 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Node Features for Graph Neural Networks
Nov 20, 2019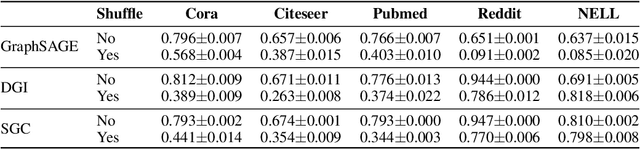
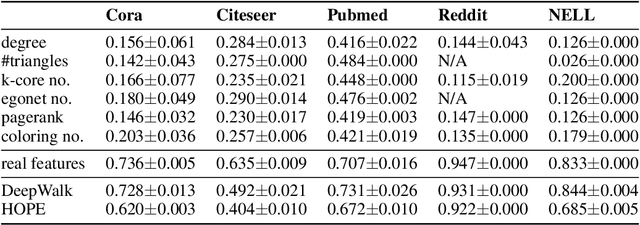
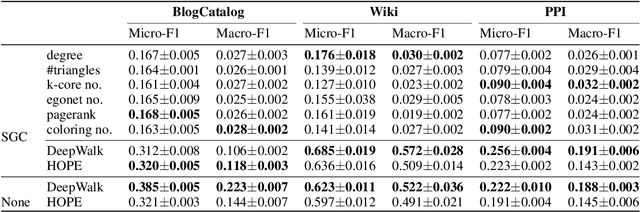
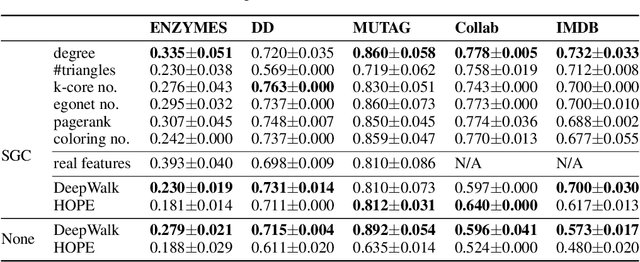
Graph neural network (GNN) is a deep model for graph representation learning. One advantage of graph neural network is its ability to incorporate node features into the learning process. However, this prevents graph neural network from being applied into featureless graphs. In this paper, we first analyze the effects of node features on the performance of graph neural network. We show that GNNs work well if there is a strong correlation between node features and node labels. Based on these results, we propose new feature initialization methods that allows to apply graph neural network to non-attributed graphs. Our experimental results show that the artificial features are highly competitive with real features.
Aligning Multilingual Word Embeddings for Cross-Modal Retrieval Task
Oct 08, 2019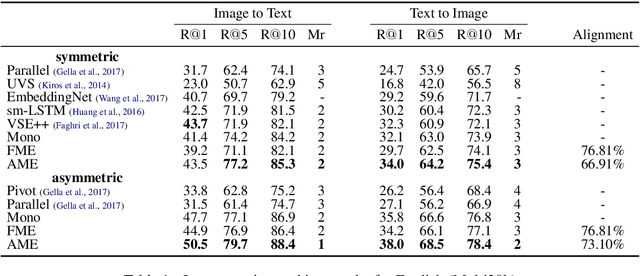
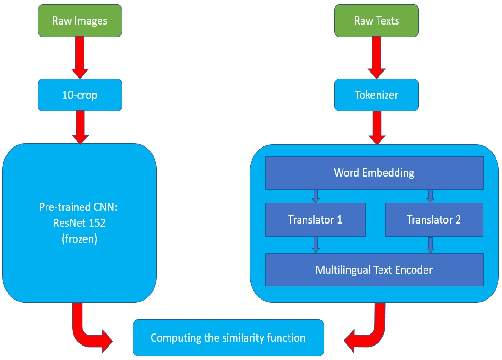
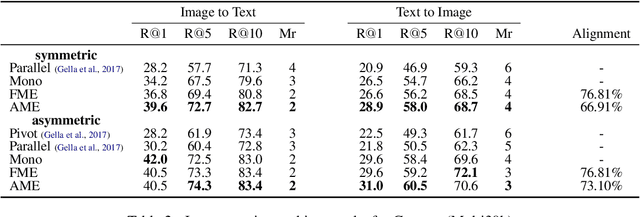
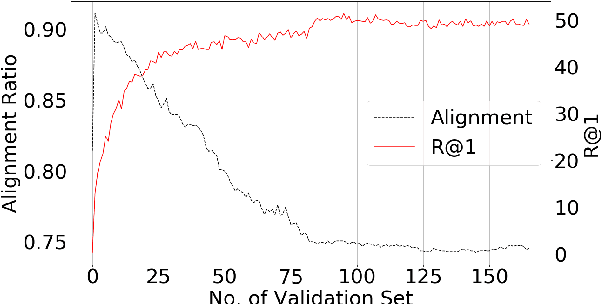
In this paper, we propose a new approach to learn multimodal multilingual embeddings for matching images and their relevant captions in two languages. We combine two existing objective functions to make images and captions close in a joint embedding space while adapting the alignment of word embeddings between existing languages in our model. We show that our approach enables better generalization, achieving state-of-the-art performance in text-to-image and image-to-text retrieval task, and caption-caption similarity task. Two multimodal multilingual datasets are used for evaluation: Multi30k with German and English captions and Microsoft-COCO with English and Japanese captions.
