 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Multimodal Machine Learning: Datasets, Applications, Approaches, and Challenges
Aug 17, 2025Multimodal Machine Learning (MML) aims to integrate and analyze information from diverse modalities, such as text, audio, and visuals, enabling machines to address complex tasks like sentiment analysis, emotion recognition, and multimedia retrieval. Recently, Arabic MML has reached a certain level of maturity in its foundational development, making it time to conduct a comprehensive survey. This paper explores Arabic MML by categorizing efforts through a novel taxonomy and analyzing existing research. Our taxonomy organizes these efforts into four key topics: datasets, applications, approaches, and challenges. By providing a structured overview, this survey offers insights into the current state of Arabic MML, highlighting areas that have not been investigated and critical research gaps. Researchers will be empowered to build upon the identified opportunities and address challenges to advance the field.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
ALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
Exploring Alignment in Shared Cross-lingual Spaces
May 23, 2024



Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the \textit{alignment} and \textit{overlap} of these concepts across various languages within the latent space. To this end, we introduce two metrics \CA{} and \CO{} aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (\texttt{mT5}, \texttt{mBERT}, and \texttt{XLM-R}) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual \textit{alignment} due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances \textit{alignment} within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.\footnote{The code is available at \url{https://github.com/baselmousi/multilingual-latent-concepts}}
LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
Aug 09, 2023


The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework. Initially developed to evaluate Arabic NLP tasks using OpenAI's GPT and BLOOM models; it can be seamlessly customized for any NLP task and model, regardless of language. The framework also features zero- and few-shot learning settings. A new custom dataset can be added in less than 10 minutes, and users can use their own model API keys to evaluate the task at hand. The developed framework has been already tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We plan to open-source the framework for the community (https://github.com/qcri/LLMeBench/). A video demonstrating the framework is available online (https://youtu.be/FkQn4UjYA0s).
Benchmarking Arabic AI with Large Language Models
