 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for fingerspelled content in American Sign Language
Mar 24, 2022
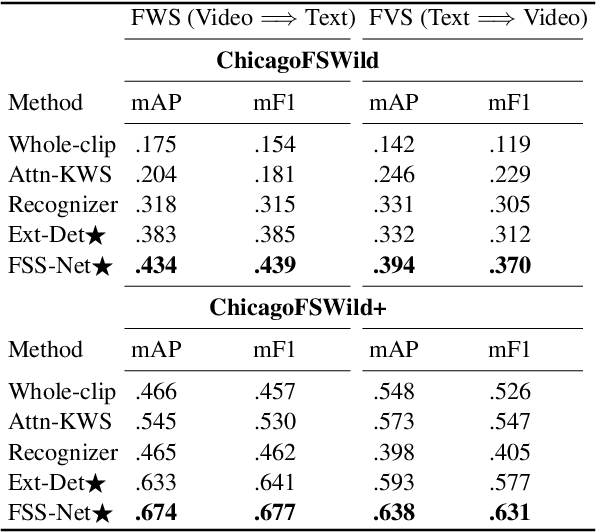
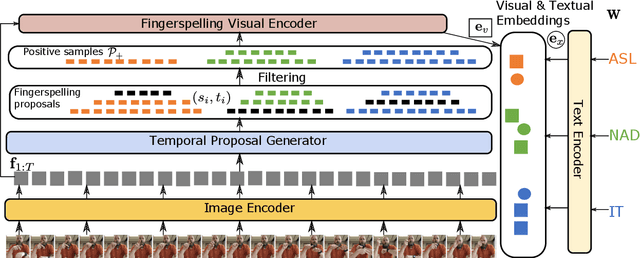
Natural language processing for sign language video - including tasks like recognition, translation, and search - is crucial for making artificial intelligence technologies accessible to deaf individuals, and is gaining research interest in recent years. In this paper, we address the problem of searching for fingerspelled key-words or key phrases in raw sign language videos. This is an important task since significant content in sign language is often conveyed via fingerspelling, and to our knowledge the task has not been studied before. We propose an end-to-end model for this task, FSS-Net, that jointly detects fingerspelling and matches it to a text sequence. Our experiments, done on a large public dataset of ASL fingerspelling in the wild, show the importance of fingerspelling detection as a component of a search and retrieval model. Our model significantly outperforms baseline methods adapted from prior work on related tasks
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021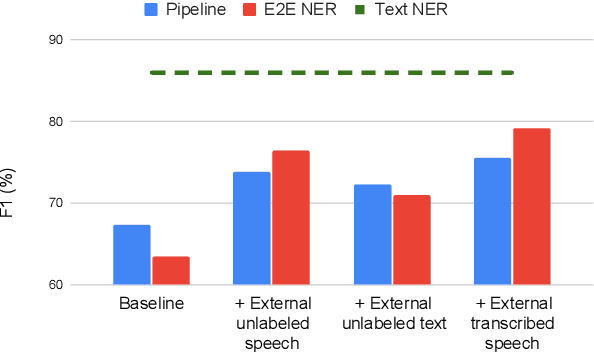

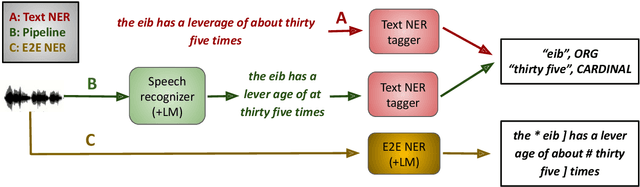
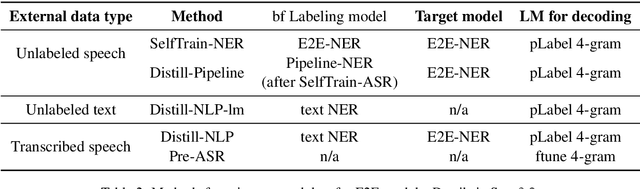