Parallel Computation of Graph Embeddings
Sep 06, 2019
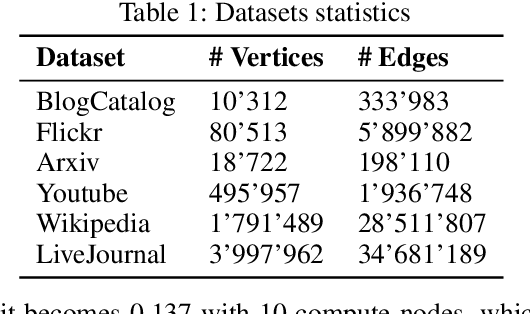
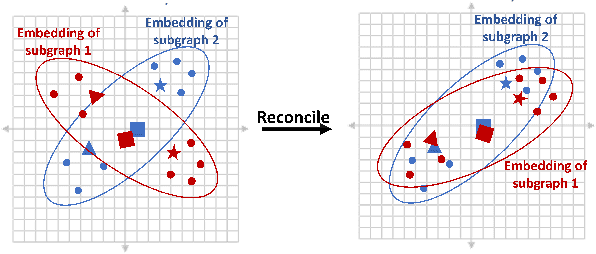
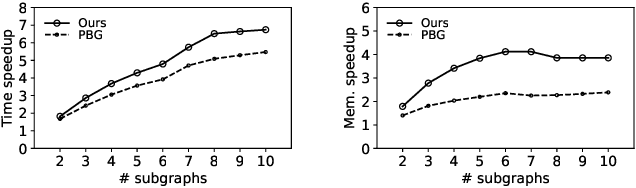
Graph embedding aims at learning a vector-based representation of vertices that incorporates the structure of the graph. This representation then enables inference of graph properties. Existing graph embedding techniques, however, do not scale well to large graphs. We therefore propose a framework for parallel computation of a graph embedding using a cluster of compute nodes with resource constraints. We show how to distribute any existing embedding technique by first splitting a graph for any given set of constrained compute nodes and then reconciling the embedding spaces derived for these subgraphs. We also propose a new way to evaluate the quality of graph embeddings that is independent of a specific inference task. Based thereon, we give a formal bound on the difference between the embeddings derived by centralised and parallel computation. Experimental results illustrate that our approach for parallel computation scales well, while largely maintaining the embedding quality.
