 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Flows are Shapley Value Explanations
May 31, 2021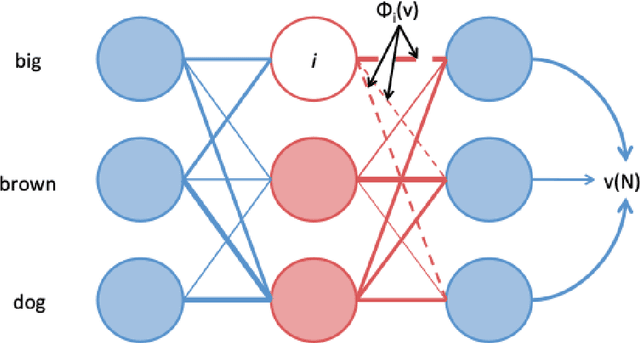
Shapley Values, a solution to the credit assignment problem in cooperative game theory, are a popular type of explanation in machine learning, having been used to explain the importance of features, embeddings, and even neurons. In NLP, however, leave-one-out and attention-based explanations still predominate. Can we draw a connection between these different methods? We formally prove that -- save for the degenerate case -- attention weights and leave-one-out values cannot be Shapley Values. $\textit{Attention flow}$ is a post-processed variant of attention weights obtained by running the max-flow algorithm on the attention graph. Perhaps surprisingly, we prove that attention flows are indeed Shapley Values, at least at the layerwise level. Given the many desirable theoretical qualities of Shapley Values -- which has driven their adoption among the ML community -- we argue that NLP practitioners should, when possible, adopt attention flow explanations alongside more traditional ones.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021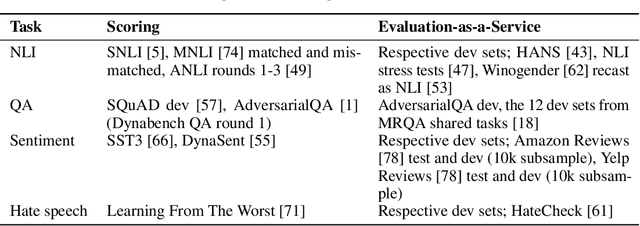
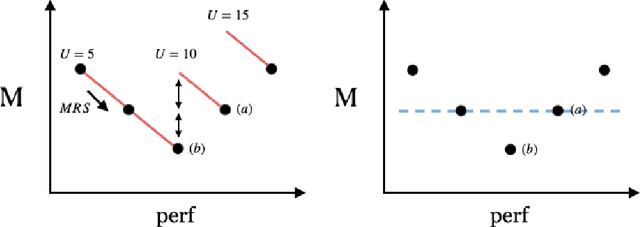
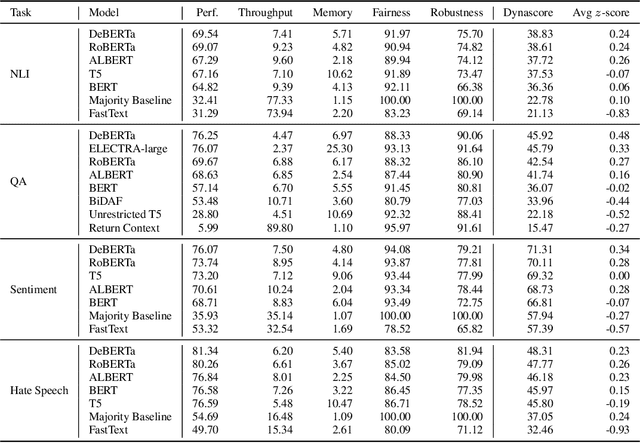
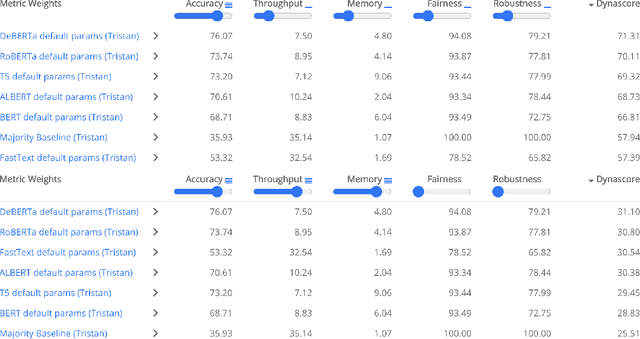
We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.