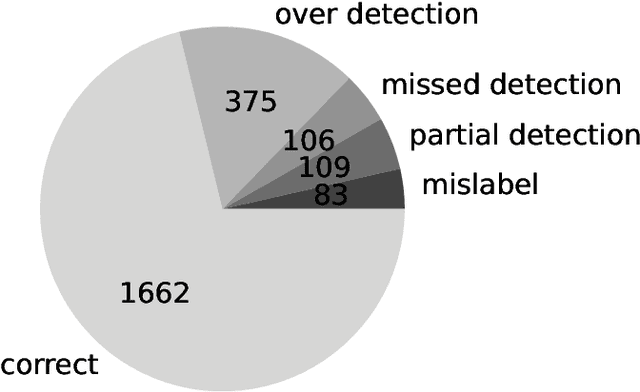
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021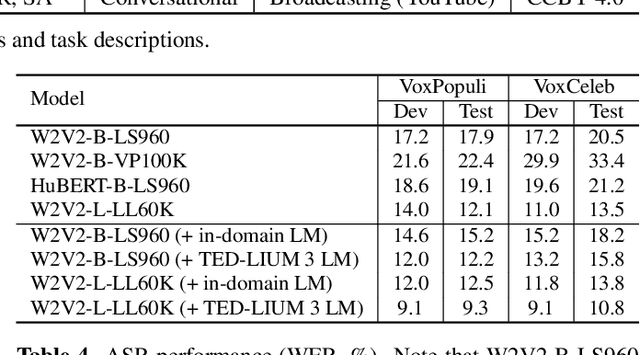
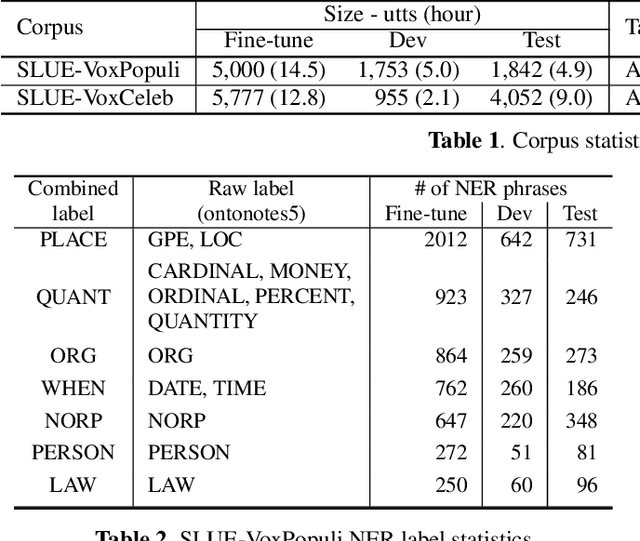
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Substructure Distribution Projection for Zero-Shot Cross-Lingual Dependency Parsing
Oct 16, 2021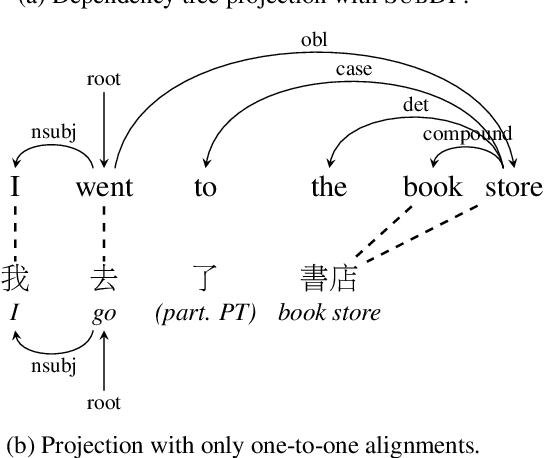
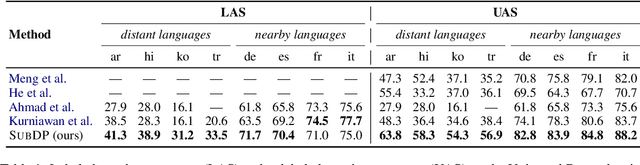
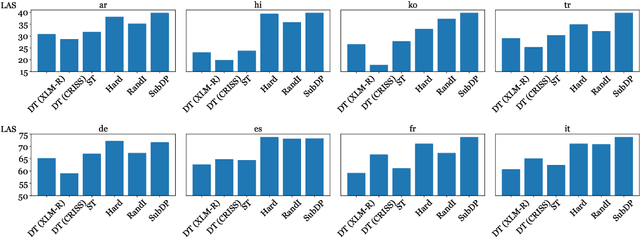
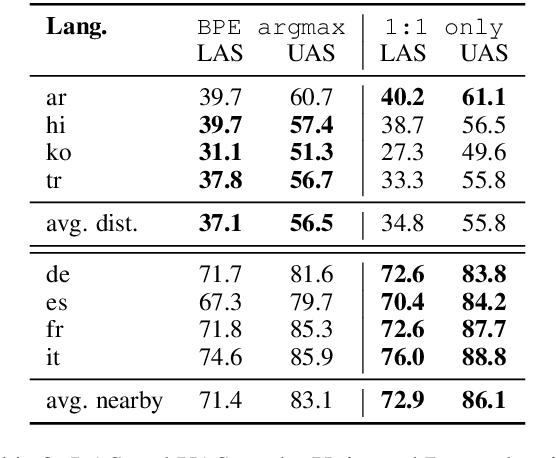
We present substructure distribution projection (SubDP), a technique that projects a distribution over structures in one domain to another, by projecting substructure distributions separately. Models for the target domains can be then trained, using the projected distributions as soft silver labels. We evaluate SubDP on zero-shot cross-lingual dependency parsing, taking dependency arcs as substructures: we project the predicted dependency arc distributions in the source language(s) to target language(s), and train a target language parser to fit the resulting distributions. When an English treebank is the only annotation that involves human effort, SubDP achieves better unlabeled attachment score than all prior work on the Universal Dependencies v2.2 (Nivre et al., 2020) test set across eight diverse target languages, as well as the best labeled