 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-Level Fluency Evaluation: References Help, But Can Be Spared!
Sep 24, 2018

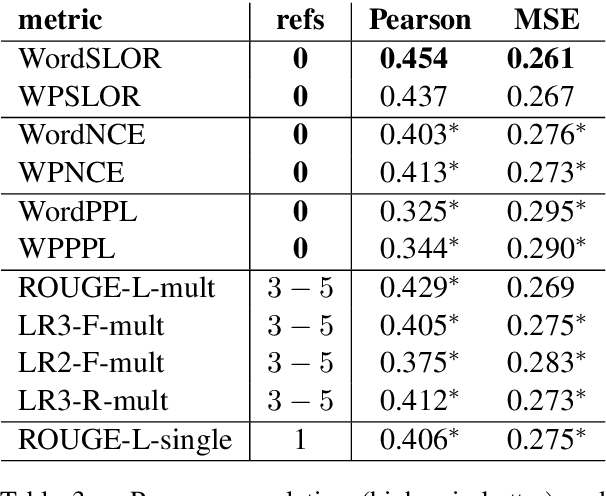
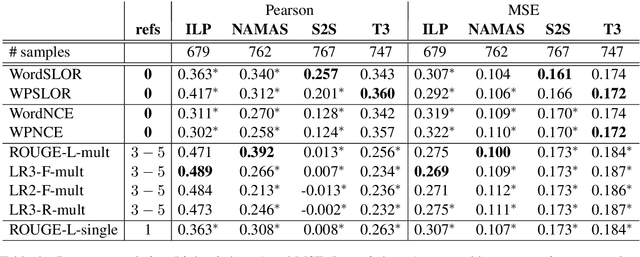
Motivated by recent findings on the probabilistic modeling of acceptability judgments, we propose syntactic log-odds ratio (SLOR), a normalized language model score, as a metric for referenceless fluency evaluation of natural language generation output at the sentence level. We further introduce WPSLOR, a novel WordPiece-based version, which harnesses a more compact language model. Even though word-overlap metrics like ROUGE are computed with the help of hand-written references, our referenceless methods obtain a significantly higher correlation with human fluency scores on a benchmark dataset of compressed sentences. Finally, we present ROUGE-LM, a reference-based metric which is a natural extension of WPSLOR to the case of available references. We show that ROUGE-LM yields a significantly higher correlation with human judgments than all baseline metrics, including WPSLOR on its own.
Evaluating Word Embeddings in Multi-label Classification Using Fine-grained Name Typing
Jul 18, 2018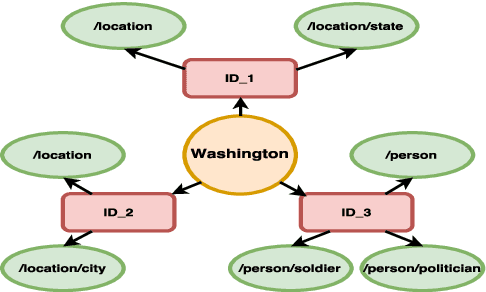
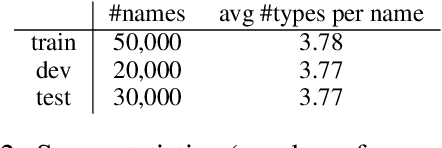
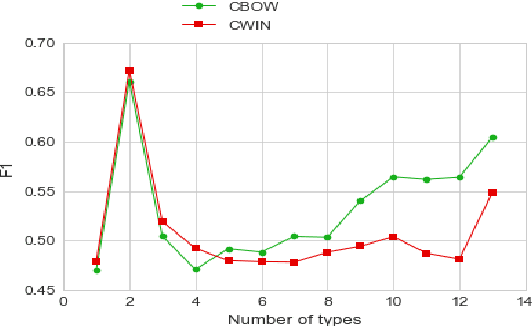
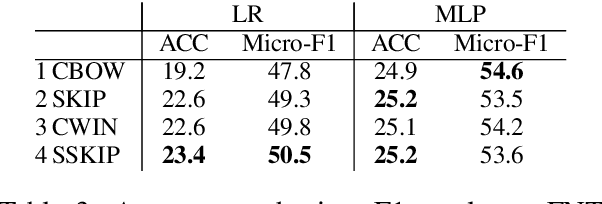
Embedding models typically associate each word with a single real-valued vector, representing its different properties. Evaluation methods, therefore, need to analyze the accuracy and completeness of these properties in embeddings. This requires fine-grained analysis of embedding