May 24, 2023With large Foundation Models (FMs), language technologies (AI in general) are entering a new paradigm: eliminating the need for developing large-scale task-specific datasets and supporting a variety of tasks through set-ups ranging from zero-shot to few-shot learning. However, understanding FMs capabilities requires a systematic benchmarking effort by comparing FMs performance with the state-of-the-art (SOTA) task-specific models. With that goal, past work focused on the English language and included a few efforts with multiple languages. Our study contributes to ongoing research by evaluating FMs performance for standard Arabic NLP and Speech processing, including a range of tasks from sequence tagging to content classification across diverse domains. We start with zero-shot learning using GPT-3.5-turbo, Whisper, and USM, addressing 33 unique tasks using 59 publicly available datasets resulting in 96 test setups. For a few tasks, FMs performs on par or exceeds the performance of the SOTA models but for the majority it under-performs. Given the importance of prompt for the FMs performance, we discuss our prompt strategies in detail and elaborate on our findings. Our future work on Arabic AI will explore few-shot prompting, expand the range of tasks, and investigate additional open-source models.
Post-hoc analysis of Arabic transformer models
Oct 18, 2022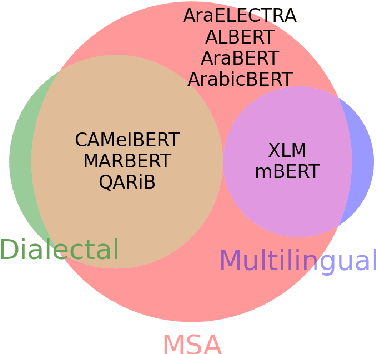
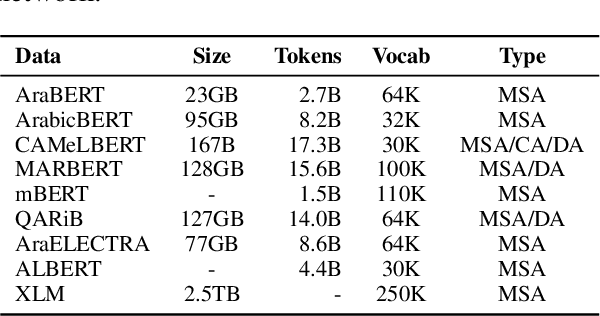

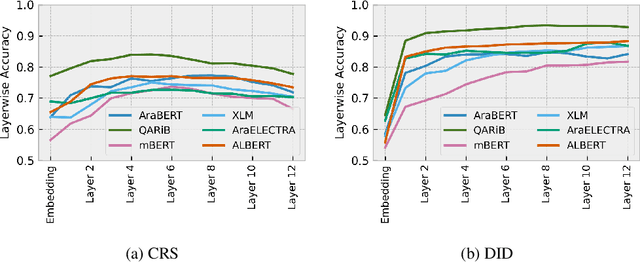
Arabic is a Semitic language which is widely spoken with many dialects. Given the success of pre-trained language models, many transformer models trained on Arabic and its dialects have surfaced. While there have been an extrinsic evaluation of these models with respect to downstream NLP tasks, no work has been carried out to analyze and compare their internal representations. We probe how linguistic information is encoded in the transformer models, trained on different Arabic dialects. We perform a layer and neuron analysis on the models using morphological tagging tasks for different dialects of Arabic and a dialectal identification task. Our analysis enlightens interesting findings such as: i) word morphology is learned at the lower and middle layers, ii) while syntactic dependencies are predominantly captured at the higher layers, iii) despite a large overlap in their vocabulary, the MSA-based models fail to capture the nuances of Arabic dialects, iv) we found that neurons in embedding layers are polysemous in nature, while the neurons in middle layers are exclusive to specific properties
NatiQ: An End-to-end Text-to-Speech System for Arabic
Jun 15, 2022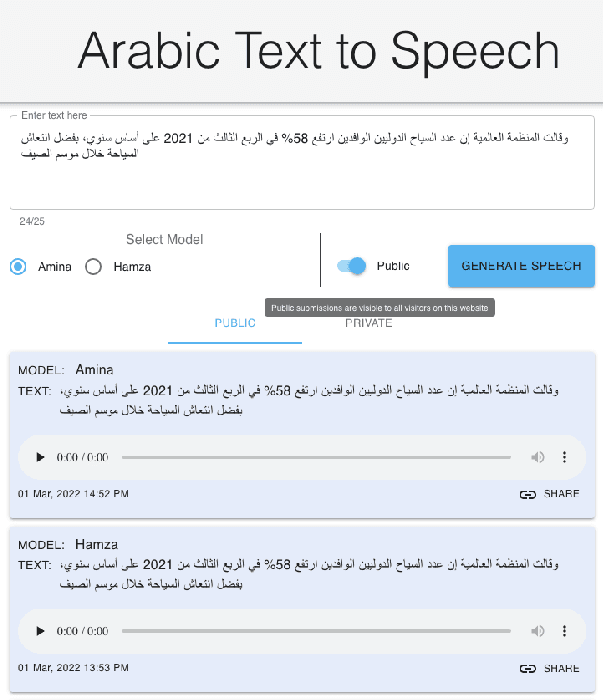
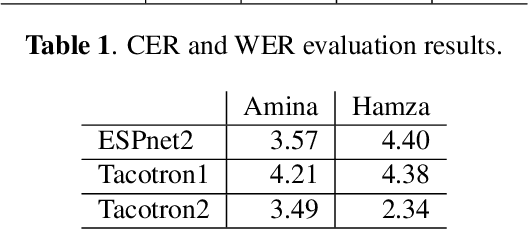
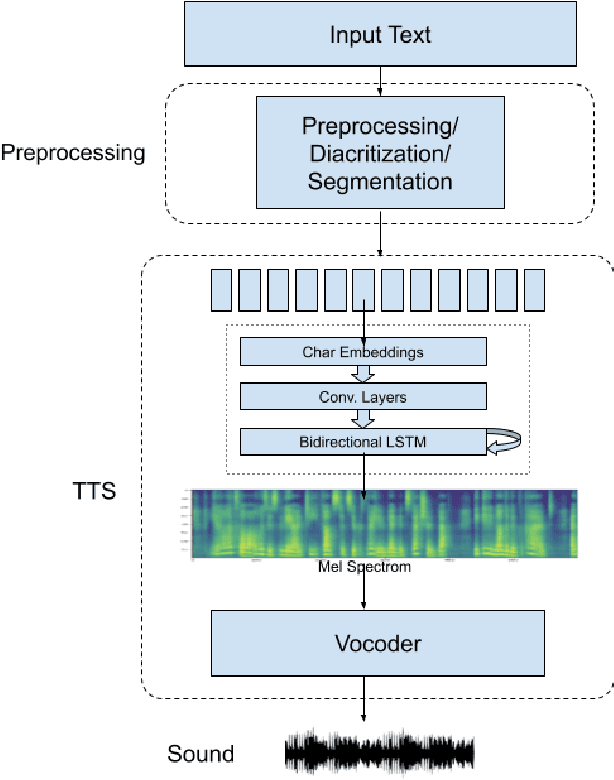
