 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Generation on Complex Datasets
Jul 15, 2019
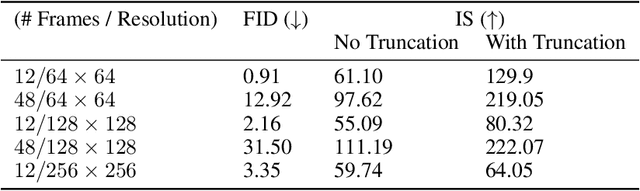

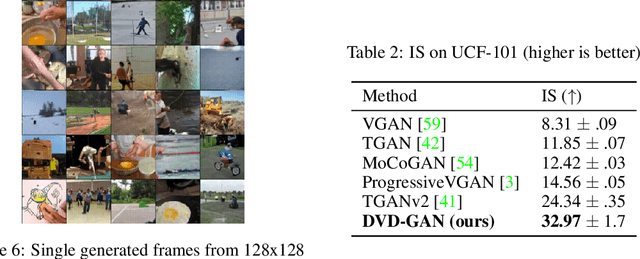
Generative models of natural images have progressed towards high fidelity samples by the strong leveraging of scale. We attempt to carry this success to the field of video modeling by showing that large Generative Adversarial Networks trained on the complex Kinetics-600 dataset are able to produce video samples of substantially higher complexity than previous work. Our proposed network, Dual Video Discriminator GAN (DVD-GAN), scales to longer and higher resolution videos by leveraging a computationally efficient decomposition of its discriminator. We evaluate on the related tasks of video synthesis and video prediction, and achieve new state of the art Frechet Inception Distance on prediction for Kinetics-600, as well as state of the art Inception Score for synthesis on the UCF-101 dataset, alongside establishing a number of strong baselines on Kinetics-600.
Large Scale Adversarial Representation Learning
Jul 04, 2019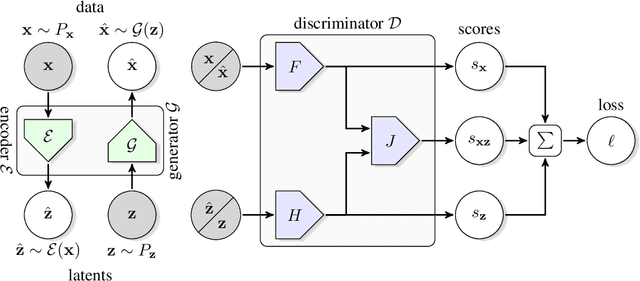
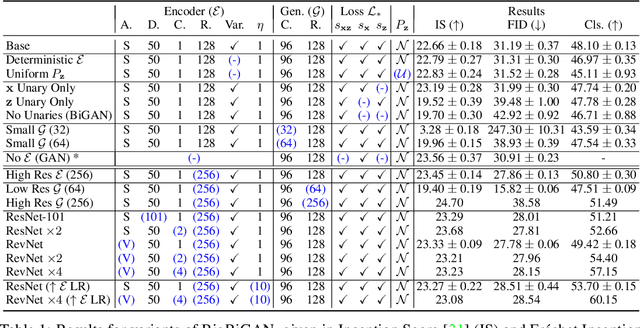
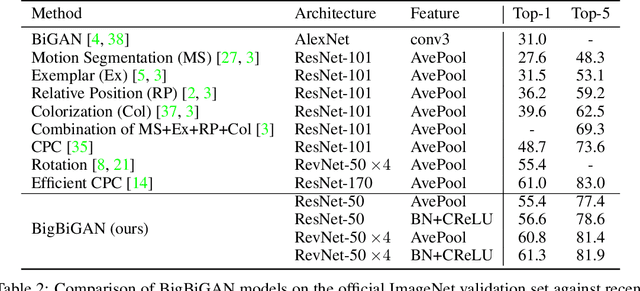

Adversarially trained generative models (GANs) have recently achieved compelling image synthesis results. But despite early successes in using GANs for unsupervised representation learning, they have since been superseded by approaches based on self-supervision. In this work we show that progress in image generation quality translates to substantially improved representation learning performance. Our approach, BigBiGAN, builds upon the state-of-the-art BigGAN model, extending it to representation learning by adding an encoder and modifying the discriminator. We extensively evaluate the representation learning and generation capabilities of these BigBiGAN models, demonstrating that these generation-based models achieve the state of the art in unsupervised representation learning on ImageNet, as well as in unconditional image generation.
