesses inherent in the argumentation. It is advisable to give specific diagnostic comments so that learners can recognize the diagnosis without misunderstanding. However, it is not obvious how the task of providing specific diagnostic comments should be formulated. We present a formulation of the task as template selection and slot filling to make an automatic evaluation easier and the behavior of the model more tractable. The key to the formulation is the possibility of creating a template set that is sufficient for practical use. In this paper, we define three criteria that a template set should satisfy: expressiveness, informativeness, and uniqueness, and verify the feasibility to create a template set that satisfies these criteria as a first trial. We will show that it is feasible through an annotation study that converts diagnostic comments given in text into a template format. The corpus used in the annotation study is publicly available.
Annotating Implicit Reasoning in Arguments with Causal Links
Oct 26, 2021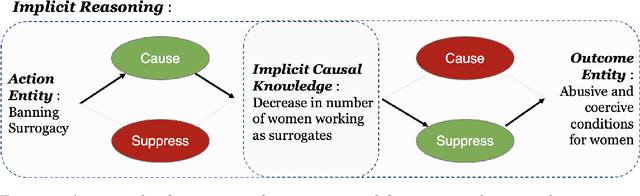
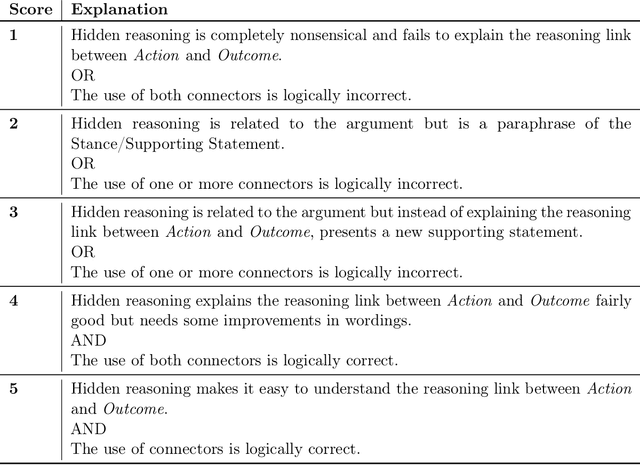

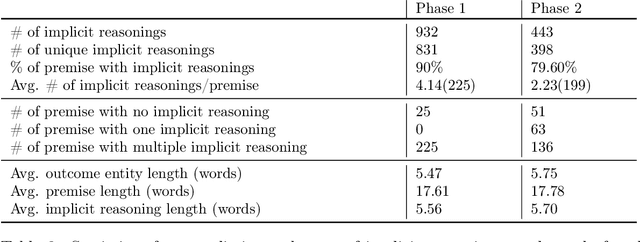
Most of the existing work that focus on the identification of implicit knowledge in arguments generally represent implicit knowledge in the form of commonsense or factual knowledge. However, such knowledge is not sufficient to understand the implicit reasoning link between individual argumentative components (i.e., claim and premise). In this work, we focus on identifying the implicit knowledge in the form of argumentation knowledge which can help in understanding the reasoning link in arguments. Being inspired by the Argument from Consequences scheme, we propose a semi-structured template to represent such argumentation knowledge that explicates the implicit reasoning in arguments via causality. We create a novel two-phase annotation process with simplified guidelines and show how to collect and filter high-quality implicit reasonings via crowdsourcing. We find substantial inter-annotator agreement for quality evaluation between experts, but find evidence that casts a few questions on the feasibility of collecting high-quality semi-structured implicit reasoning through our crowdsourcing process. We release our materials(i.e., crowdsourcing guidelines and collected implicit reasonings) to facilitate further research towards the structured representation of argumentation knowledge.