attachment score on six out of eight languages. In addition, SubDP improves zero-shot cross-lingual dependency parsing with very few (e.g., 50) supervised bitext pairs, across a broader range of target languages.
On Generalization in Coreference Resolution
Sep 20, 2021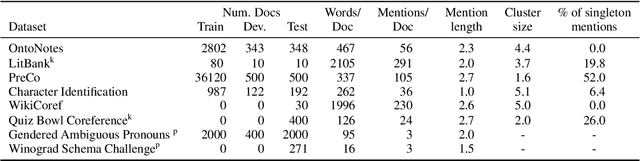
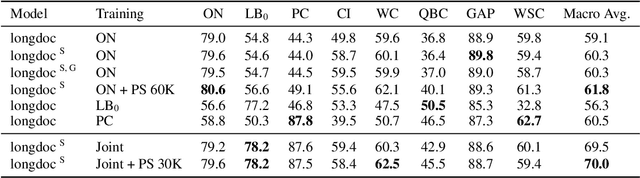

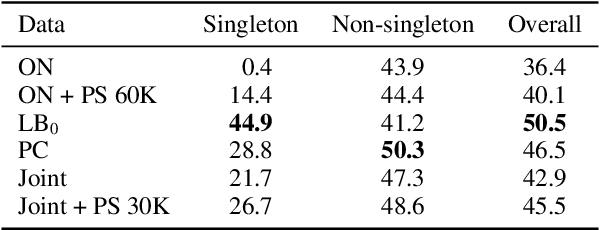
While coreference resolution is defined independently of dataset domain, most models for performing coreference resolution do not transfer well to unseen domains. We consolidate a set of 8 coreference resolution datasets targeting different domains to evaluate the off-the-shelf performance of models. We then mix three datasets for training; even though their domain, annotation guidelines, and metadata differ, we propose a method for jointly training a single model on this heterogeneous data mixture by using data augmentation to account for annotation differences and sampling to balance the data quantities. We find that in a zero-shot setting, models trained on a single dataset transfer poorly while joint training yields improved overall performance, leading to better generalization in coreference resolution models. This work contributes a new benchmark for robust coreference resolution and multiple new state-of-the-art results.
