 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialAI: Benchmarking Socio-Cognitive Abilities in Deep Reinforcement Learning Agents
Jul 06, 2021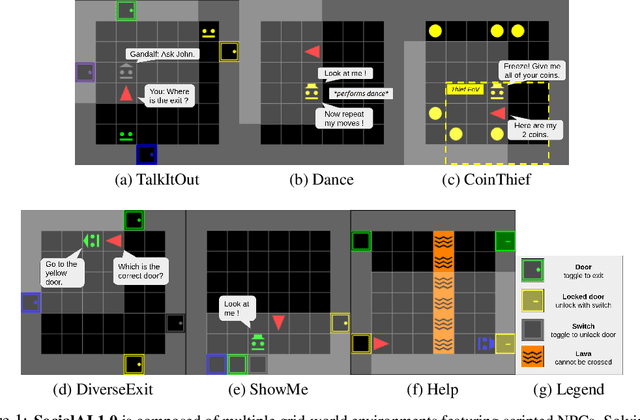

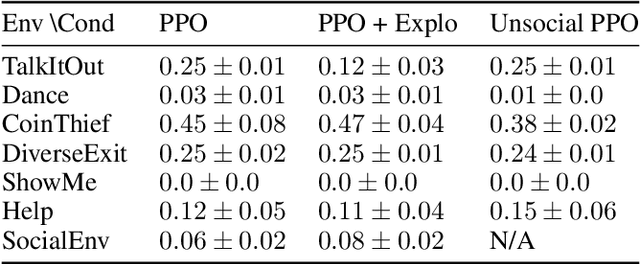
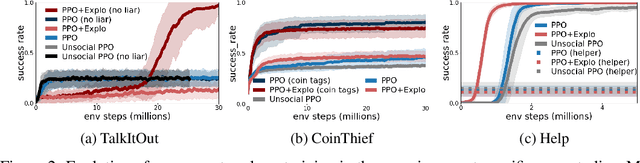
Building embodied autonomous agents capable of participating in social interactions with humans is one of the main challenges in AI. Within the Deep Reinforcement Learning (DRL) field, this objective motivated multiple works on embodied language use. However, current approaches focus on language as a communication tool in very simplified and non-diverse social situations: the "naturalness" of language is reduced to the concept of high vocabulary size and variability. In this paper, we argue that aiming towards human-level AI requires a broader set of key social skills: 1) language use in complex and variable social contexts; 2) beyond language, complex embodied communication in multimodal settings within constantly evolving social worlds. We explain how concepts from cognitive sciences could help AI to draw a roadmap towards human-like intelligence, with a focus on its social dimensions. As a first step, we propose to expand current research to a broader set of core social skills. To do this, we present SocialAI, a benchmark to assess the acquisition of social skills of DRL agents using multiple grid-world environments featuring other (scripted) social agents. We then study the limits of a recent SOTA DRL approach when tested on SocialAI and discuss important next steps towards proficient social agents. Videos and code are available at https://sites.google.com/view/socialai.