subspaces. Multi-label classification is an appropriate way to do so. We propose a new evaluation method for word embeddings based on multi-label classification given a word embedding. The task we use is fine-grained name typing: given a large corpus, find all types that a name can refer to based on the name embedding. Given the scale of entities in knowledge bases, we can build datasets for this task that are complementary to the current embedding evaluation datasets in: they are very large, contain fine-grained classes, and allow the direct evaluation of embeddings without confounding factors like sentence context
Lost in Translation: Analysis of Information Loss During Machine Translation Between Polysynthetic and Fusional Languages
Jul 01, 2018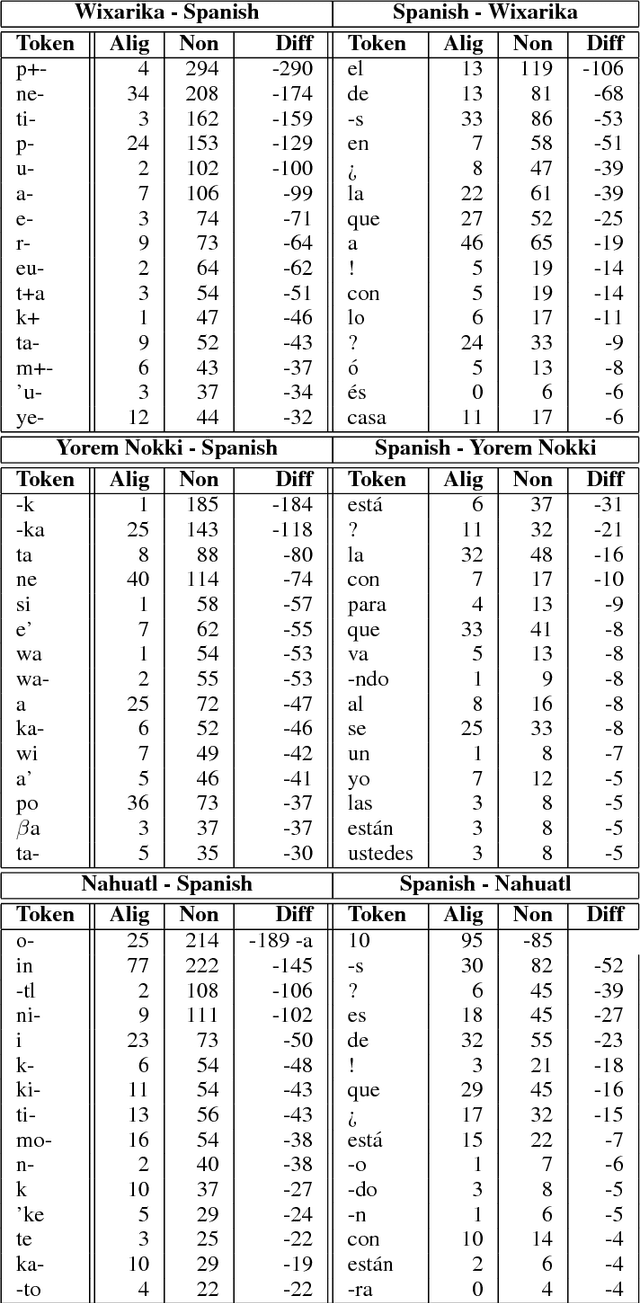

Machine translation from polysynthetic to fusional languages is a challenging task, which gets further complicated by the limited amount of parallel text available. Thus, translation performance is far from the state of the art for high-resource and more intensively studied language pairs. To shed light on the phenomena which hamper automatic translation to and from polysynthetic languages, we study translations from three low-resource, polysynthetic languages (Nahuatl, Wixarika and Yorem Nokki) into Spanish and vice versa. Doing so, we find that in a morpheme-to-morpheme alignment an important amount of information contained in polysynthetic morphemes has no Spanish counterpart, and its translation is often omitted. We further conduct a qualitative analysis and, thus, identify morpheme types that are commonly hard to align or ignored in the translation process.
