 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training BERT on Arabic Tweets: Practical Considerations
Feb 21, 2021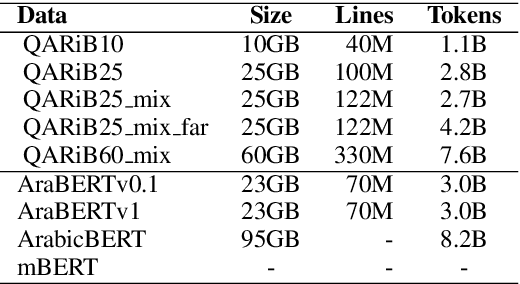
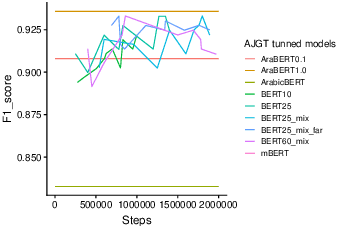
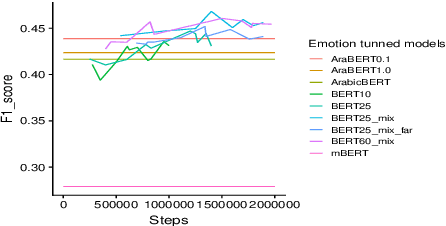
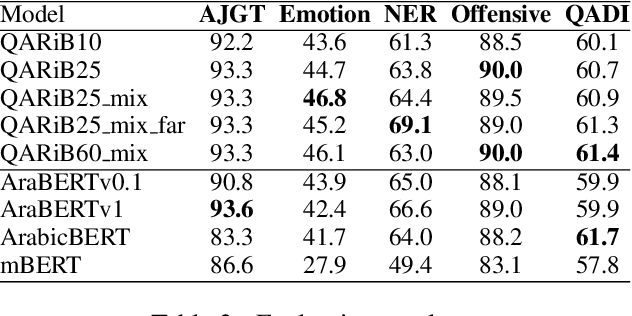
Pretraining Bidirectional Encoder Representations from Transformers (BERT) for downstream NLP tasks is a non-trival task. We pretrained 5 BERT models that differ in the size of their training sets, mixture of formal and informal Arabic, and linguistic preprocessing. All are intended to support Arabic dialects and social media. The experiments highlight the centrality of data diversity and the efficacy of linguistically aware segmentation. They also highlight that more data or more training step do not necessitate better models. Our new models achieve new state-of-the-art results on several downstream tasks. The resulting models are released to the community under the name QARiB.
BERT Transformer model for Detecting Arabic GPT2 Auto-Generated Tweets
Jan 22, 2021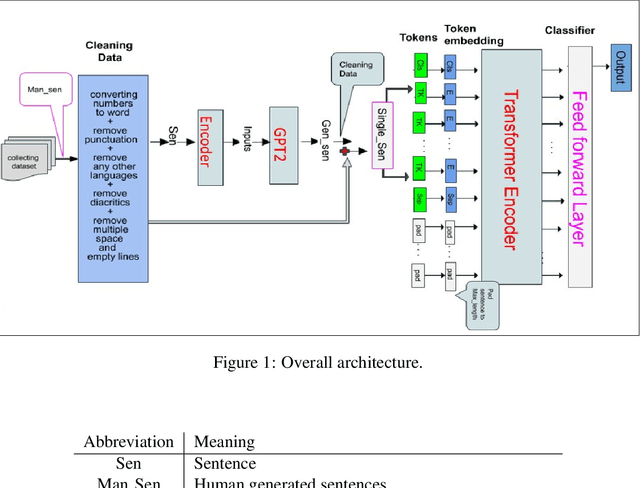

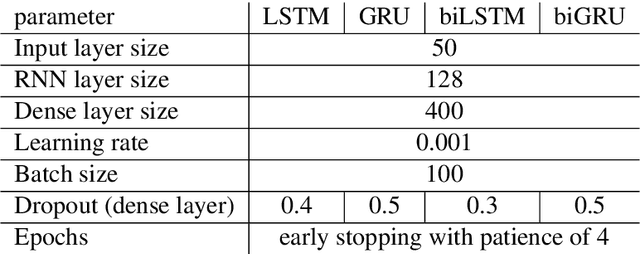
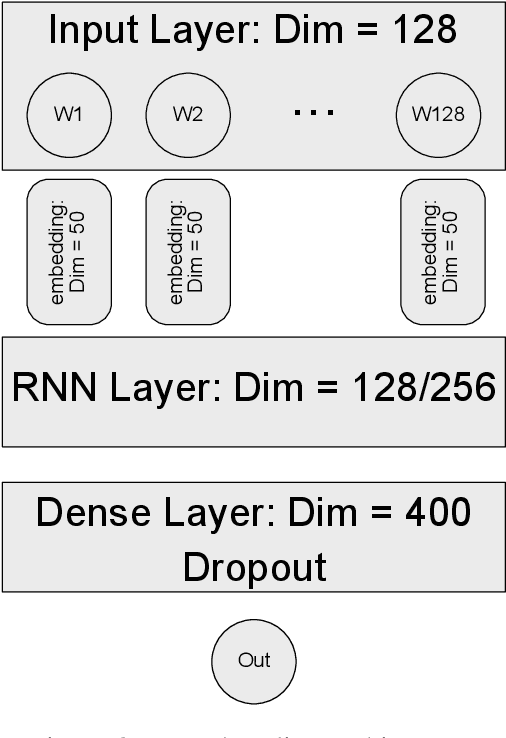
During the last two decades, we have progressively turned to the Internet and social media to find news, entertain conversations and share opinion. Recently, OpenAI has developed a ma-chine learning system called GPT-2 for Generative Pre-trained Transformer-2, which can pro-duce deepfake texts. It can generate blocks of text based on brief writing prompts that look like they were written by humans, facilitating the spread false or auto-generated text. In line with this progress, and in order to counteract potential dangers, several methods have been pro-posed for detecting text written by these language models. In this paper, we propose a transfer learning based model that will be able to detect if an Arabic sentence is written by humans or automatically generated by bots. Our dataset is based on tweets from a previous work, which we have crawled and extended using the Twitter API. We used GPT2-Small-Arabic to generate fake Arabic Sentences. For evaluation, we compared different recurrent neural network (RNN) word embeddings based baseline models, namely: LSTM, BI-LSTM, GRU and BI-GRU, with a transformer-based model. Our new transfer-learning model has obtained an accuracy up to 98%. To the best of our knowledge, this work is the first study where ARABERT and GPT2 were combined to detect and classify the Arabic auto-generated texts.