Frequency-based Distortions in Contextualized Word Embeddings
Apr 17, 2021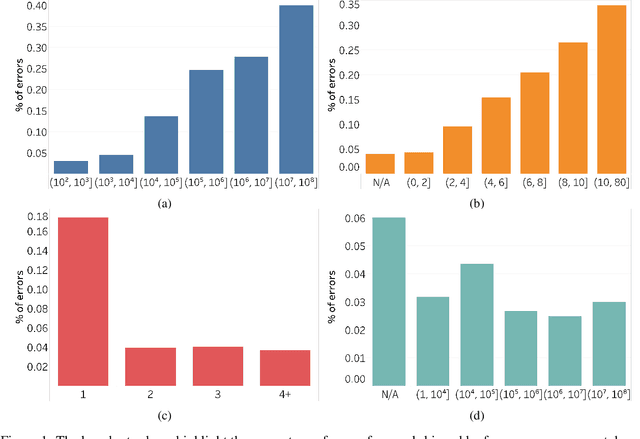
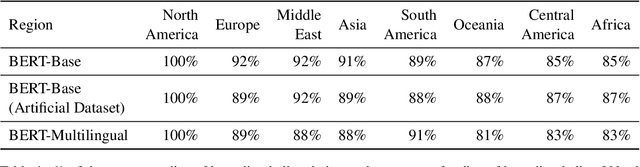
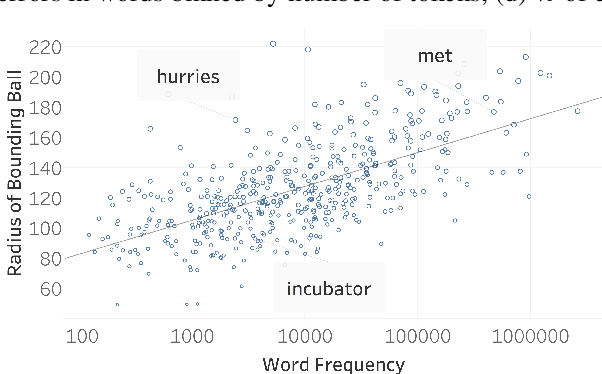
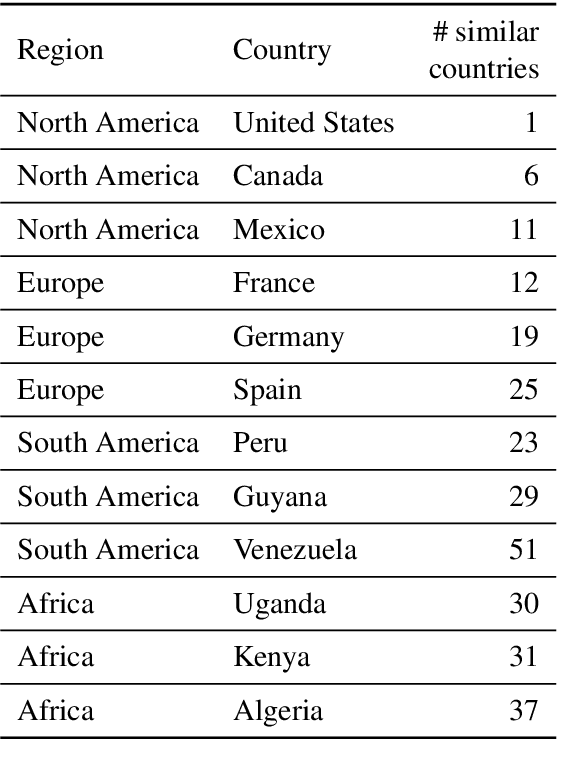
How does word frequency in pre-training data affect the behavior of similarity metrics in contextualized BERT embeddings? Are there systematic ways in which some word relationships are exaggerated or understated? In this work, we explore the geometric characteristics of contextualized word embeddings with two novel tools: (1) an identity probe that predicts the identity of a word using its embedding; (2) the minimal bounding sphere for a word's contextualized representations. Our results reveal that words of high and low frequency differ significantly with respect to their representational geometry. Such differences introduce distortions: when compared to human judgments, point estimates of embedding similarity (e.g., cosine similarity) can over- or under-estimate the semantic similarity of two words, depending on the frequency of those words in the training data. This has downstream societal implications: BERT-Base has more trouble differentiating between South American and African countries than North American and European ones. We find that these distortions persist when using BERT-Multilingual, suggesting that they cannot be easily fixed with additional data, which in turn introduces new distortions.