Non-Differentiable Supervised Learning with Evolution Strategies and Hybrid Methods
Jun 07, 2019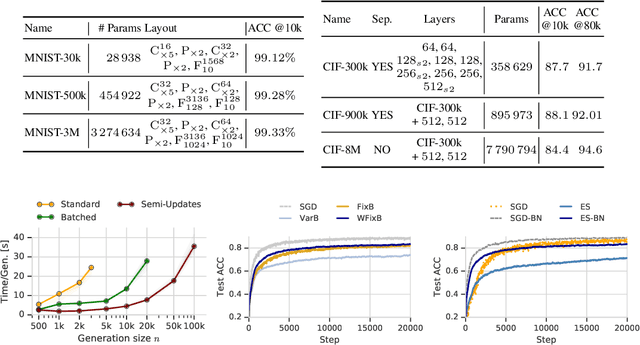

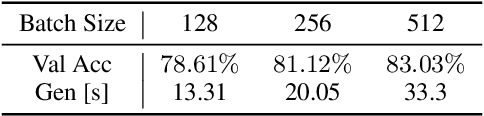

In this work we show that Evolution Strategies (ES) are a viable method for learning non-differentiable parameters of large supervised models. ES are black-box optimization algorithms that estimate distributions of model parameters; however they have only been used for relatively small problems so far. We show that it is possible to scale ES to more complex tasks and models with millions of parameters. While using ES for differentiable parameters is computationally impractical (although possible), we show that a hybrid approach is practically feasible in the case where the model has both differentiable and non-differentiable parameters. In this approach we use standard gradient-based methods for learning differentiable weights, while using ES for learning non-differentiable parameters - in our case sparsity masks of the weights. This proposed method is surprisingly competitive, and when parallelized over multiple devices has only negligible training time overhead compared to training with gradient descent. Additionally, this method allows to train sparse models from the first training step, so they can be much larger than when using methods that require training dense models first. We present results and analysis of supervised feed-forward models (such as MNIST and CIFAR-10 classification), as well as recurrent models, such as SparseWaveRNN for text-to-speech.
Hierarchical Autoregressive Image Models with Auxiliary Decoders
Mar 06, 2019

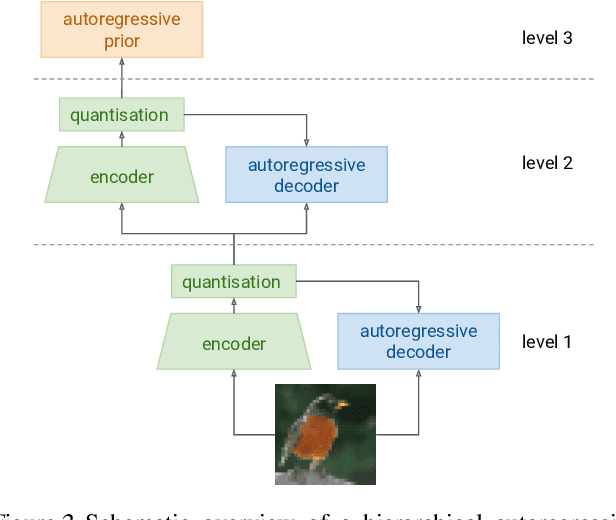
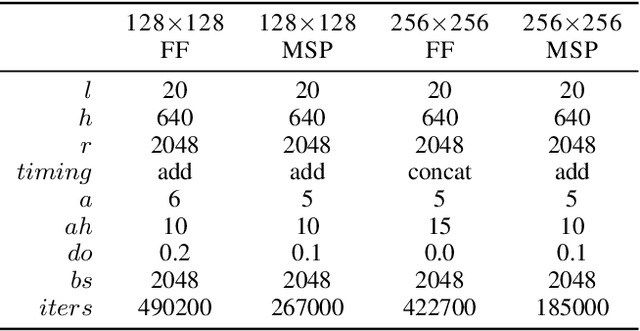
Autoregressive generative models of images tend to be biased towards capturing local structure, and as a result they often produce samples which are lacking in terms of large-scale coherence. To address this, we propose two methods to learn discrete representations of images which abstract away local detail. We show that autoregressive models conditioned on these representations can produce high-fidelity reconstructions of images, and that we can train autoregressive priors on these representations that produce samples with large-scale coherence. We can recursively apply the learning procedure, yielding a hierarchy of progressively more abstract image representations. We train hierarchical class-conditional autoregressive models on the ImageNet dataset and demonstrate that they are able to generate realistic images at resolutions of 128$\times$128 and 256$\times$256 pixels.