A Panoramic Survey of Natural Language Processing in the Arab World
Nov 26, 2020The term natural language refers to any system of symbolic communication (spoken, signed or written) without intentional human planning and design. This distinguishes natural languages such as Arabic and Japanese from artificially constructed languages such as Esperanto or Python. Natural language processing (NLP) is the sub-field of artificial intelligence (AI) focused on modeling natural languages to build applications such as speech recognition and synthesis, machine translation, optical character recognition (OCR), sentiment analysis (SA), question answering, dialogue systems, etc. NLP is a highly interdisciplinary field with connections to computer science, linguistics, cognitive science, psychology, mathematics and others. Some of the earliest AI applications were in NLP (e.g., machine translation); and the last decade (2010-2020) in particular has witnessed an incredible increase in quality, matched with a rise in public awareness, use, and expectations of what may have seemed like science fiction in the past. NLP researchers pride themselves on developing language independent models and tools that can be applied to all human languages, e.g. machine translation systems can be built for a variety of languages using the same basic mechanisms and models. However, the reality is that some languages do get more attention (e.g., English and Chinese) than others (e.g., Hindi and Swahili). Arabic, the primary language of the Arab world and the religious language of millions of non-Arab Muslims is somewhere in the middle of this continuum. Though Arabic NLP has many challenges, it has seen many successes and developments. Next we discuss Arabic's main challenges as a necessary background, and we present a brief history of Arabic NLP. We then survey a number of its research areas, and close with a critical discussion of the future of Arabic NLP.