Utility is in the Eye of the User: A Critique of NLP Leaderboards
Oct 15, 2020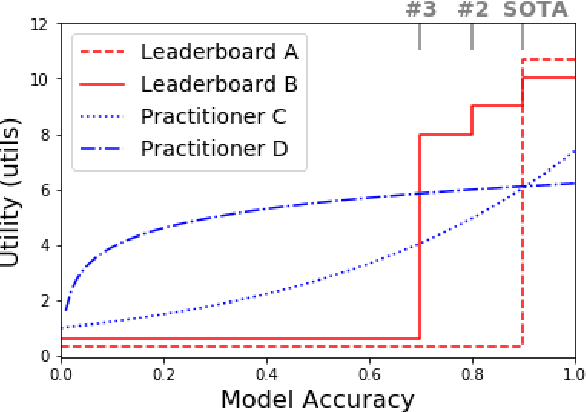
Benchmarks such as GLUE have helped drive advances in NLP by incentivizing the creation of more accurate models. While this leaderboard paradigm has been remarkably successful, a historical focus on performance-based evaluation has been at the expense of other qualities that the NLP community values in models, such as compactness, fairness, and energy efficiency. In this opinion paper, we study the divergence between what is incentivized by leaderboards and what is useful in practice through the lens of microeconomic theory. We frame both the leaderboard and NLP practitioners as consumers and the benefit they get from a model as its utility to them. With this framing, we formalize how leaderboards -- in their current form -- can be poor proxies for the NLP community at large. For example, a highly inefficient model would provide less utility to practitioners but not to a leaderboard, since it is a cost that only the former must bear. To allow practitioners to better estimate a model's utility to them, we advocate for more transparency on leaderboards, such as the reporting of statistics that are of practical concern (e.g., model size, energy efficiency, and inference latency).