The StreetLearn Environment and Dataset
Mar 04, 2019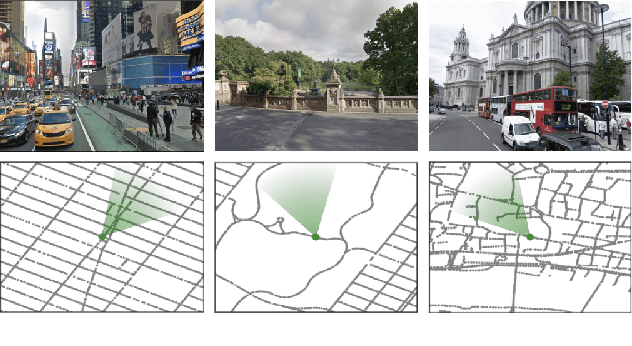
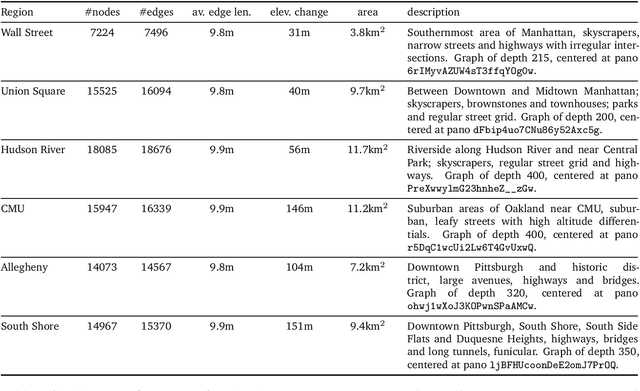
Navigation is a rich and well-grounded problem domain that drives progress in many different areas of research: perception, planning, memory, exploration, and optimisation in particular. Historically these challenges have been separately considered and solutions built that rely on stationary datasets - for example, recorded trajectories through an environment. These datasets cannot be used for decision-making and reinforcement learning, however, and in general the perspective of navigation as an interactive learning task, where the actions and behaviours of a learning agent are learned simultaneously with the perception and planning, is relatively unsupported. Thus, existing navigation benchmarks generally rely on static datasets (Geiger et al., 2013; Kendall et al., 2015) or simulators (Beattie et al., 2016; Shah et al., 2018). To support and validate research in end-to-end navigation, we present StreetLearn: an interactive, first-person, partially-observed visual environment that uses Google Street View for its photographic content and broad coverage, and give performance baselines for a challenging goal-driven navigation task. The environment code, baseline agent code, and the dataset are available at http://streetlearn.cc
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Sep 28, 2018
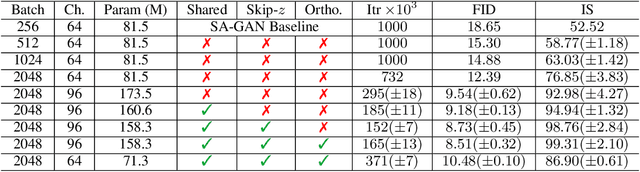


Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenable to a simple "truncation trick", allowing fine control over the trade-off between sample fidelity and variety by truncating the latent space. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128x128 resolution, our models (BigGANs) achieve an Inception Score (IS) of 166.3 and Frechet Inception Distance (FID) of 9.6, improving over the previous best IS of 52.52 and FID of 18.65.