Memory Efficient Meta-Learning with Large Images
Jul 02, 2021
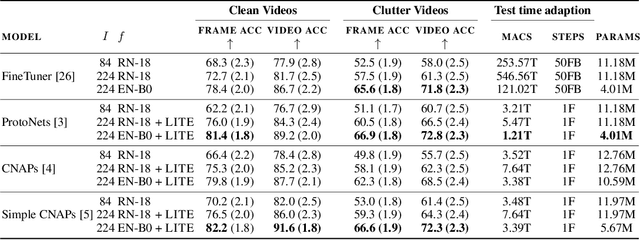
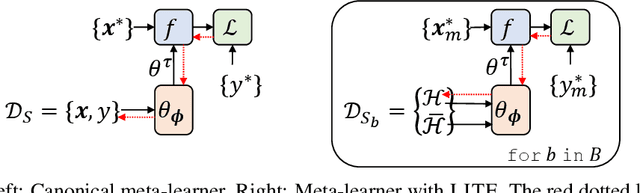
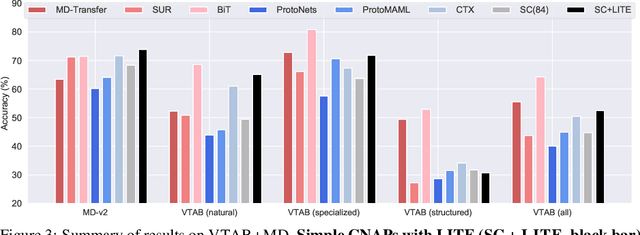
Meta learning approaches to few-shot classification are computationally efficient at test time requiring just a few optimization steps or single forward pass to learn a new task, but they remain highly memory-intensive to train. This limitation arises because a task's entire support set, which can contain up to 1000 images, must be processed before an optimization step can be taken. Harnessing the performance gains offered by large images thus requires either parallelizing the meta-learner across multiple GPUs, which may not be available, or trade-offs between task and image size when memory constraints apply. We improve on both options by proposing LITE, a general and memory efficient episodic training scheme that enables meta-training on large tasks composed of large images on a single GPU. We achieve this by observing that the gradients for a task can be decomposed into a sum of gradients over the task's training images. This enables us to perform a forward pass on a task's entire training set but realize significant memory savings by back-propagating only a random subset of these images which we show is an unbiased approximation of the full gradient. We use LITE to train meta-learners and demonstrate new state-of-the-art accuracy on the real-world ORBIT benchmark and 3 of the 4 parts of the challenging VTAB+MD benchmark relative to leading meta-learners. LITE also enables meta-learners to be competitive with transfer learning approaches but at a fraction of the test-time computational cost, thus serving as a counterpoint to the recent narrative that transfer learning is all you need for few-shot classification.
Grounding Spatio-Temporal Language with Transformers
Jun 16, 2021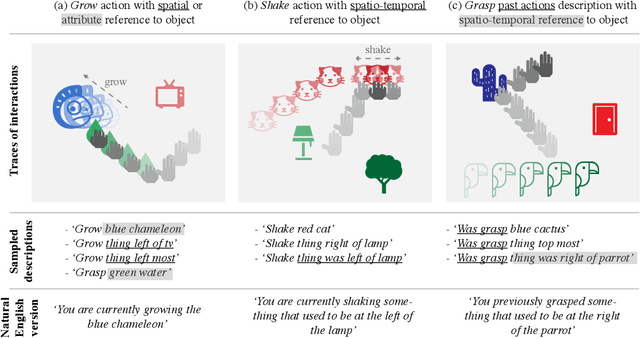
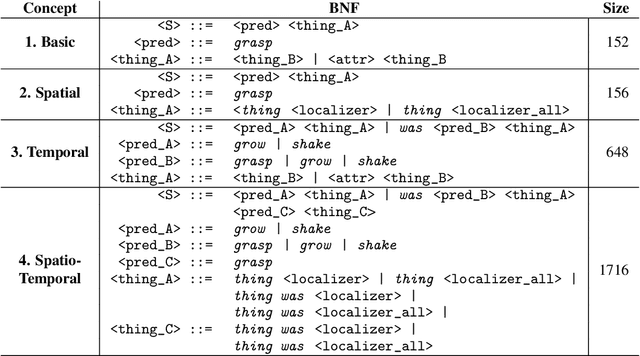
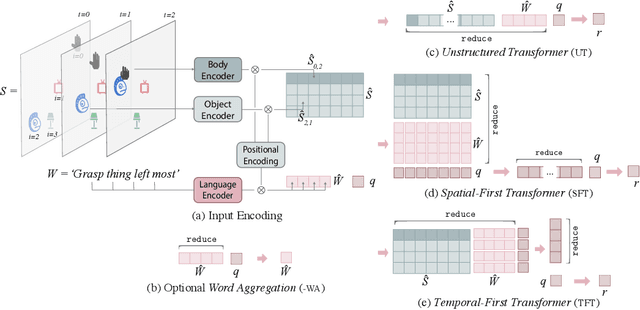
Language is an interface to the outside world. In order for embodied agents to use it, language must be grounded in other, sensorimotor modalities. While there is an extended literature studying how machines can learn grounded language, the topic of how to learn spatio-temporal linguistic concepts is still largely uncharted. To make progress in this direction, we here introduce a novel spatio-temporal language grounding task where the goal is to learn the meaning of spatio-temporal descriptions of behavioral traces of an embodied agent. This is achieved by training a truth function that predicts if a description matches a given history of observations. The descriptions involve time-extended predicates in past and present tense as well as spatio-temporal references to objects in the scene. To study the role of architectural biases in this task, we train several models including multimodal Transformer architectures; the latter implement different attention computations between words and objects across space and time. We test models on two classes of generalization: 1) generalization to randomly held-out sentences; 2) generalization to grammar primitives. We observe that maintaining object identity in the attention computation of our Transformers is instrumental to achieving good performance on generalization overall, and that summarizing object traces in a single token has little influence on performance. We then discuss how this opens new perspectives for language-guided autonomous embodied agents. We also release our code under open-source license as well as pretrained models and datasets to encourage the wider community to build upon and extend our work in the future.