BLEU Neighbors: A Reference-less Approach to Automatic Evaluation
Apr 29, 2020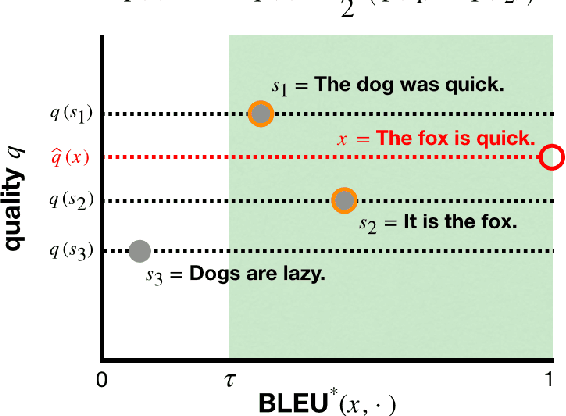
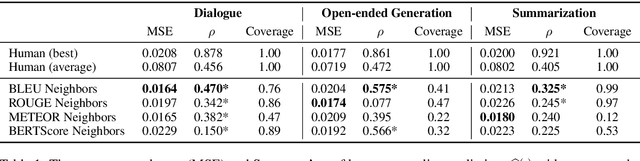
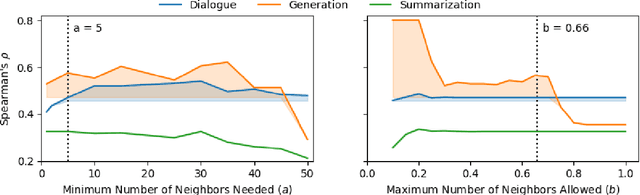

Evaluation is a bottleneck in the development of natural language generation (NLG) models. Automatic metrics such as BLEU rely on references, but for tasks such as open-ended generation, there are no references to draw upon. Although language diversity can be estimated using statistical measures such as perplexity, measuring language quality requires human evaluation. However, because human evaluation at scale is slow and expensive, it is used sparingly; it cannot be used to rapidly iterate on NLG models, in the way BLEU is used for machine translation. To this end, we propose BLEU Neighbors, a nearest neighbors model for estimating language quality by using the BLEU score as a kernel function. On existing datasets for chitchat dialogue and open-ended sentence generation, we find that -- on average -- the quality estimation from a BLEU Neighbors model has a lower mean squared error and higher Spearman correlation with the ground truth than individual human annotators. Despite its simplicity, BLEU Neighbors even outperforms state-of-the-art models on automatically grading essays, including models that have access to a gold-standard reference essay.
Is Your Classifier Actually Biased? Measuring Fairness under Uncertainty with Bernstein Bounds
Apr 26, 2020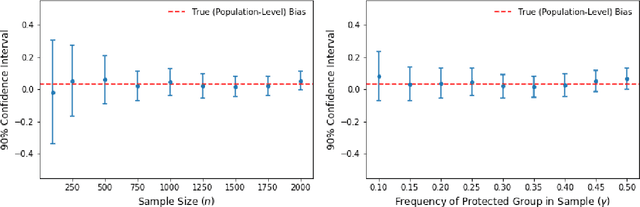
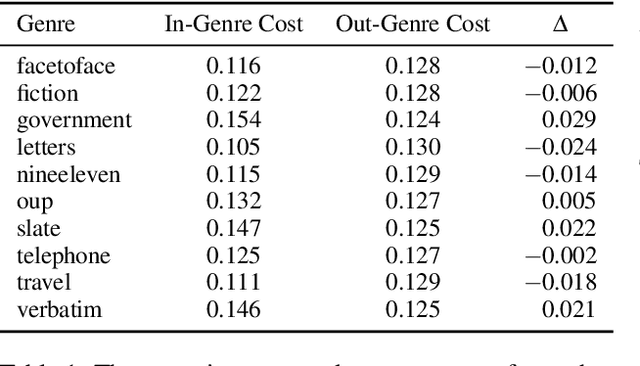
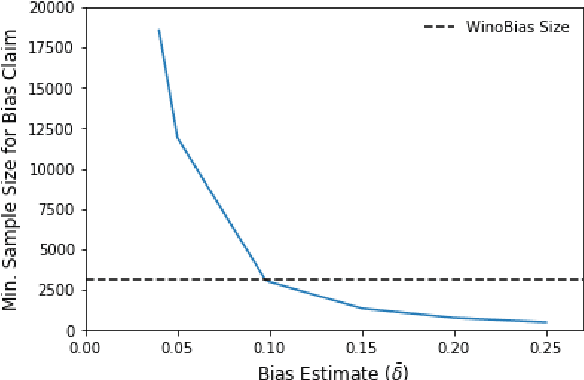
Most NLP datasets are not annotated with protected attributes such as gender, making it difficult to measure classification bias using standard measures of fairness (e.g., equal opportunity). However, manually annotating a large dataset with a protected attribute is slow and expensive. Instead of annotating all the examples, can we annotate a subset of them and use that sample to estimate the bias? While it is possible to do so, the smaller this annotated sample is, the less certain we are that the estimate is close to the true bias. In this work, we propose using Bernstein bounds to represent this uncertainty about the bias estimate as a confidence interval. We provide empirical evidence that a 95% confidence interval derived this way consistently bounds the true bias. In quantifying this uncertainty, our method, which we call Bernstein-bounded unfairness, helps prevent classifiers from being deemed biased or unbiased when there is insufficient evidence to make either claim. Our findings suggest that the datasets currently used to measure specific biases are too small to conclusively identify bias except in the most egregious cases. For example, consider a co-reference resolution system that is 5% more accurate on gender-stereotypical sentences -- to claim it is biased with 95% confidence, we need a bias-specific dataset that is 3.8 times larger than WinoBias, the largest available.