Layer-wise Analysis of a Self-supervised Speech Representation Model
Jul 10, 2021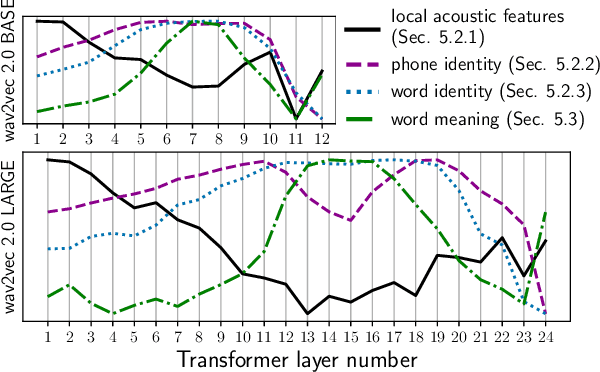
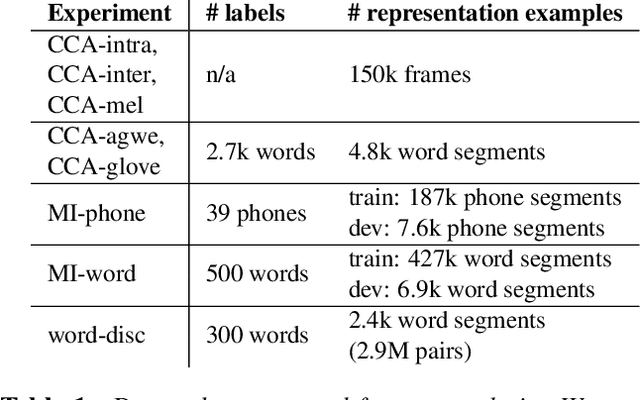
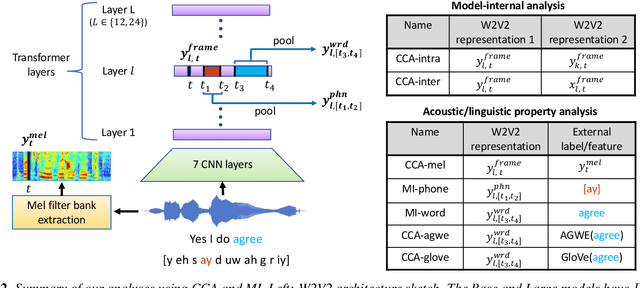

Recently proposed self-supervised learning approaches have been successful for pre-training speech representation models. The utility of these learned representations has been observed empirically, but not much has been studied about the type or extent of information encoded in the pre-trained representations themselves. Developing such insights can help understand the capabilities and limits of these models and enable the research community to more efficiently develop their usage for downstream applications. In this work, we begin to fill this gap by examining one recent and successful pre-trained model (wav2vec 2.0), via its intermediate representation vectors, using a suite of analysis tools. We use the metrics of canonical correlation, mutual information, and performance on simple downstream tasks with non-parametric probes, in order to (i) query for acoustic and linguistic information content, (ii) characterize the evolution of information across model layers, and (iii) understand how fine-tuning the model for automatic speech recognition (ASR) affects these observations. Our findings motivate modifying the fine-tuning protocol for ASR, which produces improved word error rates in a low-resource setting.