SoftDICE for Imitation Learning: Rethinking Off-policy Distribution Matching
Jun 06, 2021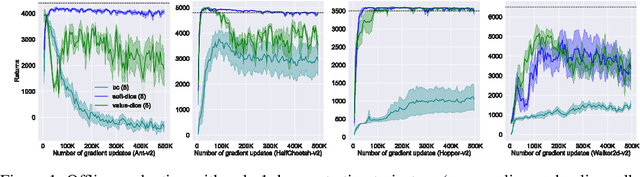
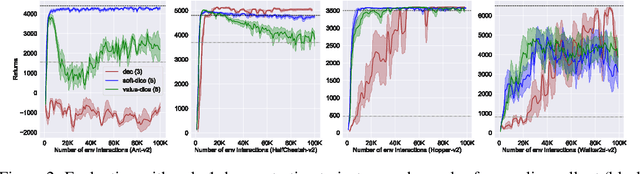
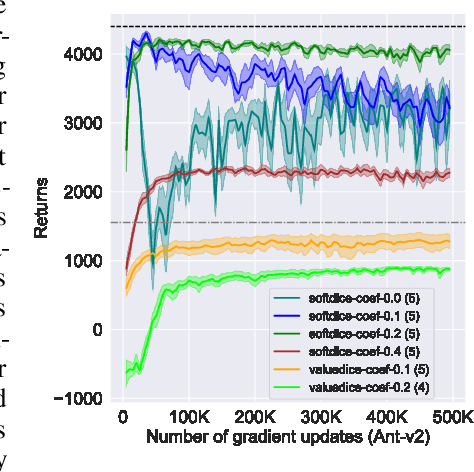
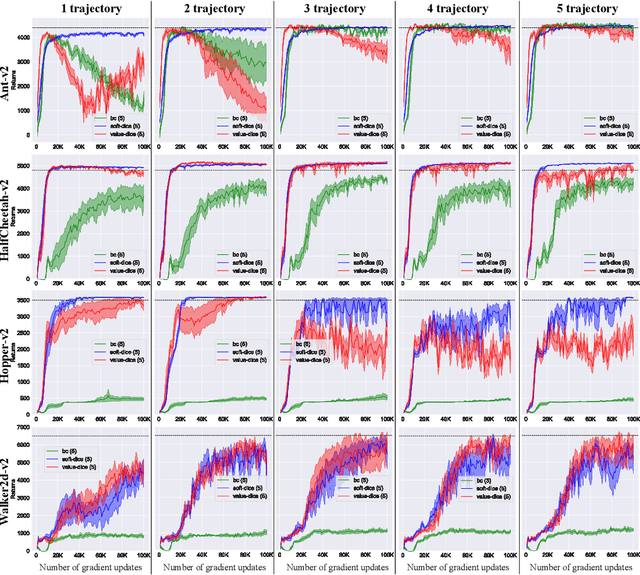
We present SoftDICE, which achieves state-of-the-art performance for imitation learning. SoftDICE fixes several key problems in ValueDICE, an off-policy distribution matching approach for sample-efficient imitation learning. Specifically, the objective of ValueDICE contains logarithms and exponentials of expectations, for which the mini-batch gradient estimate is always biased. Second, ValueDICE regularizes the objective with replay buffer samples when expert demonstrations are limited in number, which however changes the original distribution matching problem. Third, the re-parametrization trick used to derive the off-policy objective relies on an implicit assumption that rarely holds in training. We leverage a novel formulation of distribution matching and consider an entropy-regularized off-policy objective, which yields a completely offline algorithm called SoftDICE. Our empirical results show that SoftDICE recovers the expert policy with only one demonstration trajectory and no further on-policy/off-policy samples. SoftDICE also stably outperforms ValueDICE and other baselines in terms of sample efficiency on Mujoco benchmark tasks.