Political Framing: US COVID19 Blame Game
Jul 19, 2020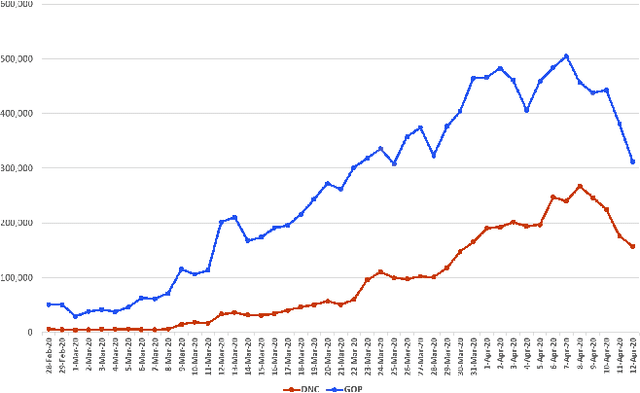


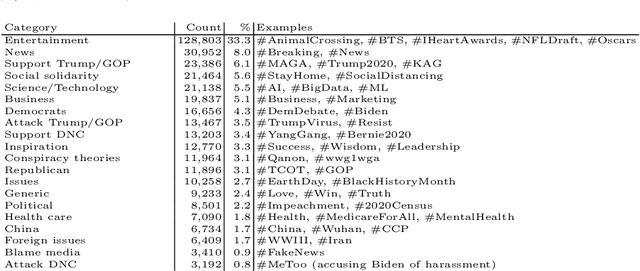
Through the use of Twitter, framing has become a prominent presidential campaign tool for politically active users. Framing is used to influence thoughts by evoking a particular perspective on an event. In this paper, we show that the COVID19 pandemic rather than being viewed as a public health issue, political rhetoric surrounding it is mostly shaped through a blame frame (blame Trump, China, or conspiracies) and a support frame (support candidates) backing the agenda of Republican and Democratic users in the lead up to the 2020 presidential campaign. We elucidate the divergences between supporters of both parties on Twitter via the use of frames. Additionally, we show how framing is used to positively or negatively reinforce users' thoughts. We look at how Twitter can efficiently be used to identify frames for topics through a reproducible pipeline.
Fighting the COVID-19 Infodemic in Social Media: A Holistic Perspective and a Call to Arms
Jul 15, 2020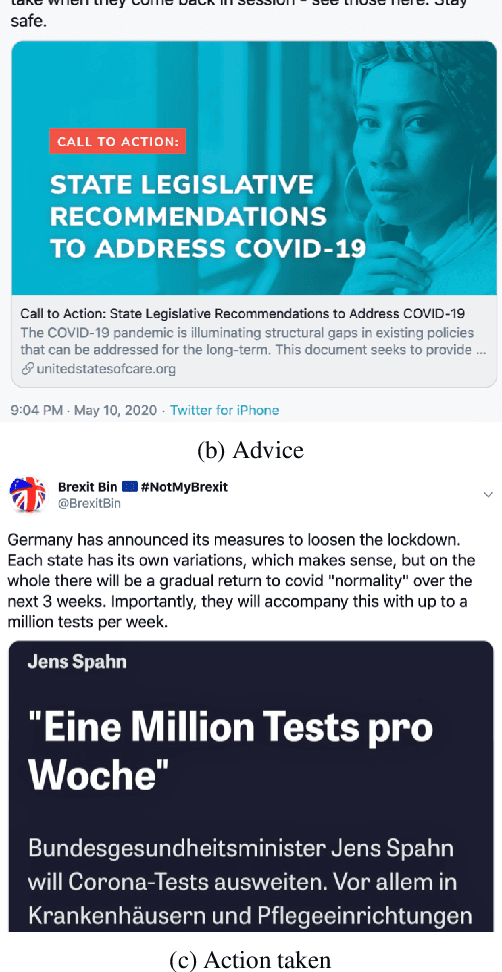
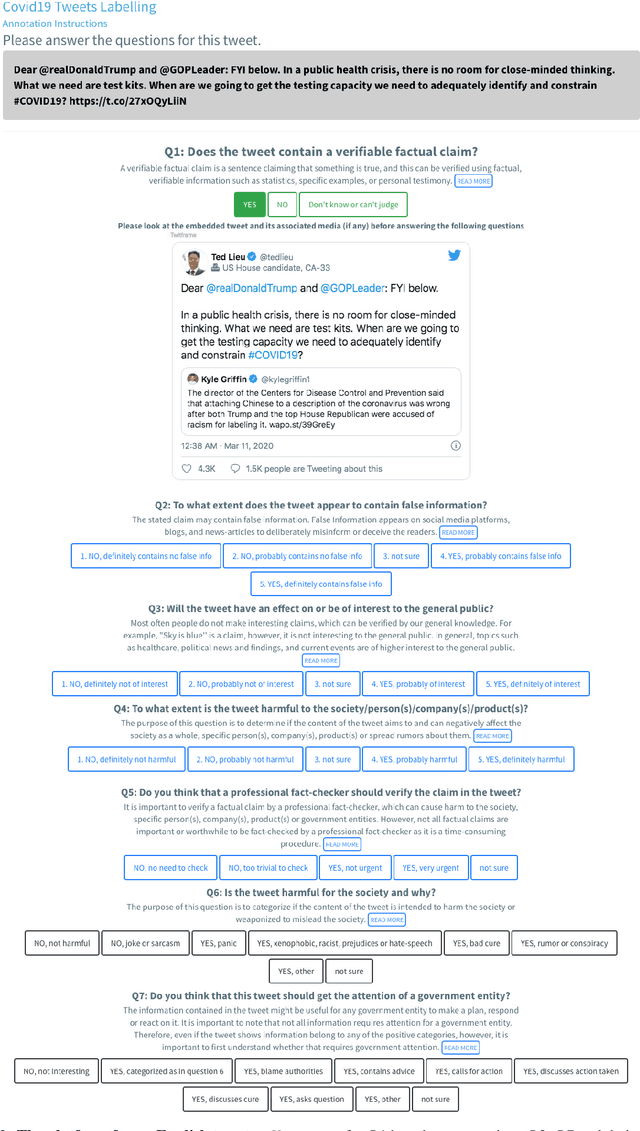

With the outbreak of the COVID-19 pandemic, people turned to social media to read and to share timely information including statistics, warnings, advice, and inspirational stories. Unfortunately, alongside all this useful information, there was also a new blending of medical and political misinformation and disinformation, which gave rise to the first global infodemic. While fighting this infodemic is typically thought of in terms of factuality, the problem is much broader as malicious content includes not only fake news, rumors, and conspiracy theories, but also promotion of fake cures, panic, racism, xenophobia, and mistrust in the authorities, among others. This is a complex problem that needs a holistic approach combining the perspectives of journalists, fact-checkers, policymakers, government entities, social media platforms, and society as a whole. Taking them into account we define an annotation schema and detailed annotation instructions, which reflect these perspectives. We performed initial annotations using this schema, and our initial experiments demonstrated sizable improvements over the baselines. Now, we issue a call to arms to the research community and beyond to join the fight by supporting our crowdsourcing annotation efforts.