SciLens: Evaluating the Quality of Scientific News Articles Using Social Media and Scientific Literature Indicators
Mar 13, 2019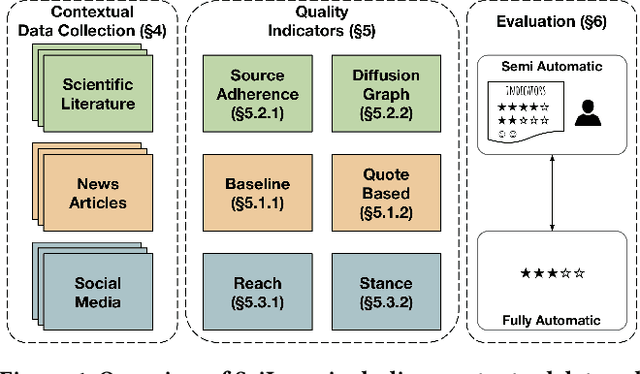

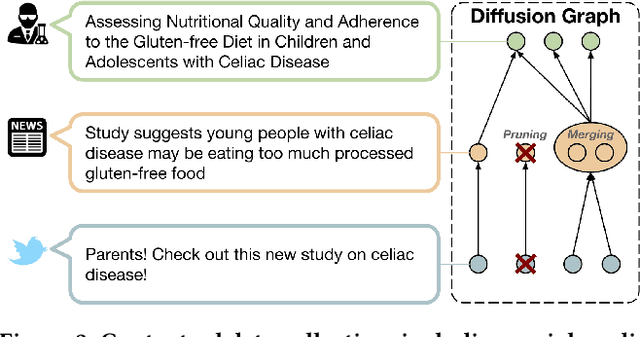

This paper describes, develops, and validates SciLens, a method to evaluate the quality of scientific news articles. The starting point for our work are structured methodologies that define a series of quality aspects for manually evaluating news. Based on these aspects, we describe a series of indicators of news quality. According to our experiments, these indicators help non-experts evaluate more accurately the quality of a scientific news article, compared to non-experts that do not have access to these indicators. Furthermore, SciLens can also be used to produce a completely automated quality score for an article, which agrees more with expert evaluators than manual evaluations done by non-experts. One of the main elements of SciLens is the focus on both content and context of articles, where context is provided by (1) explicit and implicit references on the article to scientific literature, and (2) reactions in social media referencing the article. We show that both contextual elements can be valuable sources of information for determining article quality. The validation of SciLens, done through a combination of expert and non-expert annotation, demonstrates its effectiveness for both semi-automatic and automatic quality evaluation of scientific news.
Cluster-Based Active Learning
Dec 31, 2018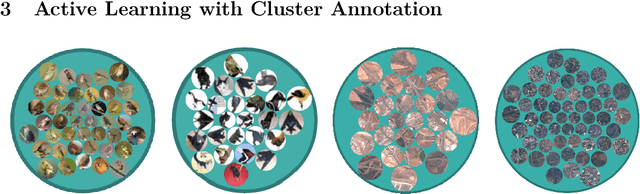
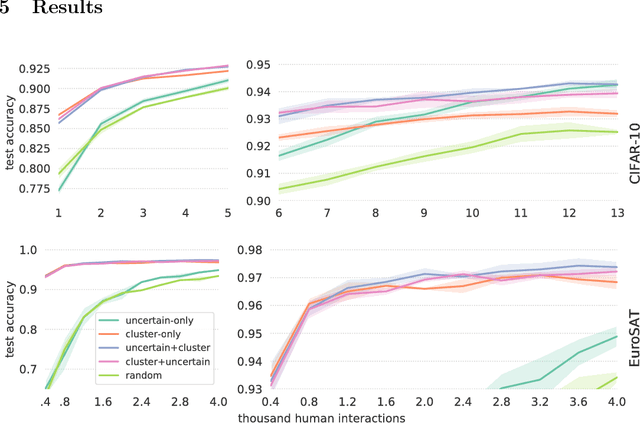
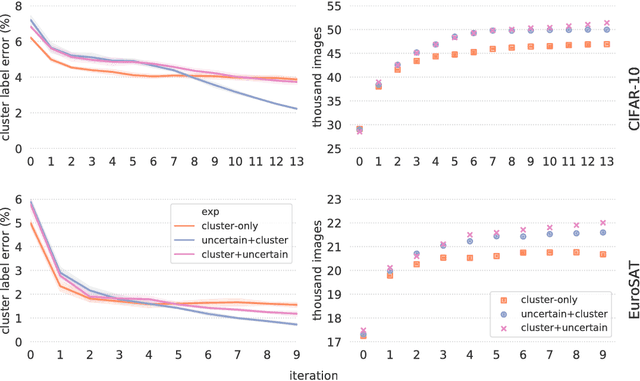
In this work, we introduce Cluster-Based Active Learning, a novel framework that employs clustering to boost active learning by reducing the number of human interactions required to train deep neural networks. Instead of annotating single samples individually, humans can also label clusters, producing a higher number of annotated samples with the cost of a small label error. Our experiments show that the proposed framework requires 82% and 87% less human interactions for CIFAR-10 and EuroSAT datasets respectively when compared with the fully-supervised training while maintaining similar performance on the test set.
Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning
Jun 29, 2018
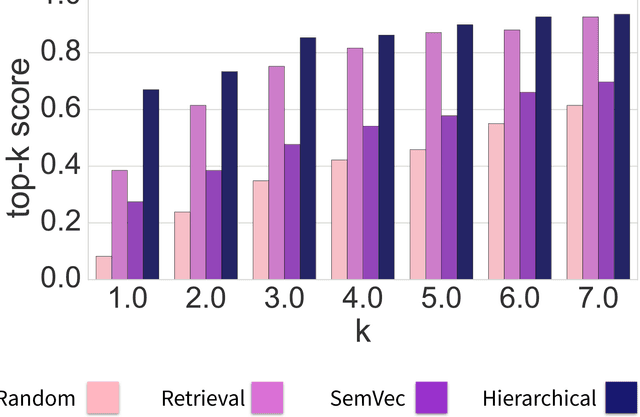
Privacy policies are the primary channel through which companies inform users about their data collection and sharing practices. These policies are often long and difficult to comprehend. Short notices based on information extracted from privacy policies have been shown to be useful but face a significant scalability hurdle, given the number of policies and their evolution over time. Companies, users, researchers, and regulators still lack usable and scalable tools to cope with the breadth and depth of privacy policies. To address these hurdles, we propose an automated framework for privacy policy analysis (Polisis). It enables scalable, dynamic, and multi-dimensional queries on natural language privacy policies. At the core of Polisis is a privacy-centric language model, built with 130K privacy policies, and a novel hierarchy of neural-network classifiers that accounts for both high-level aspects and fine-grained details of privacy practices. We demonstrate Polisis' modularity and utility with two applications supporting structured and free-form querying. The structured querying application is the automated assignment of privacy icons from privacy policies. With Polisis, we can achieve an accuracy of 88.4% on this task. The second application, PriBot, is the first freeform question-answering system for privacy policies. We show that PriBot can produce a correct answer among its top-3 results for 82% of the test questions. Using an MTurk user study with 700 participants, we show that at least one of PriBot's top-3 answers is relevant to users for 89% of the test questions.
Taxonomy Induction using Hypernym Subsequences
Sep 14, 2017

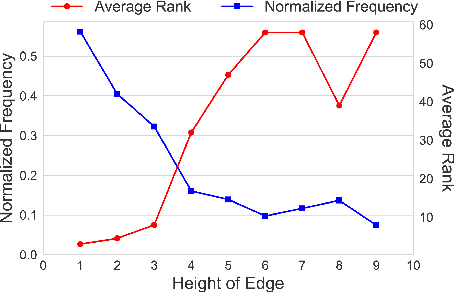
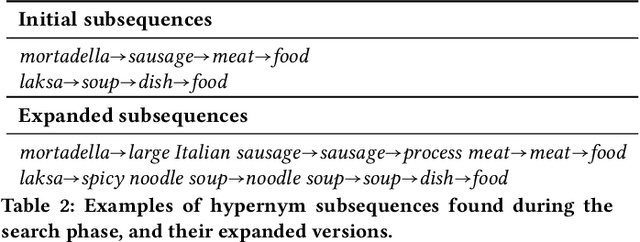
We propose a novel, semi-supervised approach towards domain taxonomy induction from an input vocabulary of seed terms. Unlike all previous approaches, which typically extract direct hypernym edges for terms, our approach utilizes a novel probabilistic framework to extract hypernym subsequences. Taxonomy induction from extracted subsequences is cast as an instance of the minimumcost flow problem on a carefully designed directed graph. Through experiments, we demonstrate that our approach outperforms stateof- the-art taxonomy induction approaches across four languages. Importantly, we also show that our approach is robust to the presence of noise in the input vocabulary. To the best of our knowledge, no previous approaches have been empirically proven to manifest noise-robustness in the input vocabulary.