Navigation Turing Test (NTT): Learning to Evaluate Human-Like Navigation
May 20, 2021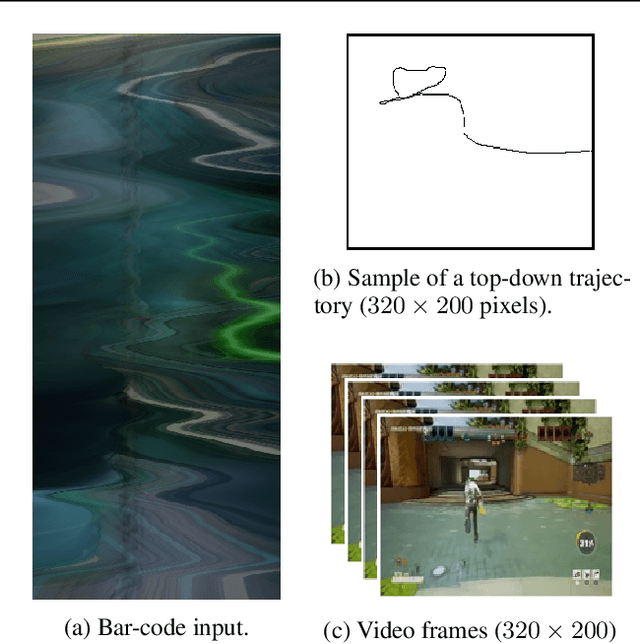
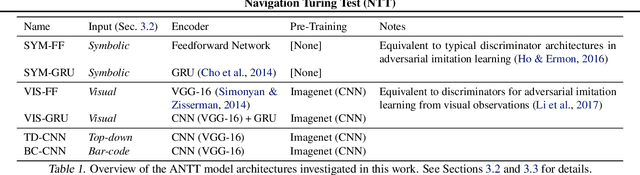
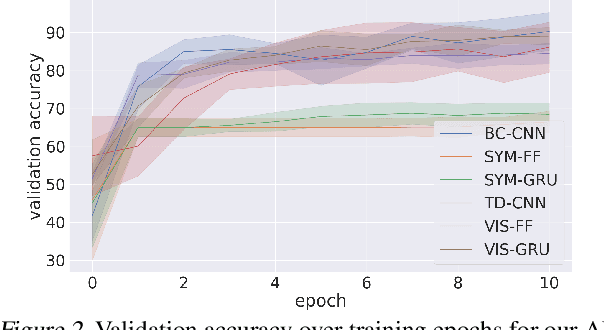
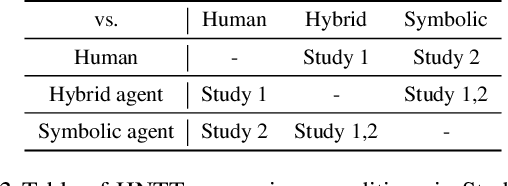
A key challenge on the path to developing agents that learn complex human-like behavior is the need to quickly and accurately quantify human-likeness. While human assessments of such behavior can be highly accurate, speed and scalability are limited. We address these limitations through a novel automated Navigation Turing Test (ANTT) that learns to predict human judgments of human-likeness. We demonstrate the effectiveness of our automated NTT on a navigation task in a complex 3D environment. We investigate six classification models to shed light on the types of architectures best suited to this task, and validate them against data collected through a human NTT. Our best models achieve high accuracy when distinguishing true human and agent behavior. At the same time, we show that predicting finer-grained human assessment of agents' progress towards human-like behavior remains unsolved. Our work takes an important step towards agents that more effectively learn complex human-like behavior.
