 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Rare Spurious Correlations in Neural Networks
Feb 10, 2022
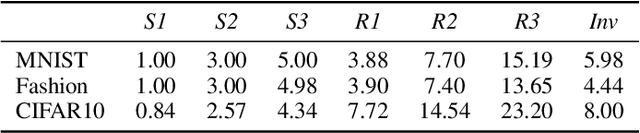
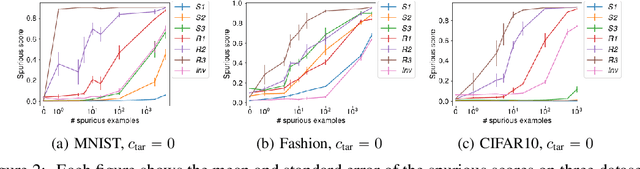
Neural networks are known to use spurious correlations for classification; for example, they commonly use background information to classify objects. But how many examples does it take for a network to pick up these correlations? This is the question that we empirically investigate in this work. We introduce spurious patterns correlated with a specific class to a few examples and find that it takes only a handful of such examples for the network to pick up on the spurious correlation. Through extensive experiments, we show that (1) spurious patterns with a larger $\ell_2$ norm are learnt to correlate with the specified class more easily; (2) network architectures that are more sensitive to the input are more susceptible to learning these rare spurious correlations; (3) standard data deletion methods, including incremental retraining and influence functions, are unable to forget these rare spurious correlations through deleting the examples that cause these spurious correlations to be learnt. Code available at https://github.com/yangarbiter/rare-spurious-correlation.
Bounding Training Data Reconstruction in Private (Deep) Learning
Jan 28, 2022

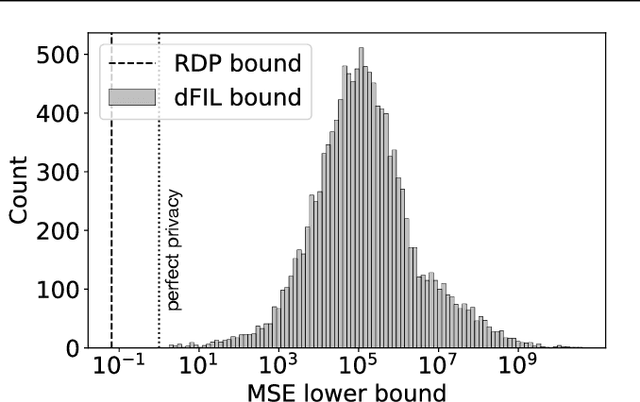

Differential privacy is widely accepted as the de facto method for preventing data leakage in ML, and conventional wisdom suggests that it offers strong protection against privacy attacks. However, existing semantic guarantees for DP focus on membership inference, which may overestimate the adversary's capabilities and is not applicable when membership status itself is non-sensitive. In this paper, we derive the first semantic guarantees for DP mechanisms against training data reconstruction attacks under a formal threat model. We show that two distinct privacy accounting methods -- Renyi differential privacy and Fisher information leakage -- both offer strong semantic protection against data reconstruction attacks.
Privacy Amplification by Subsampling in Time Domain
Jan 13, 2022
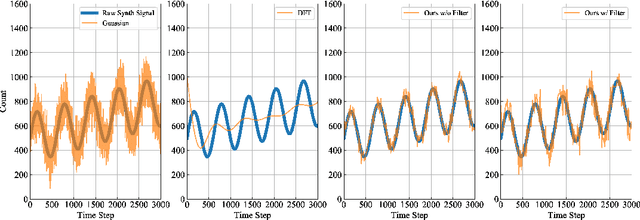