Rotate King to get Queen: Word Relationships as Orthogonal Transformations in Embedding Space
Sep 05, 2019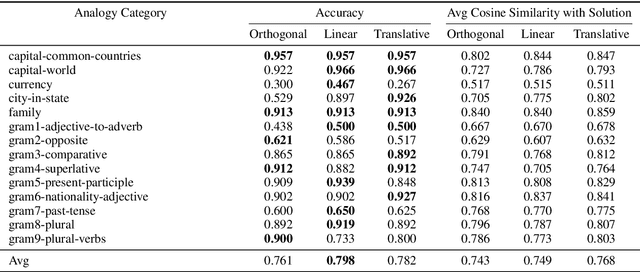
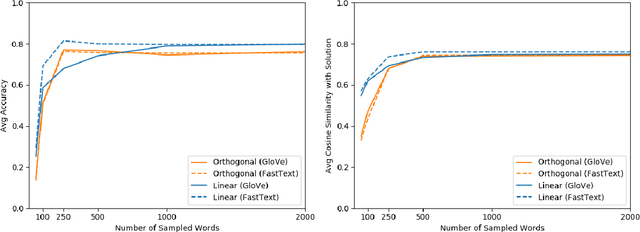
A notable property of word embeddings is that word relationships can exist as linear substructures in the embedding space. For example, $\textit{gender}$ corresponds to $\vec{\textit{woman}} - \vec{\textit{man}}$ and $\vec{\textit{queen}} - \vec{\textit{king}}$. This, in turn, allows word analogies to be solved arithmetically: $\vec{\textit{king}} - \vec{\textit{man}} + \vec{\textit{woman}} \approx \vec{\textit{queen}}$. This property is notable because it suggests that models trained on word embeddings can easily learn such relationships as geometric translations. However, there is no evidence that models $\textit{exclusively}$ represent relationships in this manner. We document an alternative way in which downstream models might learn these relationships: orthogonal and linear transformations. For example, given a translation vector for $\textit{gender}$, we can find an orthogonal matrix $R$, representing a rotation and reflection, such that $R(\vec{\textit{king}}) \approx \vec{\textit{queen}}$ and $R(\vec{\textit{man}}) \approx \vec{\textit{woman}}$. Analogical reasoning using orthogonal transformations is almost as accurate as using vector arithmetic; using linear transformations is more accurate than both. Our findings suggest that these transformations can be as good a representation of word relationships as translation vectors.