Embeddings-Based Clustering for Target Specific Stances: The Case of a Polarized Turkey
May 19, 2020
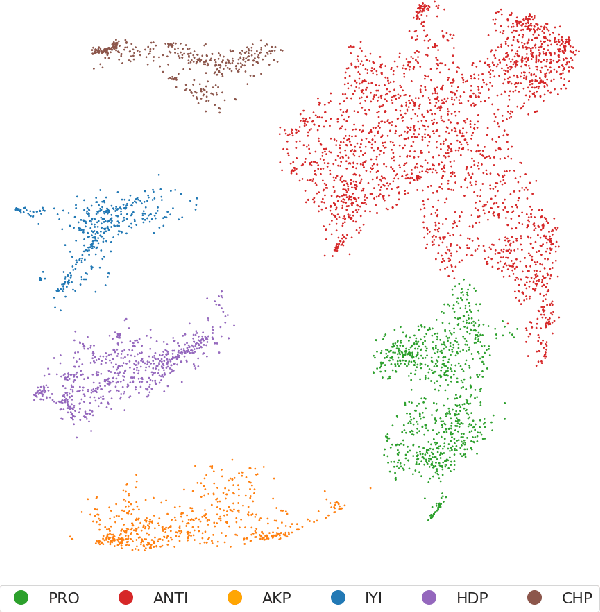
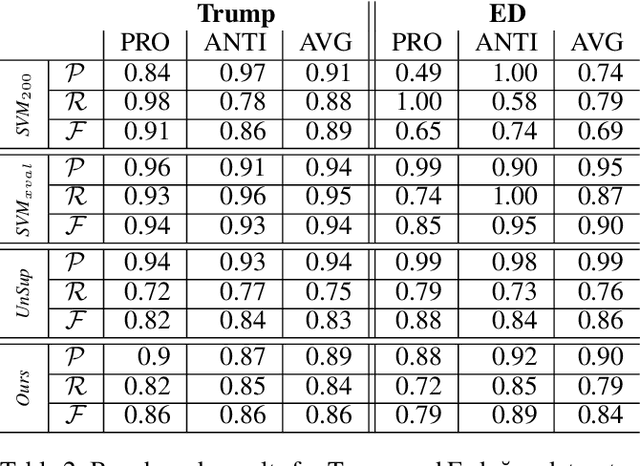
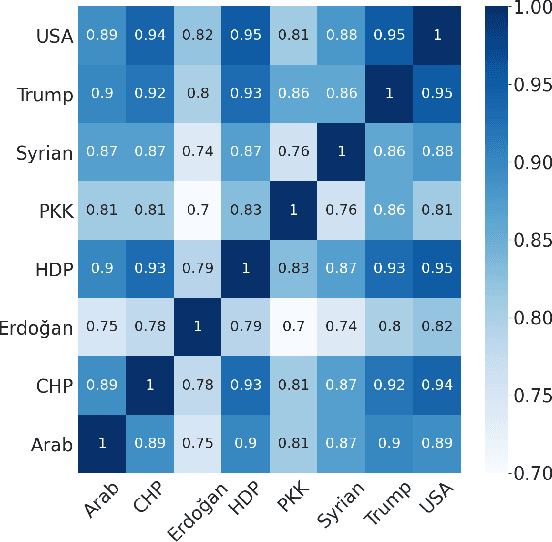
On June 24, 2018, Turkey conducted a highly consequential election in which the Turkish people elected their president and parliament in the first election under a new presidential system. During the election period, the Turkish people extensively shared their political opinions on Twitter. One aspect of polarization among the electorate was support for or opposition to the reelection of Recep Tayyip Erdo\u{g}an. In this paper, we present an unsupervised method for target-specific stance detection in a polarized setting, specifically Turkish politics, achieving 90% precision in identifying user stances, while maintaining more than 80% recall. The method involves representing users in an embedding space using Google's Convolutional Neural Network (CNN) based multilingual universal sentence encoder. The representations are then projected onto a lower dimensional space in a manner that reflects similarities and are consequently clustered. We show the effectiveness of our method in properly clustering users of divergent groups across multiple targets that include political figures, different groups, and parties. We perform our analysis on a large dataset of 108M Turkish election-related tweets along with the timeline tweets of 168k Turkish users, who authored 213M tweets. Given the resultant user stances, we are able to observe correlations between topics and compute topic polarization.