Fingerspelling Detection in American Sign Language
Apr 03, 2021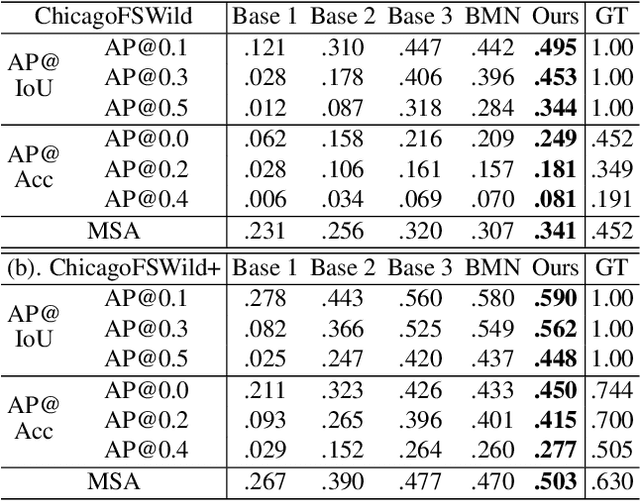
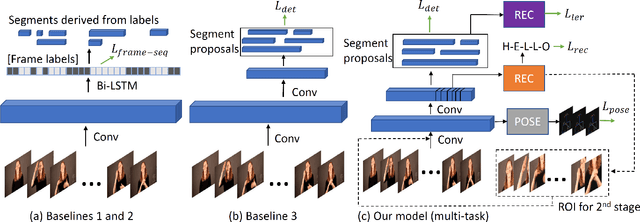
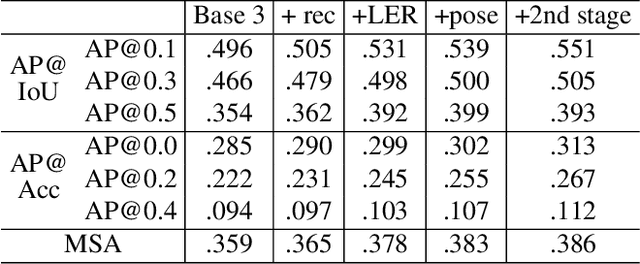
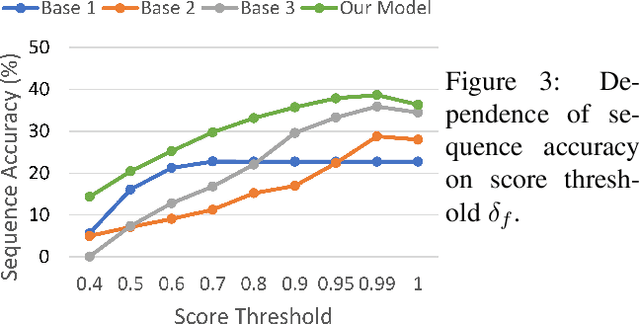
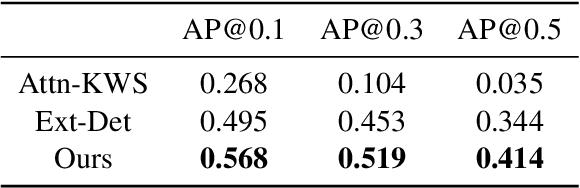
Fingerspelling, in which words are signed letter by letter, is an important component of American Sign Language. Most previous work on automatic fingerspelling recognition has assumed that the boundaries of fingerspelling regions in signing videos are known beforehand. In this paper, we consider the task of fingerspelling detection in raw, untrimmed sign language videos. This is an important step towards building real-world fingerspelling recognition systems. We propose a benchmark and a suite of evaluation metrics, some of which reflect the effect of detection on the downstream fingerspelling recognition task. In addition, we propose a new model that learns to detect fingerspelling via multi-task training, incorporating pose estimation and fingerspelling recognition (transcription) along with detection, and compare this model to several alternatives. The model outperforms all alternative approaches across all metrics, establishing a state of the art on the benchmark.