Fortification of Neural Morphological Segmentation Models for Polysynthetic Minimal-Resource Languages
Apr 17, 2018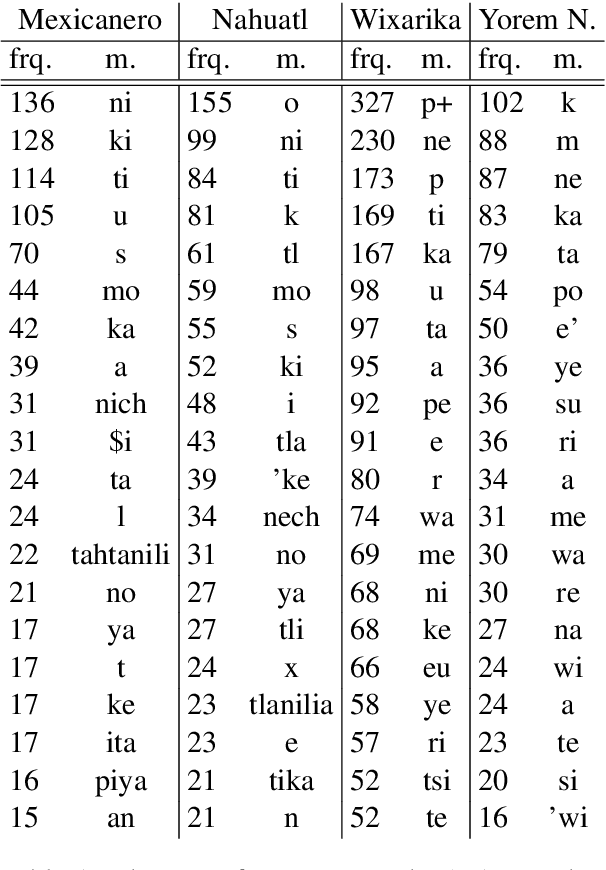
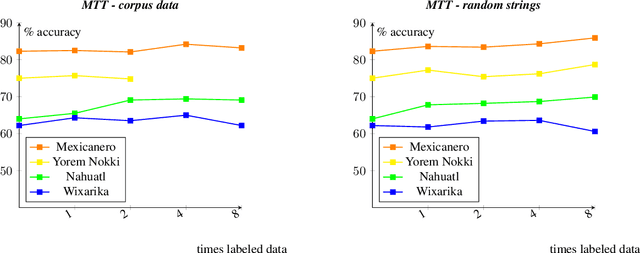
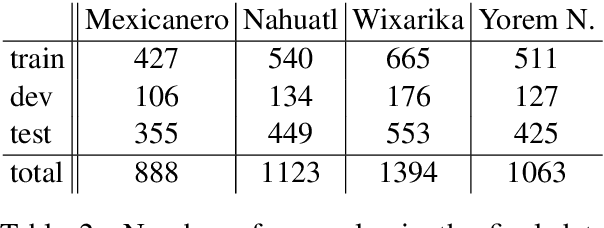
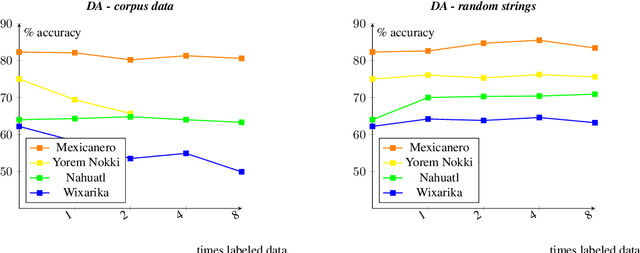
Morphological segmentation for polysynthetic languages is challenging, because a word may consist of many individual morphemes and training data can be extremely scarce. Since neural sequence-to-sequence (seq2seq) models define the state of the art for morphological segmentation in high-resource settings and for (mostly) European languages, we first show that they also obtain competitive performance for Mexican polysynthetic languages in minimal-resource settings. We then propose two novel multi-task training approaches -one with, one without need for external unlabeled resources-, and two corresponding data augmentation methods, improving over the neural baseline for all languages. Finally, we explore cross-lingual transfer as a third way to fortify our neural model and show that we can train one single multi-lingual model for related languages while maintaining comparable or even improved performance, thus reducing the amount of parameters by close to 75%. We provide our morphological segmentation datasets for Mexicanero, Nahuatl, Wixarika and Yorem Nokki for future research.
