 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling Makes Overtraining Compute-Optimal
Apr 01, 2026Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T^2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T^2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T^2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T^2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T^2$ scaling meaningful in modern deployments.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022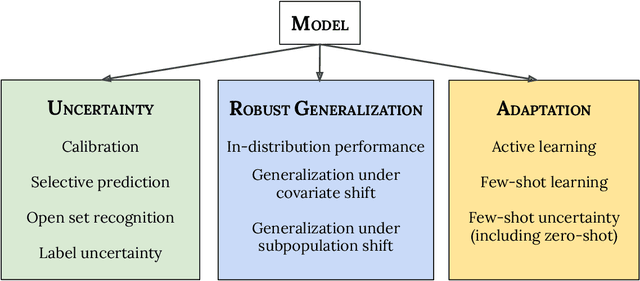

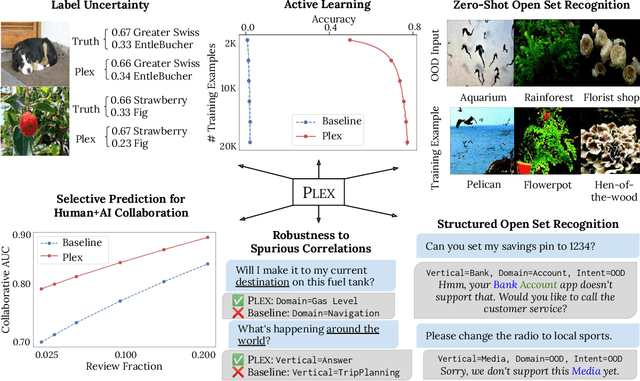

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.