Learning Chess Blindfolded: Evaluating Language Models on State Tracking
Feb 26, 2021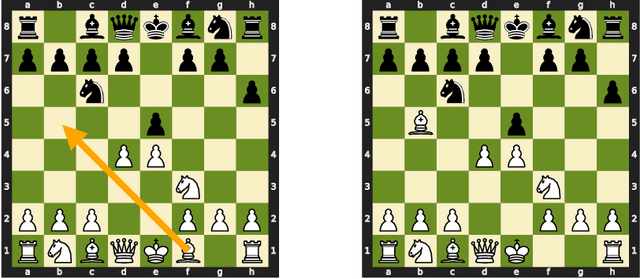


Transformer language models have made tremendous strides in natural language understanding tasks. However, the complexity of natural language makes it challenging to ascertain how accurately these models are tracking the world state underlying the text. Motivated by this issue, we consider the task of language modeling for the game of chess. Unlike natural language, chess notations describe a simple, constrained, and deterministic domain. Moreover, we observe that the appropriate choice of chess notation allows for directly probing the world state, without requiring any additional probing-related machinery. We find that: (a) With enough training data, transformer language models can learn to track pieces and predict legal moves with high accuracy when trained solely on move sequences. (b) For small training sets providing access to board state information during training can yield significant improvements. (c) The success of transformer language models is dependent on access to the entire game history i.e. "full attention". Approximating this full attention results in a significant performance drop. We propose this testbed as a benchmark for future work on the development and analysis of transformer language models.