This Time with Feeling: Learning Expressive Musical Performance
Aug 10, 2018
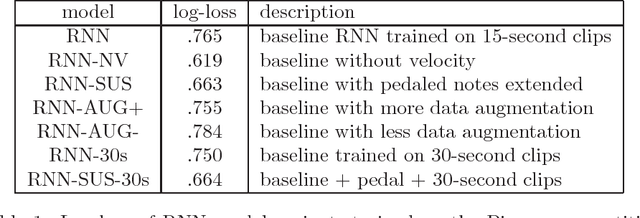

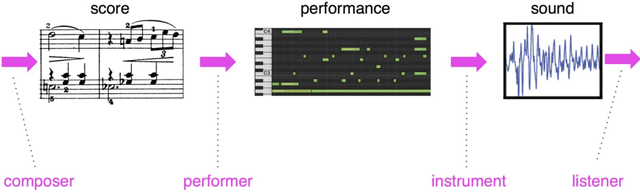
Music generation has generally been focused on either creating scores or interpreting them. We discuss differences between these two problems and propose that, in fact, it may be valuable to work in the space of direct $\it performance$ generation: jointly predicting the notes $\it and$ $\it also$ their expressive timing and dynamics. We consider the significance and qualities of the data set needed for this. Having identified both a problem domain and characteristics of an appropriate data set, we show an LSTM-based recurrent network model that subjectively performs quite well on this task. Critically, we provide generated examples. We also include feedback from professional composers and musicians about some of these examples.
Learning to Search with MCTSnets