Arabic Dialect Identification in the Wild
May 15, 2020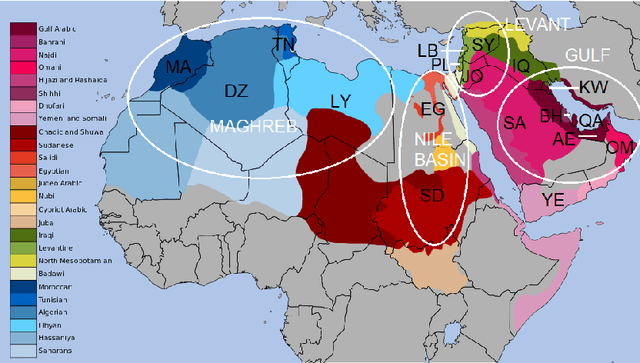
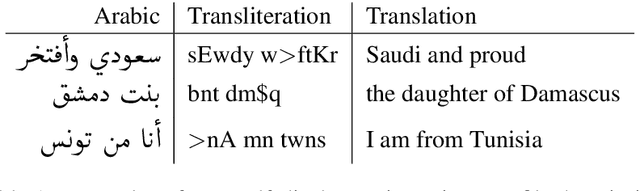

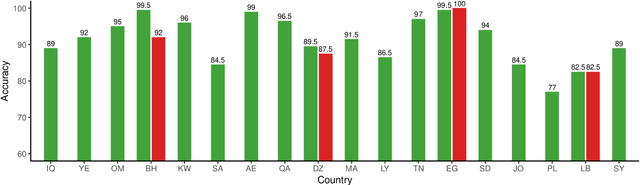
We present QADI, an automatically collected dataset of tweets belonging to a wide range of country-level Arabic dialects -covering 18 different countries in the Middle East and North Africa region. Our method for building this dataset relies on applying multiple filters to identify users who belong to different countries based on their account descriptions and to eliminate tweets that are either written in Modern Standard Arabic or contain inappropriate language. The resultant dataset contains 540k tweets from 2,525 users who are evenly distributed across 18 Arab countries. Using intrinsic evaluation, we show that the labels of a set of randomly selected tweets are 91.5% accurate. For extrinsic evaluation, we are able to build effective country-level dialect identification on tweets with a macro-averaged F1-score of 60.6% across 18 classes.
Fighting the COVID-19 Infodemic: Modeling the Perspective of Journalists, Fact-Checkers, Social Media Platforms, Policy Makers, and the Society
Apr 30, 2020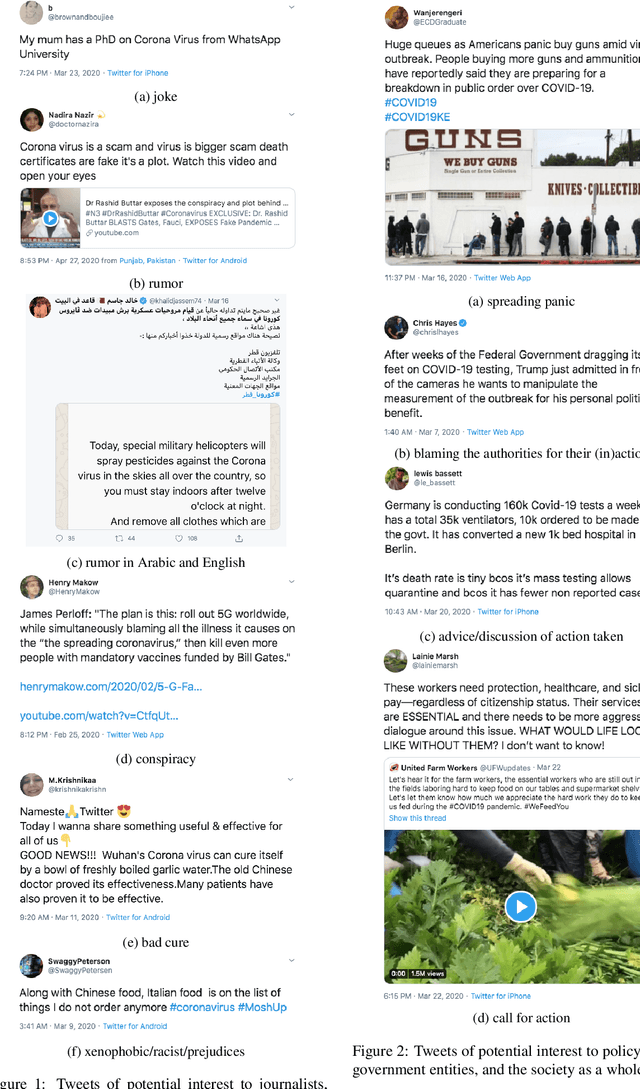
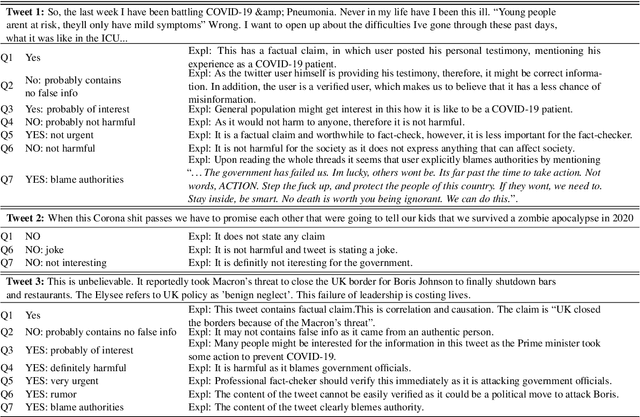

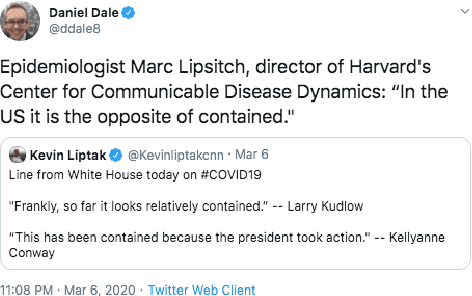
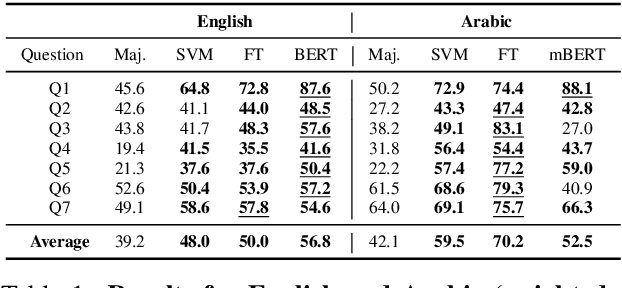
Disinformation, i.e., information that is both false and means harm, thrives in social media. Most often, it is used for political purposes, e.g., to influence elections or simply to cause distrust in society. It can also target medical issues, most notably the use of vaccines. With the emergence of the COVID-19 pandemic, the political and the medical aspects merged as disinformation got elevated to a whole new level to become the first global infodemic. Fighting this infodemic is now ranked second on the list of the most important focus areas of the World Health Organization, with dangers ranging from promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic. The