Instance-Based Neural Dependency Parsing
Sep 28, 2021
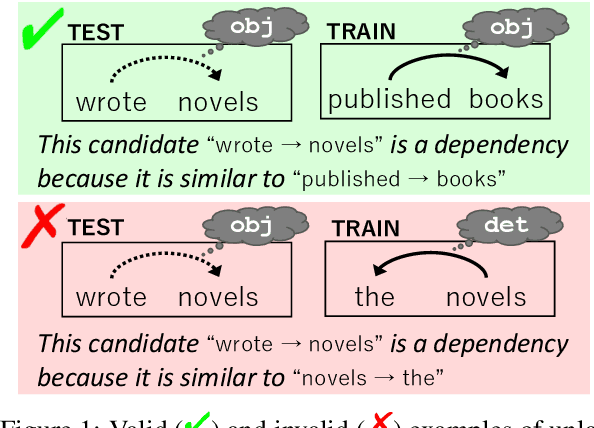

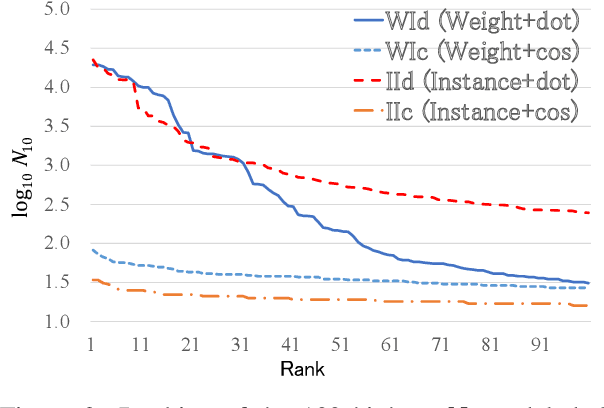
Interpretable rationales for model predictions are crucial in practical applications. We develop neural models that possess an interpretable inference process for dependency parsing. Our models adopt instance-based inference, where dependency edges are extracted and labeled by comparing them to edges in a training set. The training edges are explicitly used for the predictions; thus, it is easy to grasp the contribution of each edge to the predictions. Our experiments show that our instance-based models achieve competitive accuracy with standard neural models and have the reasonable plausibility of instance-based explanations.
Incorporating Residual and Normalization Layers into Analysis of Masked Language Models
Sep 15, 2021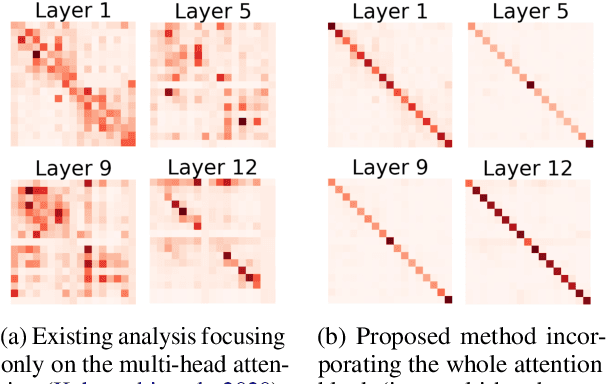
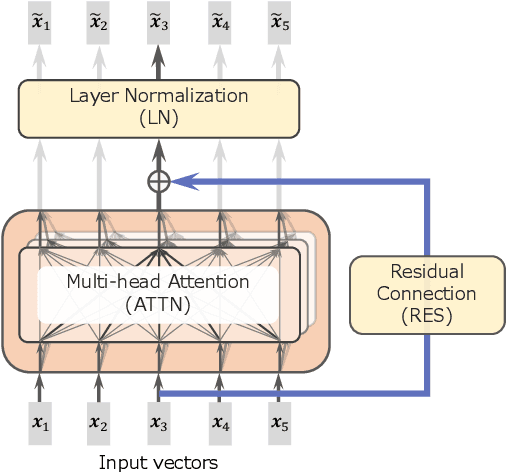
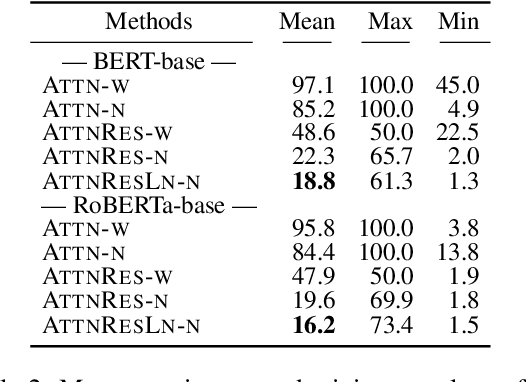
Transformer architecture has become ubiquitous in the natural language processing field. To interpret the Transformer-based models, their attention patterns have been extensively analyzed. However, the Transformer architecture is not only composed of the multi-head attention; other components can also contribute to Transformers' progressive performance. In this study, we extended the scope of the analysis of Transformers from solely the attention patterns to the whole attention block, i.e., multi-head attention, residual connection, and layer normalization. Our analysis of Transformer-based masked language models shows that the token-to-token interaction performed via attention has less impact on the intermediate representations than previously assumed. These results provide new intuitive explanations of existing reports; for example, discarding the learned attention patterns tends not to adversely affect the performance. The codes of our experiments are publicly available.