280 Birds with One Stone: Inducing Multilingual Taxonomies from Wikipedia using Character-level Classification
Sep 12, 2017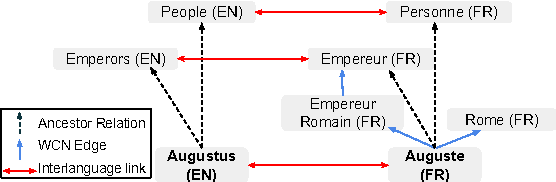

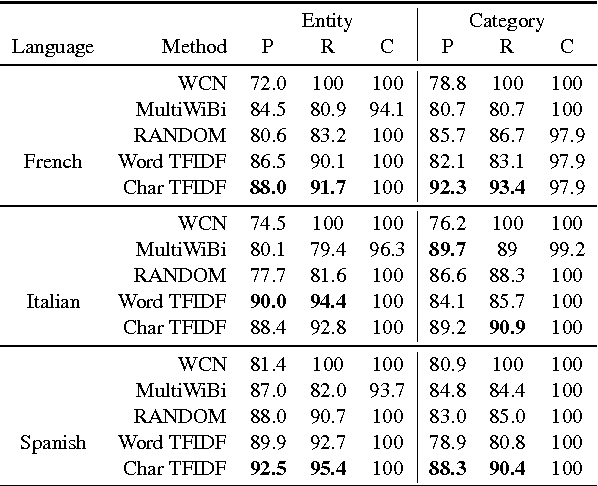
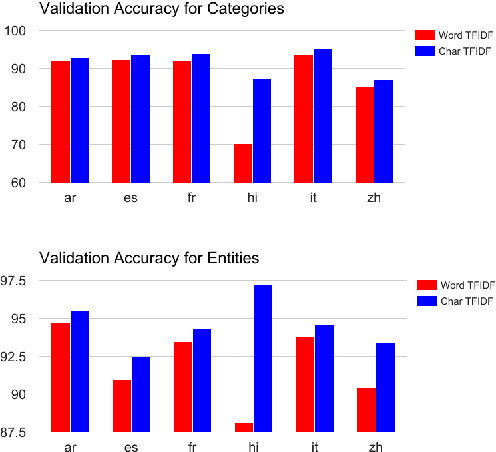
We propose a simple, yet effective, approach towards inducing multilingual taxonomies from Wikipedia. Given an English taxonomy, our approach leverages the interlanguage links of Wikipedia followed by character-level classifiers to induce high-precision, high-coverage taxonomies in other languages. Through experiments, we demonstrate that our approach significantly outperforms the state-of-the-art, heuristics-heavy approaches for six languages. As a consequence of our work, we release presumably the largest and the most accurate multilingual taxonomic resource spanning over 280 languages.
Multimodal Classification for Analysing Social Media
Aug 07, 2017
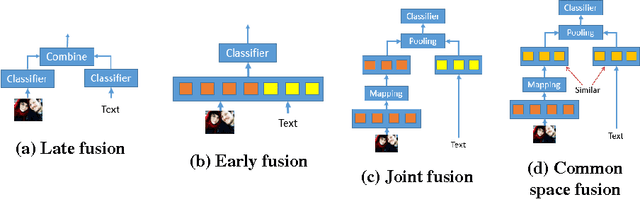
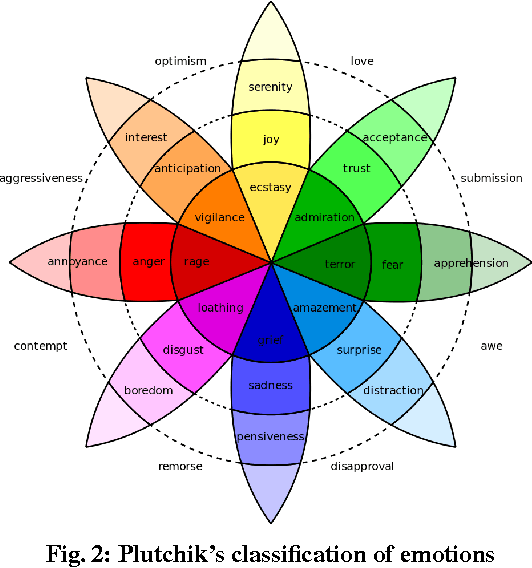
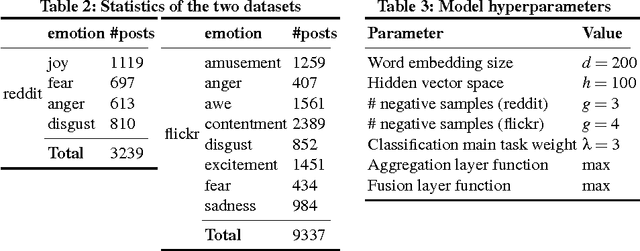
Classification of social media data is an important approach in understanding user behavior on the Web. Although information on social media can be of different modalities such as texts, images, audio or videos, traditional approaches in classification usually leverage only one prominent modality. Techniques that are able to leverage multiple modalities are often complex and susceptible to the absence of some modalities. In this paper, we present simple models that combine information from different modalities to classify social media content and are able to handle the above problems with existing techniques. Our models combine information from different modalities using a pooling layer and an auxiliary learning task is used to learn a common feature space. We demonstrate the performance of our models and their robustness to the missing of some modalities in the emotion classification domain. Our approaches, although being simple, can not only achieve significantly higher accuracies than traditional fusion approaches but also have comparable results when only one modality is available.