How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
Sep 02, 2019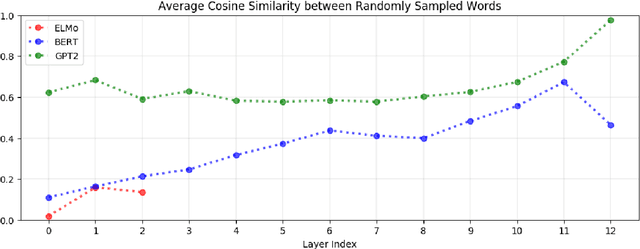
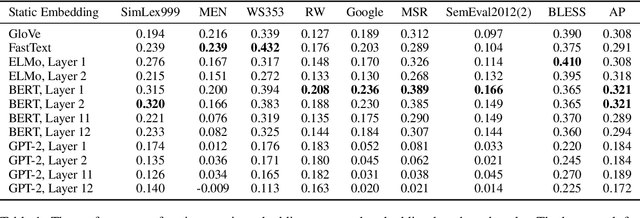
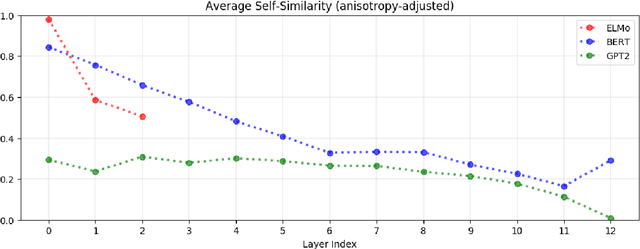
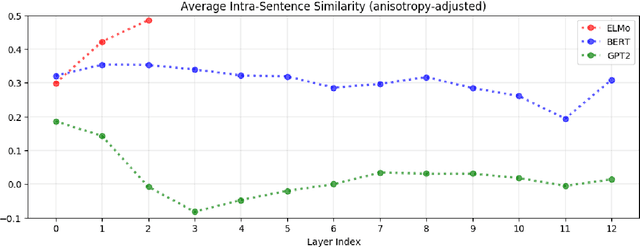
Replacing static word embeddings with contextualized word representations has yielded significant improvements on many NLP tasks. However, just how contextual are the contextualized representations produced by models such as ELMo and BERT? Are there infinitely many context-specific representations for each word, or are words essentially assigned one of a finite number of word-sense representations? For one, we find that the contextualized representations of all words are not isotropic in any layer of the contextualizing model. While representations of the same word in different contexts still have a greater cosine similarity than those of two different words, this self-similarity is much lower in upper layers. This suggests that upper layers of contextualizing models produce more context-specific representations, much like how upper layers of LSTMs produce more task-specific representations. In all layers of ELMo, BERT, and GPT-2, on average, less than 5% of the variance in a word's contextualized representations can be explained by a static embedding for that word, providing some justification for the success of contextualized representations.
Understanding Undesirable Word Embedding Associations
Aug 18, 2019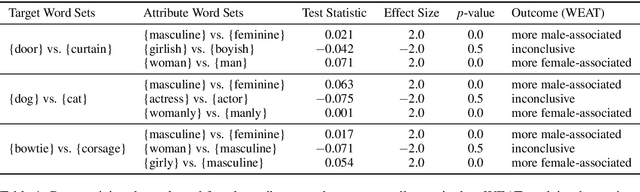
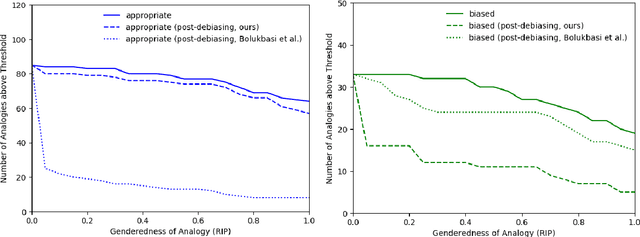
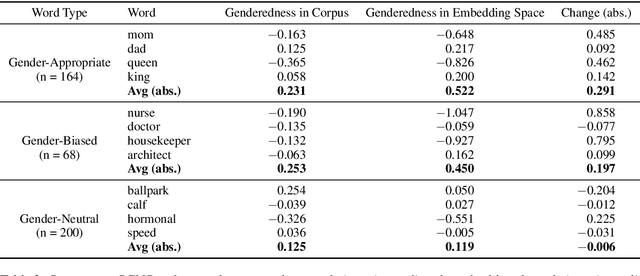
Word embeddings are often criticized for capturing undesirable word associations such as gender stereotypes. However, methods for measuring and removing such biases remain poorly understood. We show that for any embedding model that implicitly does matrix factorization, debiasing vectors post hoc using subspace projection (Bolukbasi et al., 2016) is, under certain conditions, equivalent to training on an unbiased corpus. We also prove that WEAT, the most common association test for word embeddings, systematically overestimates bias. Given that the subspace projection method is provably effective, we use it to derive a new measure of association called the $\textit{relational inner product association}$ (RIPA). Experiments with RIPA reveal that, on average, skipgram with negative sampling (SGNS) does not make most words any more gendered than they are in the training corpus. However, for gender-stereotyped words, SGNS actually amplifies the gender association in the corpus.