Jul 17, 2018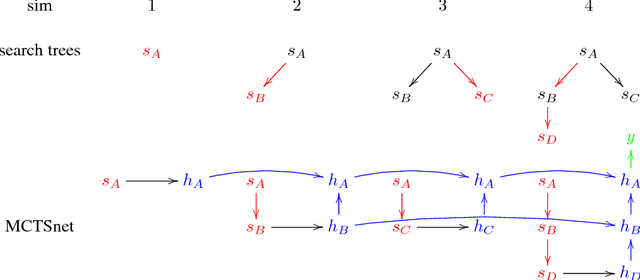
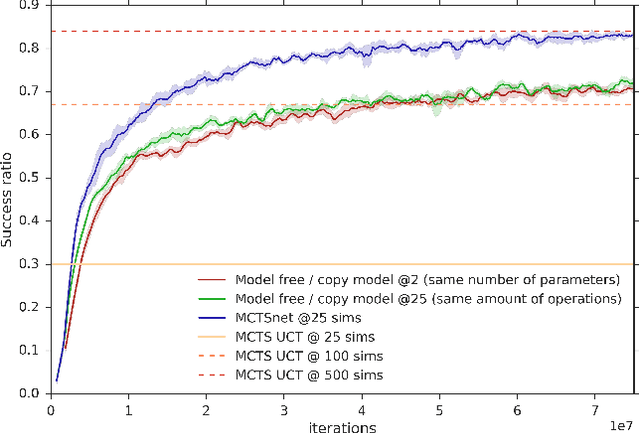
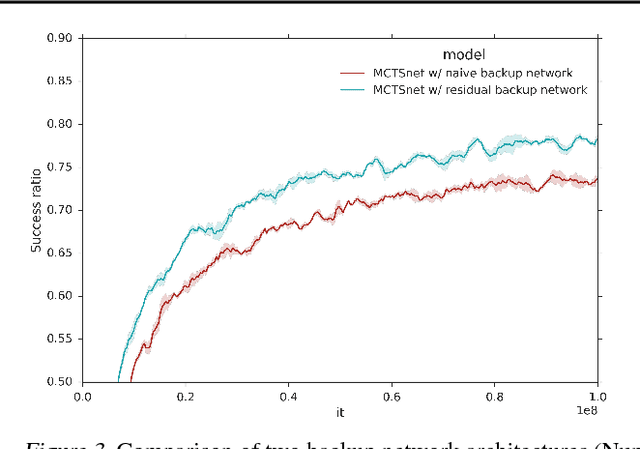
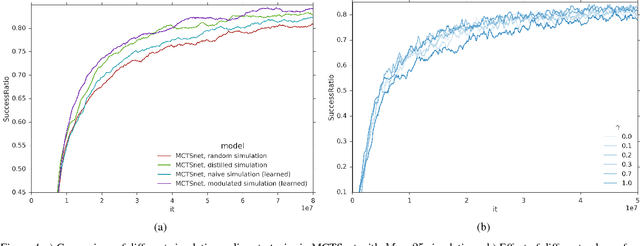
Planning problems are among the most important and well-studied problems in artificial intelligence. They are most typically solved by tree search algorithms that simulate ahead into the future, evaluate future states, and back-up those evaluations to the root of a search tree. Among these algorithms, Monte-Carlo tree search (MCTS) is one of the most general, powerful and widely used. A typical implementation of MCTS uses cleverly designed rules, optimized to the particular characteristics of the domain. These rules control where the simulation traverses, what to evaluate in the states that are reached, and how to back-up those evaluations. In this paper we instead learn where, what and how to search. Our architecture, which we call an MCTSnet, incorporates