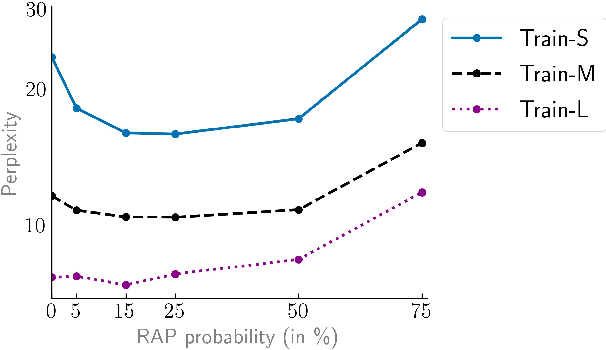
Substructure Substitution: Structured Data Augmentation for NLP
Jan 02, 2021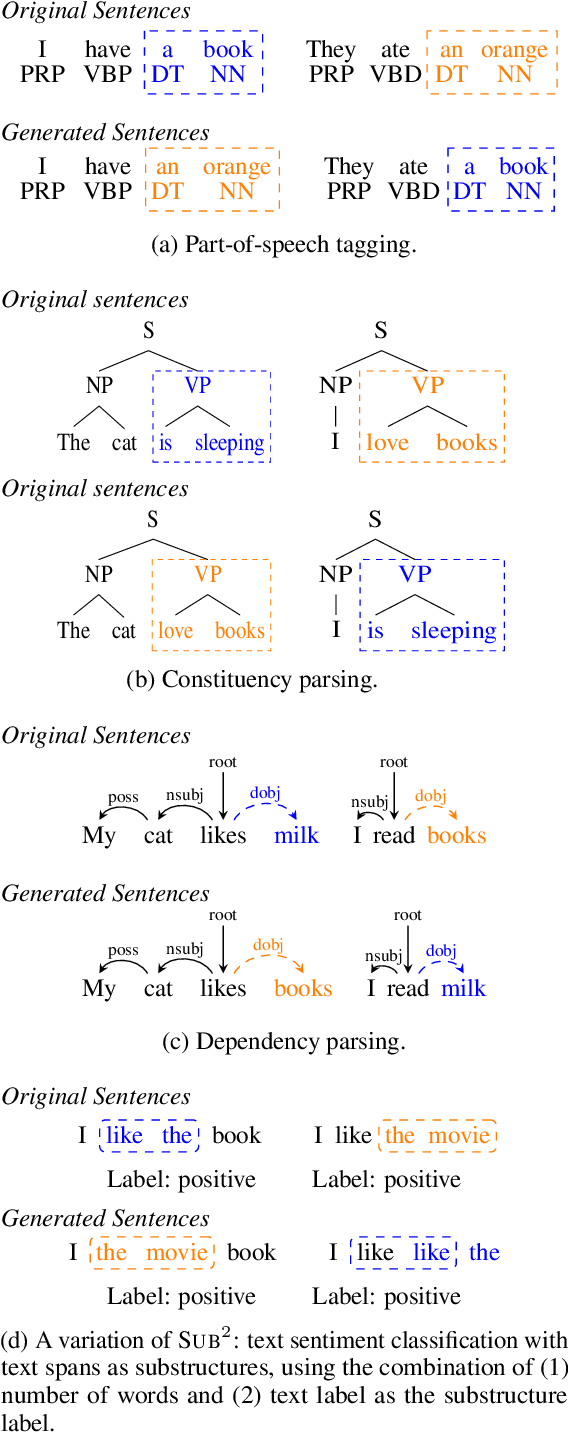
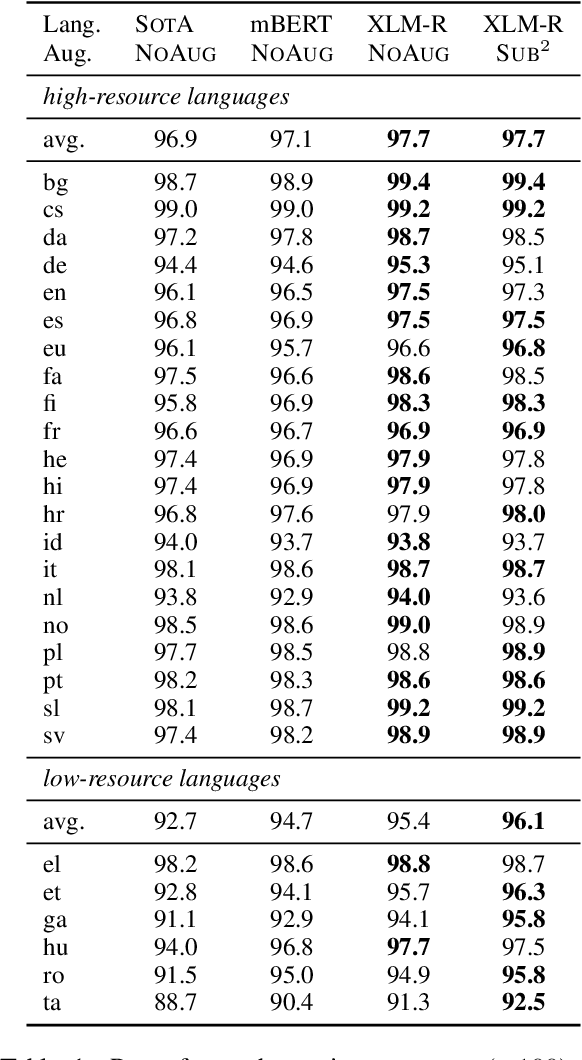
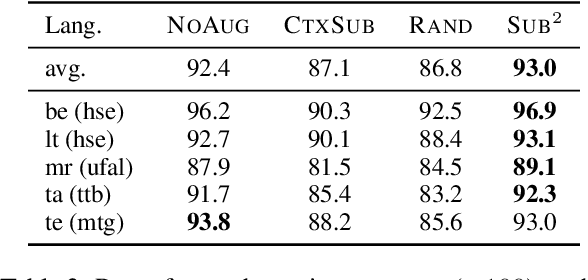
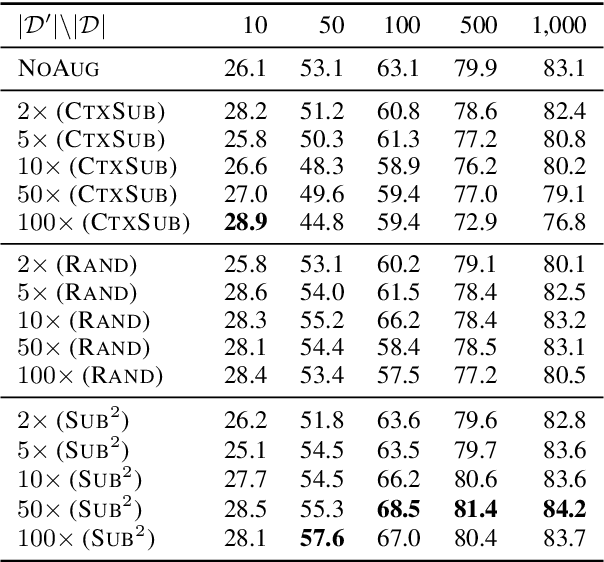
We study a family of data augmentation methods, substructure substitution (SUB2), for natural language processing (NLP) tasks. SUB2 generates new examples by substituting substructures (e.g., subtrees or subsequences) with ones with the same label, which can be applied to many structured NLP tasks such as part-of-speech tagging and parsing. For more general tasks (e.g., text classification) which do not have explicitly annotated substructures, we present variations of SUB2 based on constituency parse trees, introducing structure-aware data augmentation methods to general NLP tasks. For most cases, training with the augmented dataset by SUB2 achieves better performance than training with the original training set. Further experiments show that SUB2 has more consistent performance than other investigated augmentation methods, across different tasks and sizes of the seed dataset.
A Correspondence Variational Autoencoder for Unsupervised Acoustic Word Embeddings