fight requires solving a number of problems such as identifying tweets containing claims, determining their check-worthiness and factuality, and their potential to do harm as well as the nature of that harm, to mention just a few. These are challenging problems, and some of them have been studied previously, but typically in isolation. Here, we design, annotate, and release to the research community a new dataset for fine-grained disinformation analysis that (i) focuses on COVID-19, (ii) combines the perspectives and the interests of journalists, fact-checkers, social media platforms, policy makers, and society as a whole, and (iii) covers both English and Arabic.
A Few Topical Tweets are Enough for Effective User-Level Stance Detection
Apr 07, 2020
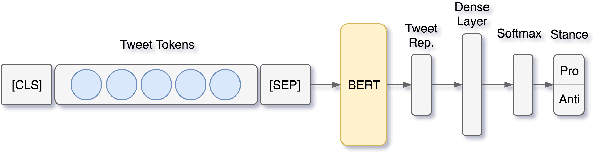
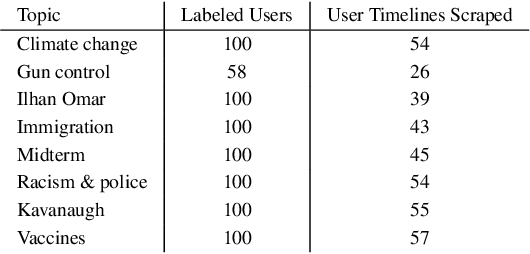
Stance detection entails ascertaining the position of a user towards a target, such as an entity, topic, or claim. Recent work that employs unsupervised classification has shown that performing stance detection on vocal Twitter users, who have many tweets on a target, can yield very high accuracy (+98%). However, such methods perform poorly or fail completely for less vocal users, who may have authored only a few tweets about a target. In this paper, we tackle stance detection for such users using two approaches. In the first approach, we improve user-level stance detection by representing tweets using contextualized embeddings, which capture latent meanings of words in context. We show that this approach outperforms two strong baselines and achieves 89.6% accuracy and 91.3% macro F-measure on eight controversial topics. In the second approach, we expand the tweets of a given user using their Twitter timeline tweets, and then we perform unsupervised classification of the user, which entails clustering a user with other users in the training set. This approach achieves 95.6% accuracy and 93.1% macro F-measure.