simulation-based search inside a neural network, by expanding, evaluating and backing-up a vector embedding. The parameters of the network are trained end-to-end using gradient-based optimisation. When applied to small searches in the well known planning problem Sokoban, the learned search algorithm significantly outperformed MCTS baselines.
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Jun 28, 2018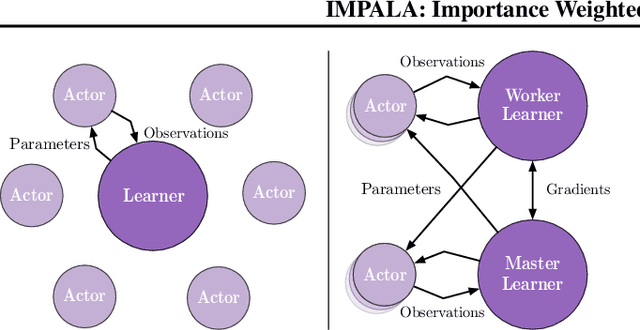
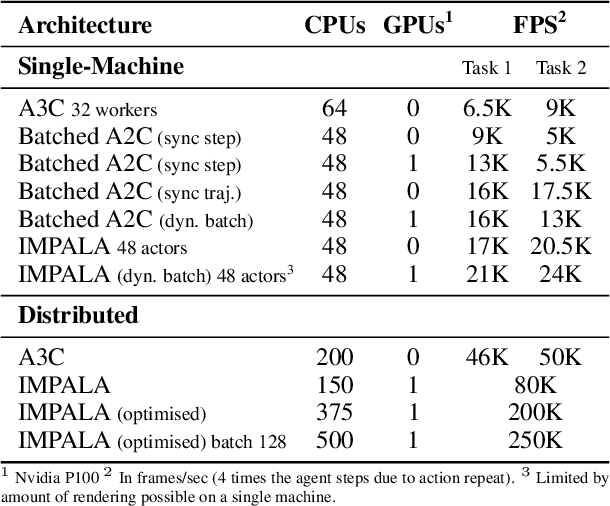
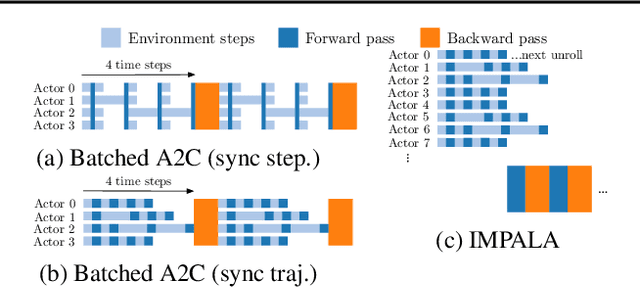
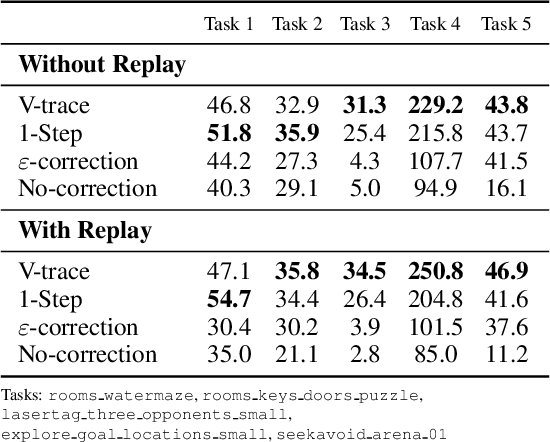
In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
The challenge of realistic music generation: modelling raw audio at scale
Jun 26, 2018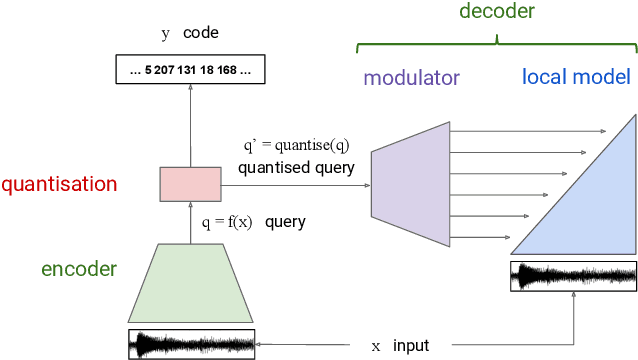
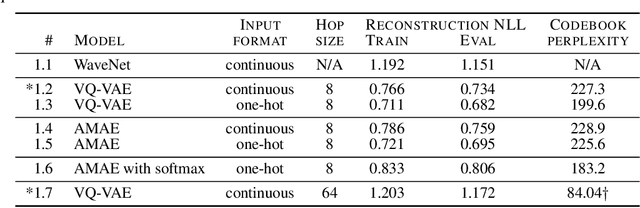
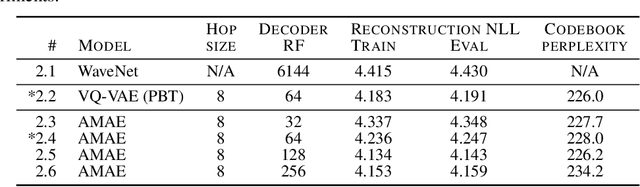
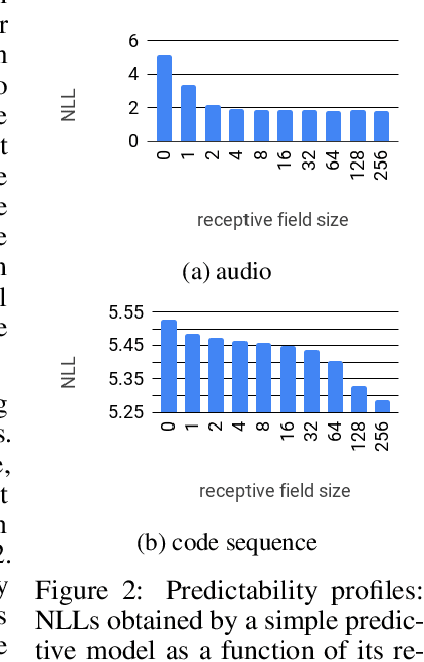
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.