Towards Understanding Linear Word Analogies
Oct 27, 2018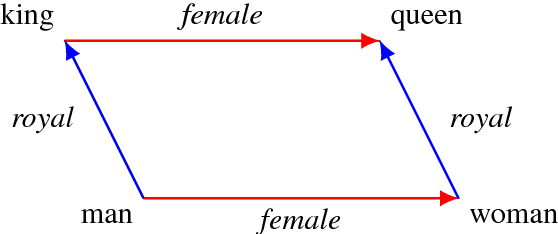
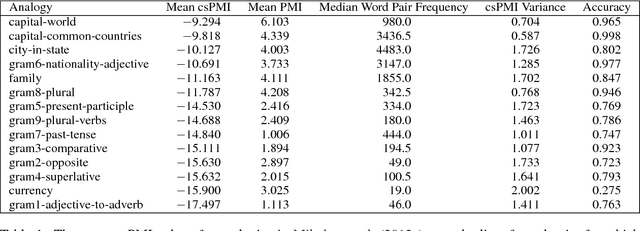
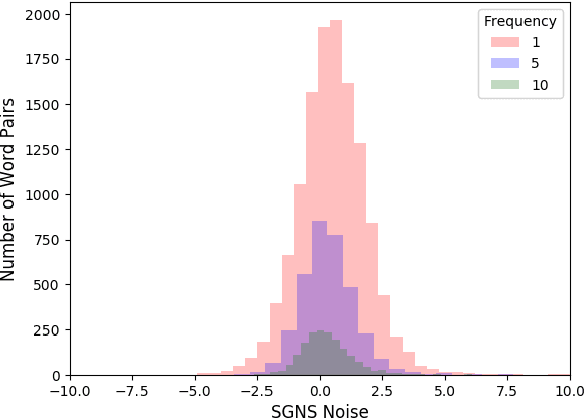
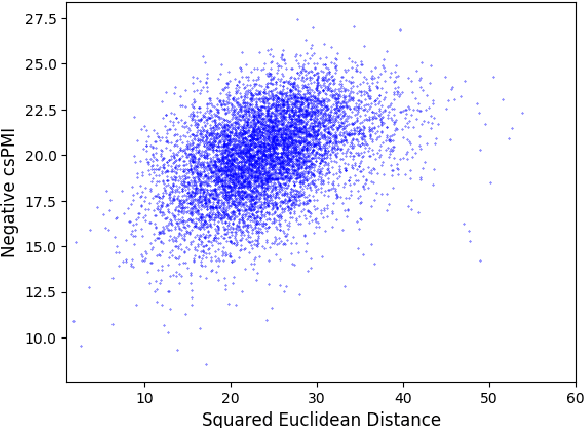
A surprising property of word vectors is that vector algebra can often be used to solve word analogies. However, it is unclear why - and when - linear operators correspond to non-linear embedding models such as skip-gram with negative sampling (SGNS). We provide a rigorous explanation of this phenomenon without making the strong assumptions that past work has made about the vector space and word distribution. Our theory has several implications. Past work has often conjectured that linear structures exist in vector spaces because relations can be represented as ratios; we prove that this holds for SGNS. We provide novel theoretical justification for the addition of SGNS word vectors by showing that it automatically down-weights the more frequent word, as weighting schemes do ad hoc. Lastly, we offer an information theoretic interpretation of Euclidean distance in vector spaces, providing rigorous justification for its use in capturing word dissimilarity.