Dec 03, 2020
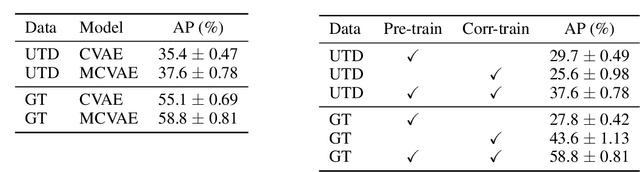
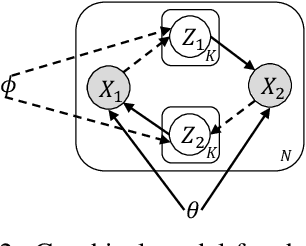
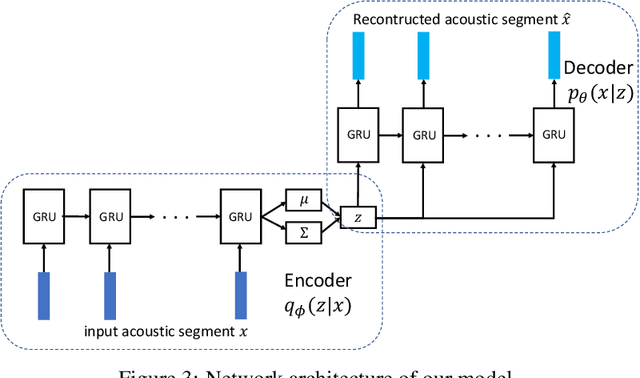
We propose a new unsupervised model for mapping a variable-duration speech segment to a fixed-dimensional representation. The resulting acoustic word embeddings can form the basis of search, discovery, and indexing systems for low- and zero-resource languages. Our model, which we refer to as a maximal sampling correspondence variational autoencoder (MCVAE), is a recurrent neural network (RNN) trained with a novel self-supervised correspondence loss that encourages consistency between embeddings of different instances of the same word. Our training scheme improves on previous correspondence training approaches through the use and comparison of multiple samples from the approximate posterior distribution. In the zero-resource setting, the MCVAE can be trained in an unsupervised way, without any ground-truth word pairs, by using the word-like segments discovered via an unsupervised term discovery system. In both this setting and a semi-supervised low-resource setting (with a limited set of ground-truth word pairs), the MCVAE outperforms previous state-of-the-art models, such as Siamese-, CAE- and VAE-based RNNs.