Matching Demand with Supply in the Smart Grid using Agent-Based Multiunit Auction
Aug 22, 2013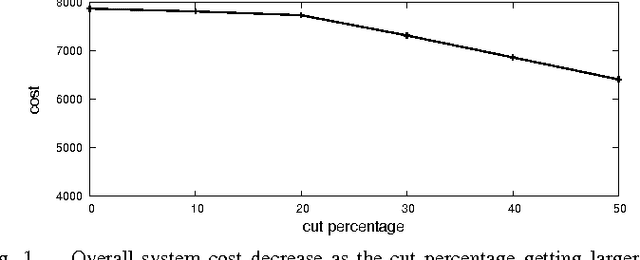
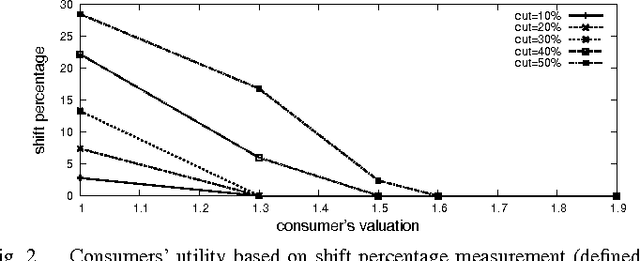
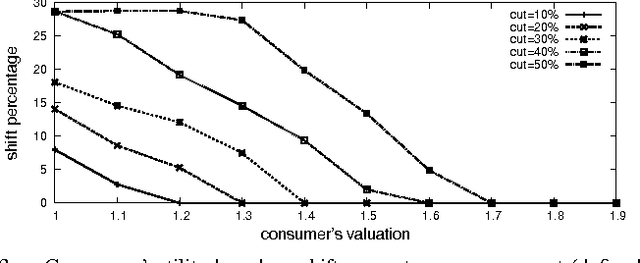
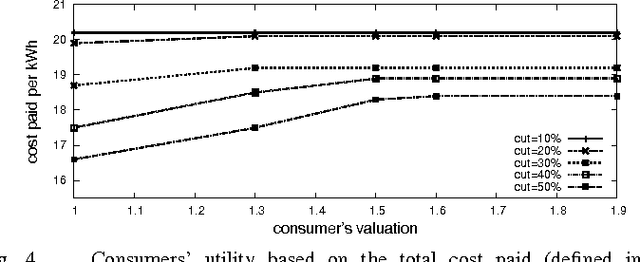
Recent work has suggested reducing electricity generation cost by cutting the peak to average ratio (PAR) without reducing the total amount of the loads. However, most of these proposals rely on consumer's willingness to act. In this paper, we propose an approach to cut PAR explicitly from the supply side. The resulting cut loads are then distributed among consumers by the means of a multiunit auction which is done by an intelligent agent on behalf of the consumer. This approach is also in line with the future vision of the smart grid to have the demand side matched with the supply side. Experiments suggest that our approach reduces overall system cost and gives benefit to both consumers and the energy provider.