SocialAI 0.1: Towards a Benchmark to Stimulate Research on Socio-Cognitive Abilities in Deep Reinforcement Learning Agents
Apr 27, 2021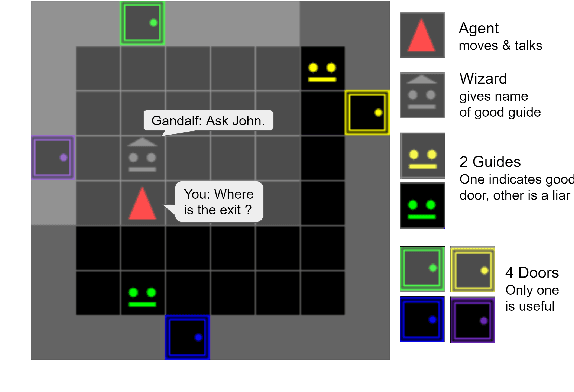

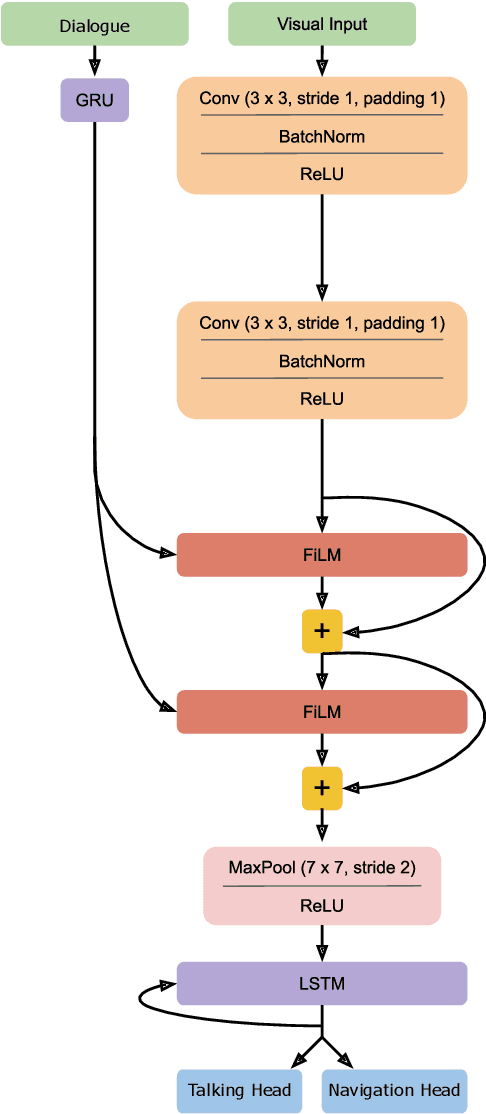
Building embodied autonomous agents capable of participating in social interactions with humans is one of the main challenges in AI. This problem motivated many research directions on embodied language use. Current approaches focus on language as a communication tool in very simplified and non diverse social situations: the "naturalness" of language is reduced to the concept of high vocabulary size and variability. In this paper, we argue that aiming towards human-level AI requires a broader set of key social skills: 1) language use in complex and variable social contexts; 2) beyond language, complex embodied communication in multimodal settings within constantly evolving social worlds. In this work we explain how concepts from cognitive sciences could help AI to draw a roadmap towards human-like intelligence, with a focus on its social dimensions. We then study the limits of a recent SOTA Deep RL approach when tested on a first grid-world environment from the upcoming SocialAI, a benchmark to assess the social skills of Deep RL agents. Videos and code are available at https://sites.google.com/view/socialai01 .
ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition
Apr 09, 2021
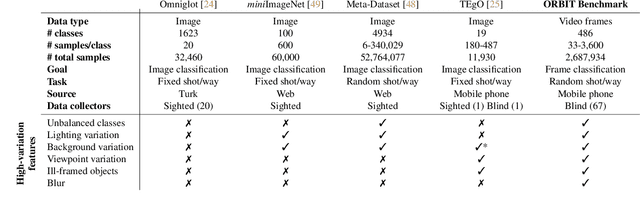
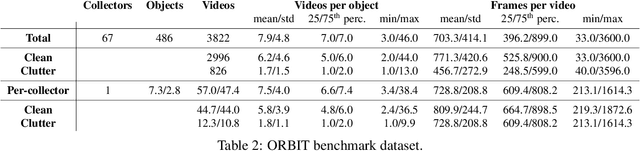
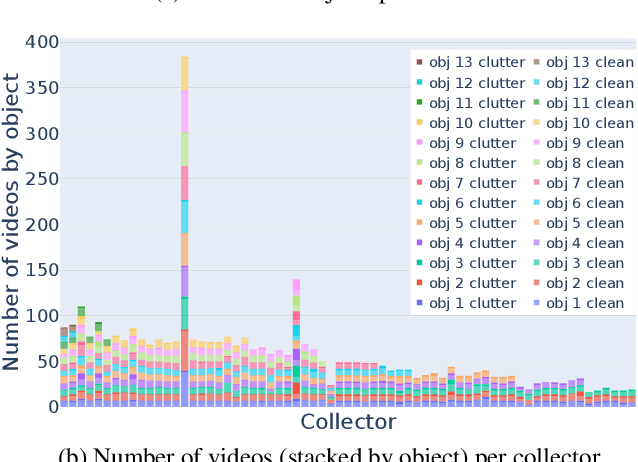
Object recognition has made great advances in the last decade, but predominately still relies on many high-quality training examples per object category. In contrast, learning new objects from only a few examples could enable many impactful applications from robotics to user personalization. Most few-shot learning research, however, has been driven by benchmark datasets that lack the high variation that these applications will face when deployed in the real-world. To close this gap, we present the ORBIT dataset and benchmark, grounded in a real-world application of teachable object recognizers for people who are blind/low vision. The dataset contains 3,822 videos of 486 objects recorded by people who are blind/low-vision on their mobile phones, and the benchmark reflects a realistic, highly challenging recognition problem, providing a rich playground to drive research in robustness to few-shot, high-variation conditions. We set the first state-of-the-art on the benchmark and show that there is massive scope for further innovation, holding the potential to impact a broad range of real-world vision applications including tools for the blind/low-vision community. The dataset is available at https://bit.ly/2OyElCj and the code to run the benchmark at https://bit.ly/39YgiUW.