Unlabeled Data for Morphological Generation With Character-Based Sequence-to-Sequence Models
Jul 21, 2017
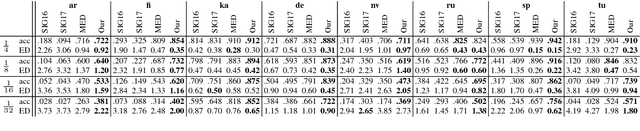
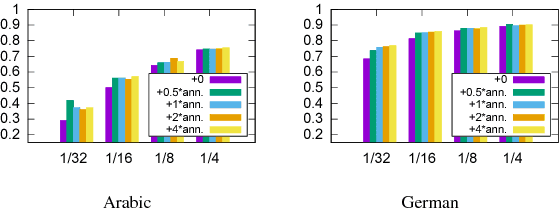
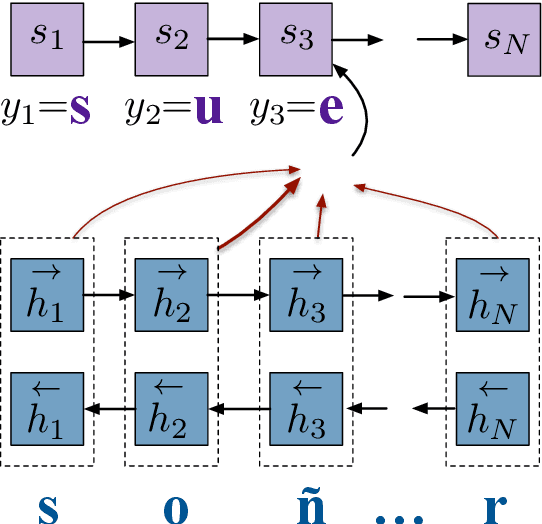
We present a semi-supervised way of training a character-based encoder-decoder recurrent neural network for morphological reinflection, the task of generating one inflected word form from another. This is achieved by using unlabeled tokens or random strings as training data for an autoencoding task, adapting a network for morphological reinflection, and performing multi-task training. We thus use limited labeled data more effectively, obtaining up to 9.9% improvement over state-of-the-art baselines for 8 different languages.
One-Shot Neural Cross-Lingual Transfer for Paradigm Completion
Mar 31, 2017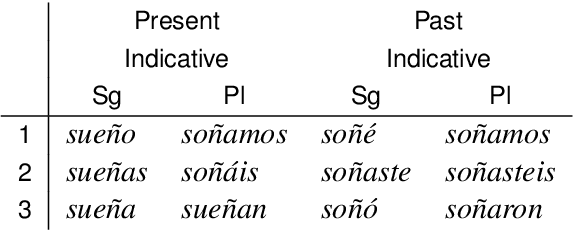

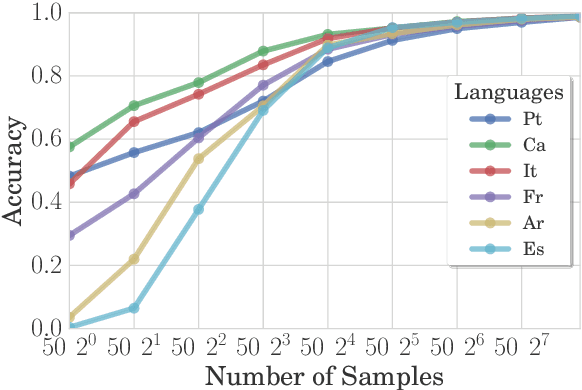
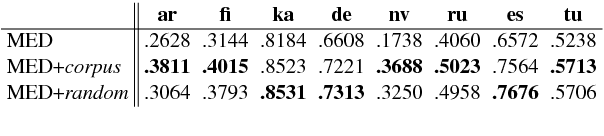
We present a novel cross-lingual transfer method for paradigm completion, the task of mapping a lemma to its inflected forms, using a neural encoder-decoder model, the state of the art for the monolingual task. We use labeled data from a high-resource language to increase performance on a low-resource language. In experiments on 21 language pairs from four different language families, we obtain up to 58% higher accuracy than without transfer and show that even zero-shot and one-shot learning are possible. We further find that the degree of language relatedness strongly influences the ability to transfer morphological knowledge.