Arabic Offensive Language on Twitter: Analysis and Experiments
Apr 05, 2020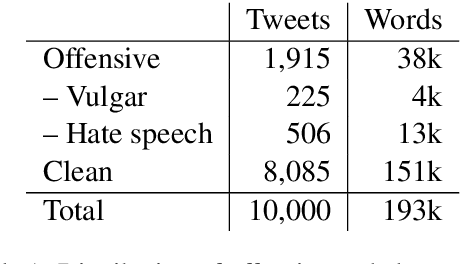
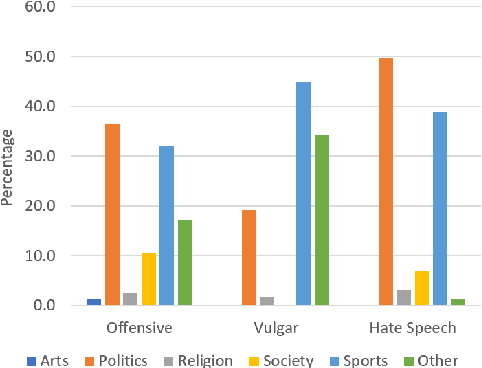
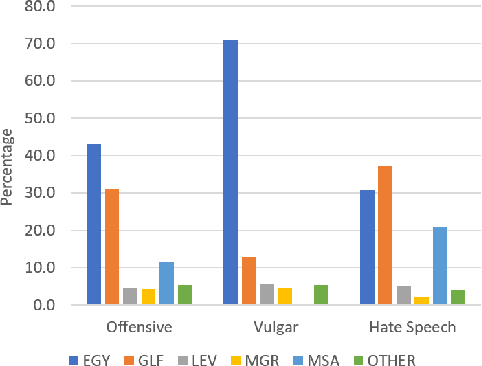
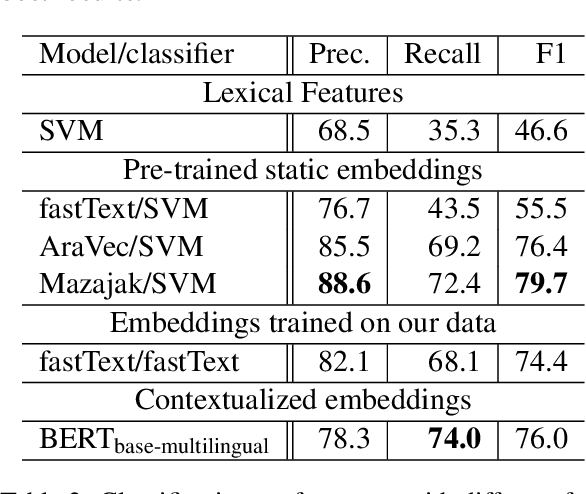
Detecting offensive language on Twitter has many applications ranging from detecting/predicting bullying to measuring polarization. In this paper, we focus on building effective Arabic offensive tweet detection. We introduce a method for building an offensive dataset that is not biased by topic, dialect, or target. We produce the largest Arabic dataset to date with special tags for vulgarity and hate speech. Next, we analyze the dataset to determine which topics, dialects, and gender are most associated with offensive tweets and how Arabic speakers use offensive language. Lastly, we conduct a large battery of experiments to produce strong results (F1 = 79.7) on the dataset using Support Vector Machine techniques.