TeachMyAgent: a Benchmark for Automatic Curriculum Learning in Deep RL
Mar 17, 2021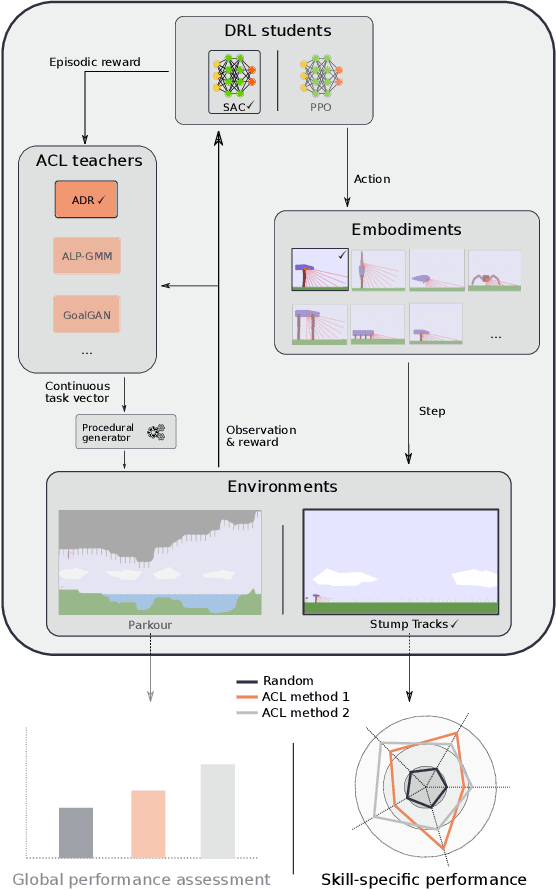

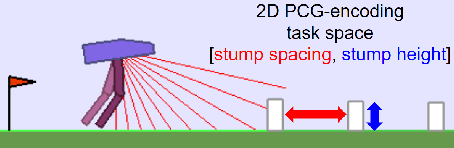
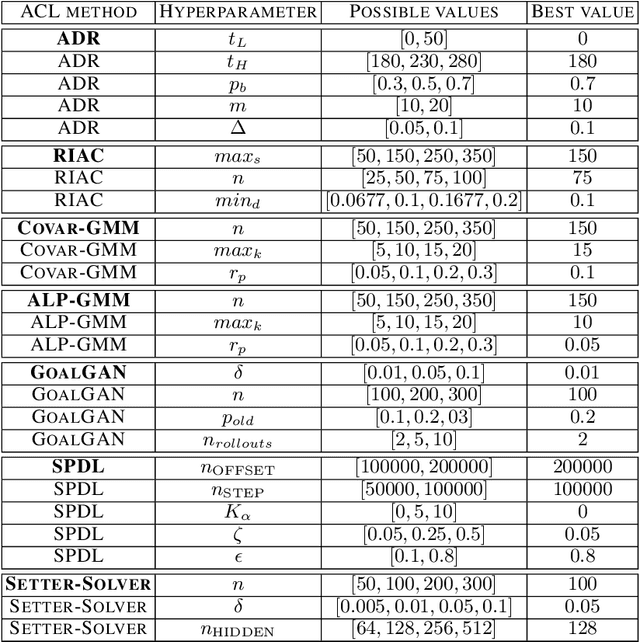
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python package available at https://github.com/flowersteam/TeachMyAgent.
Evaluating the Robustness of Collaborative Agents
Jan 14, 2021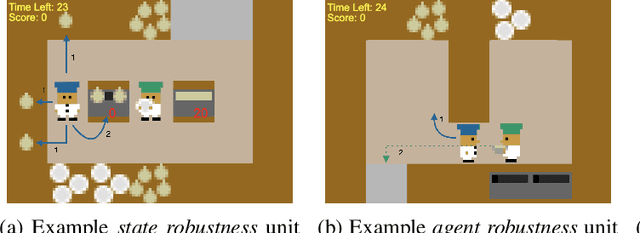
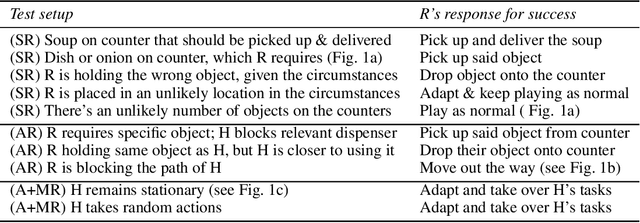


In order for agents trained by deep reinforcement learning to work alongside humans in realistic settings, we will need to ensure that the agents are \emph{robust}. Since the real world is very diverse, and human behavior often changes in response to agent deployment, the agent will likely encounter novel situations that have never been seen during training. This results in an evaluation challenge: if we cannot rely on the average training or validation reward as a metric, then how can we effectively evaluate robustness? We take inspiration from the practice of \emph{unit testing} in software engineering. Specifically, we suggest that when designing AI agents that collaborate with humans, designers should search for potential edge cases in \emph{possible partner behavior} and \emph{possible states encountered}, and write tests which check that the behavior of the agent in these edge cases is reasonable. We apply this methodology to build a suite of unit tests for the Overcooked-AI environment, and use this test suite to evaluate three proposals for improving robustness. We find that the test suite provides significant insight into the effects of these proposals that were generally not revealed by looking solely at the average validation reward.