Comparative Study of CNN and RNN for Natural Language Processing
Feb 07, 2017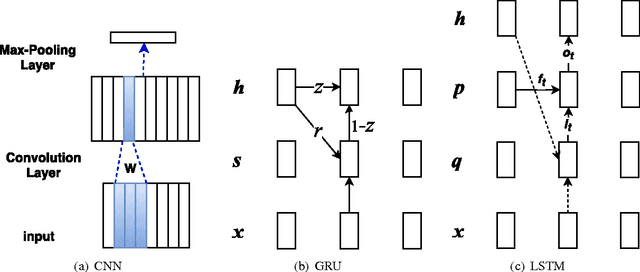
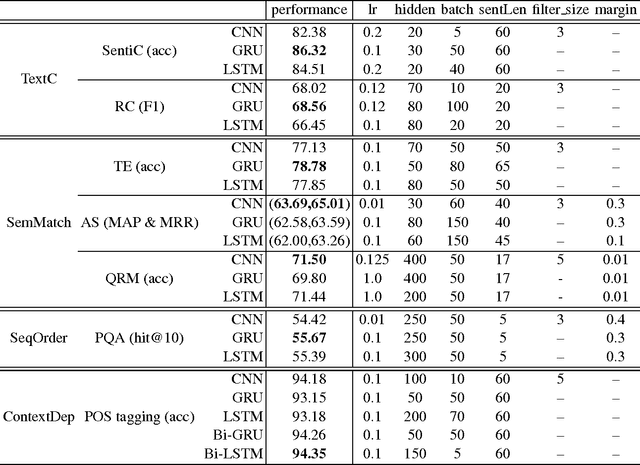

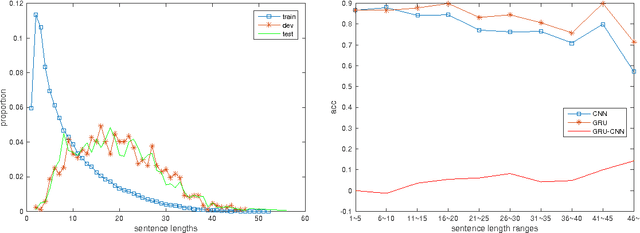
Deep neural networks (DNN) have revolutionized the field of natural language processing (NLP). Convolutional neural network (CNN) and recurrent neural network (RNN), the two main types of DNN architectures, are widely explored to handle various NLP tasks. CNN is supposed to be good at extracting position-invariant features and RNN at modeling units in sequence. The state of the art on many NLP tasks often switches due to the battle between CNNs and RNNs. This work is the first systematic comparison of CNN and RNN on a wide range of representative NLP tasks, aiming to give basic guidance for DNN selection.
Neural Multi-Source Morphological Reinflection
Jan 22, 2017



We explore the task of multi-source morphological reinflection, which generalizes the standard, single-source version. The input consists of (i) a target tag and (ii) multiple pairs of source form and source tag for a lemma. The motivation is that it is beneficial to have access to more than one source form since different source forms can provide complementary information, e.g., different stems. We further present a novel extension to the encoder- decoder recurrent neural architecture, consisting of multiple encoders, to better solve the task. We show that our new architecture outperforms single-source reinflection models and publish our dataset for multi-source morphological reinflection to facilitate future research.
Single-Model Encoder-Decoder with Explicit Morphological Representation for Reinflection
Jun 02, 2016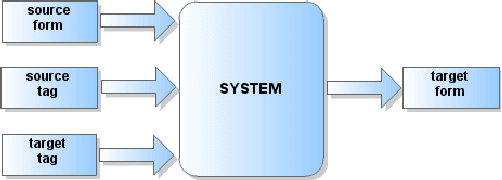



Morphological reinflection is the task of generating a target form given a source form, a source tag and a target tag. We propose a new way of modeling this task with neural encoder-decoder models. Our approach reduces the amount of required training data for this architecture and achieves state-of-the-art results, making encoder-decoder models applicable to morphological reinflection even for low-resource languages. We further present a new automatic correction method for the outputs based on edit trees.