Transformer-based Lexically Constrained Headline Generation
Sep 15, 2021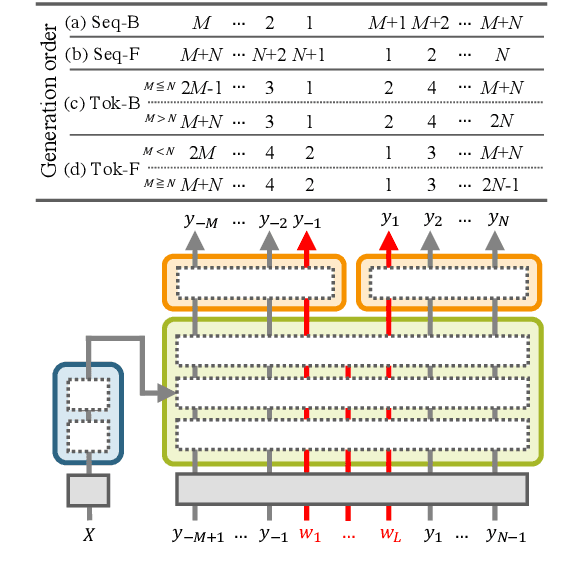

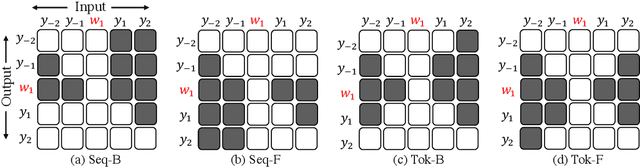

This paper explores a variant of automatic headline generation methods, where a generated headline is required to include a given phrase such as a company or a product name. Previous methods using Transformer-based models generate a headline including a given phrase by providing the encoder with additional information corresponding to the given phrase. However, these methods cannot always include the phrase in the generated headline. Inspired by previous RNN-based methods generating token sequences in backward and forward directions from the given phrase, we propose a simple Transformer-based method that guarantees to include the given phrase in the high-quality generated headline. We also consider a new headline generation strategy that takes advantage of the controllable generation order of Transformer. Our experiments with the Japanese News Corpus demonstrate that our methods, which are guaranteed to include the phrase in the generated headline, achieve ROUGE scores comparable to previous Transformer-based methods. We also show that our generation strategy performs better than previous strategies.
Summarize-then-Answer: Generating Concise Explanations for Multi-hop Reading Comprehension
Sep 14, 2021
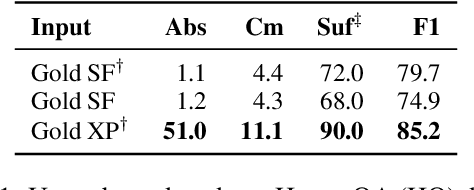
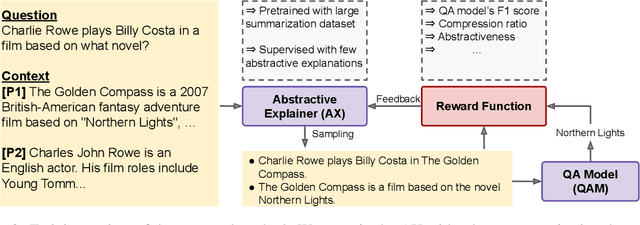
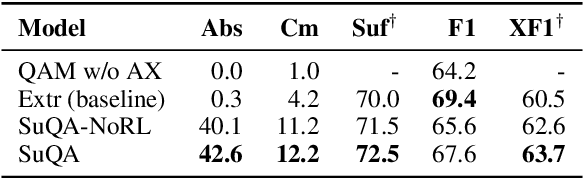
How can we generate concise explanations for multi-hop Reading Comprehension (RC)? The current strategies of identifying supporting sentences can be seen as an extractive question-focused summarization of the input text. However, these extractive explanations are not necessarily concise i.e. not minimally sufficient for answering a question. Instead, we advocate for an abstractive approach, where we propose to generate a question-focused, abstractive summary of input paragraphs and then feed it to an RC system. Given a limited amount of human-annotated abstractive explanations, we train the abstractive explainer in a semi-supervised manner, where we start from the supervised model and then train it further through trial and error maximizing a conciseness-promoted reward function. Our experiments demonstrate that the proposed abstractive explainer can generate more compact explanations than an extractive explainer with limited supervision (only 2k instances) while maintaining sufficiency.