Deep Interactive Bayesian Reinforcement Learning via Meta-Learning
Jan 11, 2021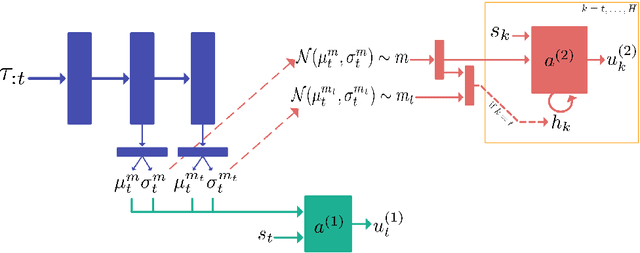
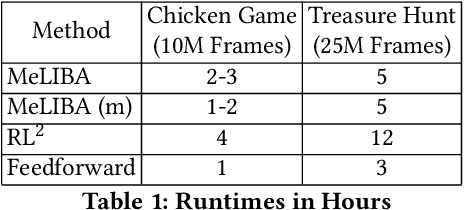
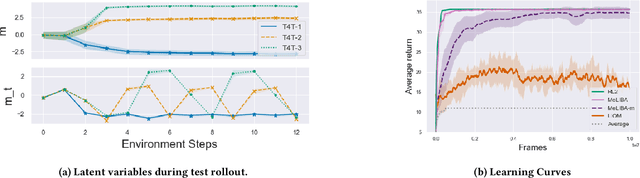
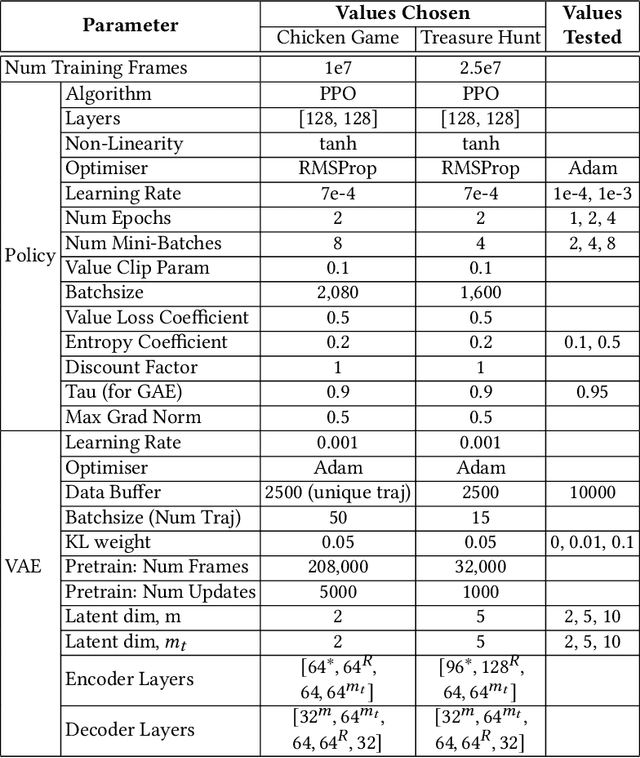
Agents that interact with other agents often do not know a priori what the other agents' strategies are, but have to maximise their own online return while interacting with and learning about others. The optimal adaptive behaviour under uncertainty over the other agents' strategies w.r.t. some prior can in principle be computed using the Interactive Bayesian Reinforcement Learning framework. Unfortunately, doing so is intractable in most settings, and existing approximation methods are restricted to small tasks. To overcome this, we propose to meta-learn approximate belief inference and Bayes-optimal behaviour for a given prior. To model beliefs over other agents, we combine sequential and hierarchical Variational Auto-Encoders, and meta-train this inference model alongside the policy. We show empirically that our approach outperforms existing methods that use a model-free approach, sample from the approximate posterior, maintain memory-free models of others, or do not fully utilise the known structure of the environment.