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron-1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neutral male "Hamza"- narrating general content and news, and 2) expressive female "Amina"- narrating children story books to train our models. Our best systems achieve an average Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real-time factor favored the end-to-end architecture ESPnet. NatiQ demo is available on-line at https://tts.qcri.org
Interpreting Arabic Transformer Models
Jan 19, 2022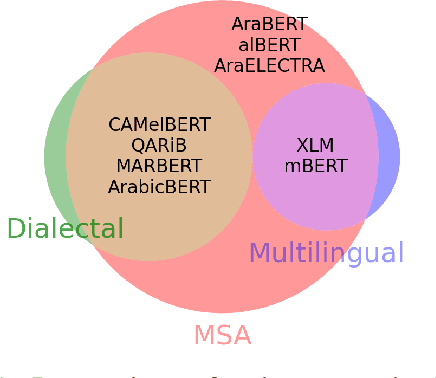
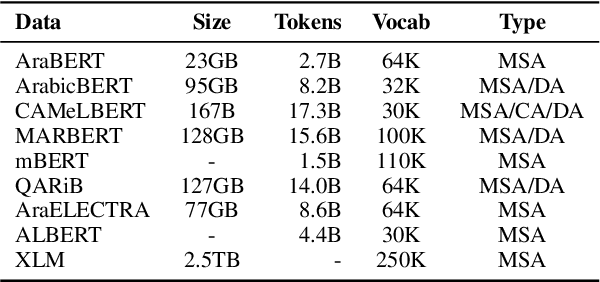
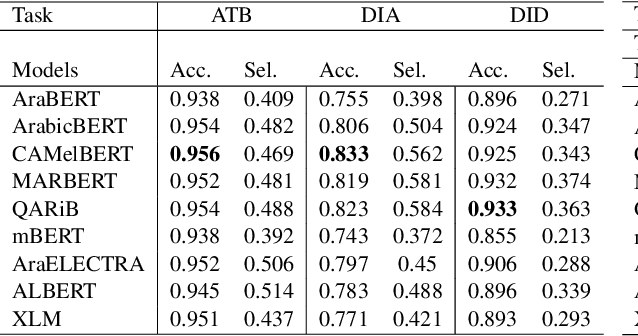
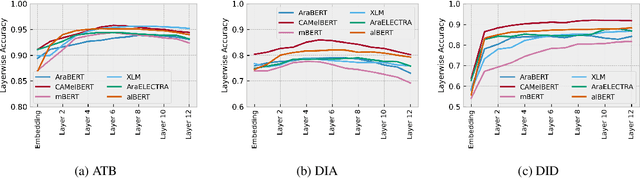
Arabic is a Semitic language which is widely spoken with many dialects. Given the success of pre-trained language models, many transformer models trained on Arabic and its dialects have surfaced. While these models have been compared with respect to downstream NLP tasks, no evaluation has been carried out to directly compare the internal representations. We probe how linguistic information is encoded in Arabic pretrained models, trained on different varieties of Arabic language. We perform a layer and neuron analysis on the models using three intrinsic tasks: two morphological tagging tasks based on MSA (modern standard Arabic) and dialectal POS-tagging and a dialectal identification task. Our analysis enlightens interesting findings such as: i) word morphology is learned at the lower and middle layers ii) dialectal identification necessitate more knowledge and hence preserved even in the final layers, iii) despite a large overlap in their vocabulary, the MSA-based models fail to capture the nuances of Arabic dialects, iv) we found that neurons in embedding layers are polysemous in nature, while the neurons in middle layers are exclusive to specific properties.
Code-Switching Text Augmentation for Multilingual Speech Processing
Jan 07, 2022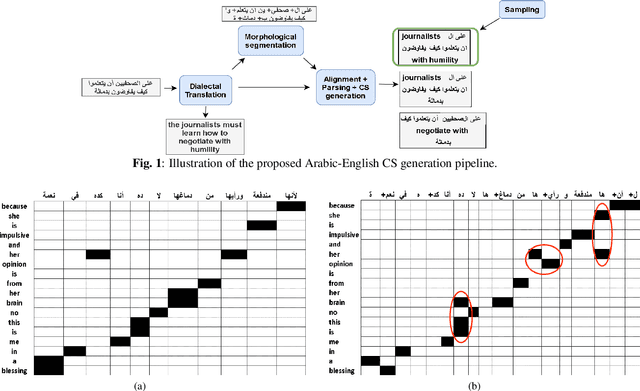
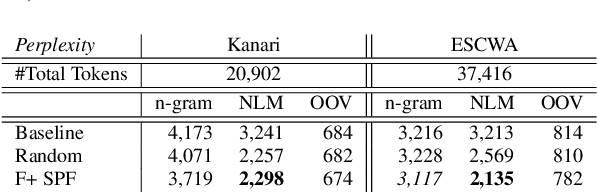
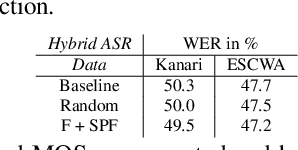
The pervasiveness of intra-utterance Code-switching (CS) in spoken content has enforced ASR systems to handle mixed input. Yet, designing a CS-ASR has many challenges, mainly due to the data scarcity, grammatical structure complexity, and mismatch along with unbalanced language usage distribution. Recent ASR studies showed the predominance of E2E-ASR using multilingual data to handle CS phenomena with little CS data. However, the dependency on the CS data still remains. In this work, we propose a methodology to augment the monolingual data for artificially generating spoken CS text to improve different speech modules. We based our approach on Equivalence Constraint theory while exploiting aligned translation pairs, to generate grammatically valid CS content. Our empirical results show a relative gain of 29-34 % in perplexity and around 2% in WER for two ecological and noisy CS test sets. Finally, the human evaluation suggests that 83.8% of the generated data is acceptable to humans.