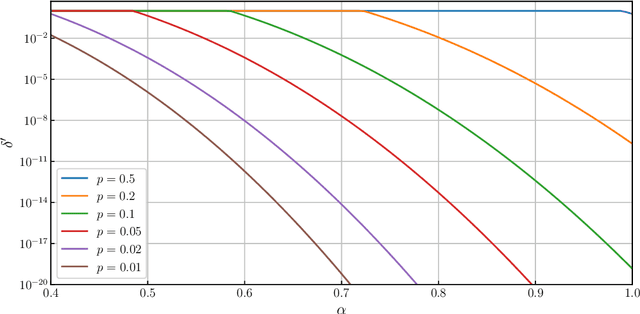
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
Privacy Amplification via Shuffling for Linear Contextual Bandits
Dec 11, 2021
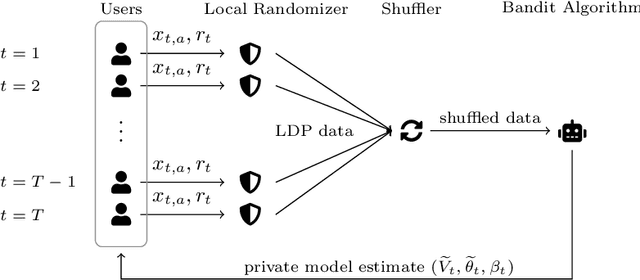
Contextual bandit algorithms are widely used in domains where it is desirable to provide a personalized service by leveraging contextual information, that may contain sensitive information that needs to be protected. Inspired by this scenario, we study the contextual linear bandit problem with differential privacy (DP) constraints. While the literature has focused on either centralized (joint DP) or local (local DP) privacy, we consider the shuffle model of privacy and we show that is possible to achieve a privacy/utility trade-off between JDP and LDP. By leveraging shuffling from privacy and batching from bandits, we present an algorithm with regret bound $\widetilde{\mathcal{O}}(T^{2/3}/\varepsilon^{1/3})$, while guaranteeing both central (joint) and local privacy. Our result shows that it is possible to obtain a trade-off between JDP and LDP by leveraging the shuffle model while preserving local privacy.
Behavior of k-NN as an Instance-Based Explanation Method
Sep 14, 2021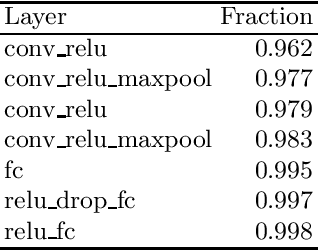

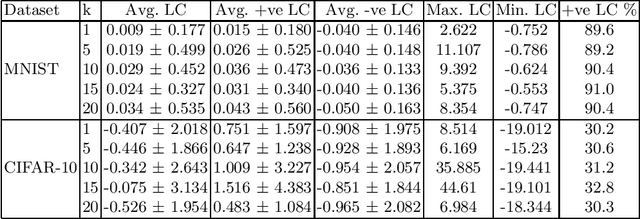
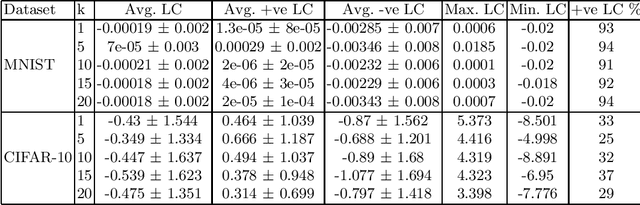
Adoption of DL models in critical areas has led to an escalating demand for sound explanation methods. Instance-based explanation methods are a popular type that return selective instances from the training set to explain the predictions for a test sample. One way to connect these explanations with prediction is to ask the following counterfactual question - how does the loss and prediction for a test sample change when explanations are removed from the training set? Our paper answers this question for k-NNs which are natural contenders for an instance-based explanation method. We first demonstrate empirically that the representation space induced by last layer of a neural network is the best to perform k-NN in. Using this layer, we conduct our experiments and compare them to influence functions (IFs) ~\cite{koh2017understanding} which try to answer a similar question. Our evaluations do indicate change in loss and predictions when explanations are removed but we do not find a trend between $k$ and loss or prediction change. We find significant stability in the predictions and loss of MNIST vs. CIFAR-10. Surprisingly, we do not observe much difference in the behavior of k-NNs vs. IFs on this question. We attribute this to training set subsampling for IFs.
A Shuffling Framework for Local Differential Privacy
Jun 11, 2021
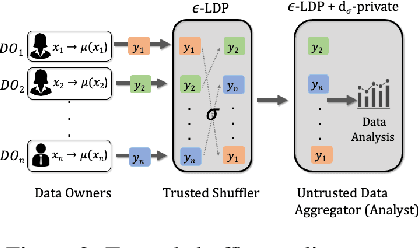
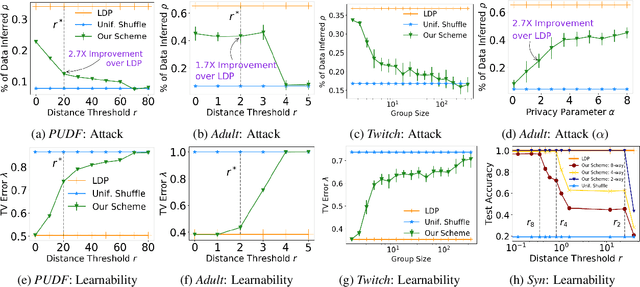
ldp deployments are vulnerable to inference attacks as an adversary can link the noisy responses to their identity and subsequently, auxiliary information using the order of the data. An alternative model, shuffle DP, prevents this by shuffling the noisy responses uniformly at random. However, this limits the data learnability -- only symmetric functions (input order agnostic) can be learned. In this paper, we strike a balance and propose a generalized shuffling framework that interpolates between the two deployment models. We show that systematic shuffling of the noisy responses can thwart specific inference attacks while retaining some meaningful data learnability. To this end, we propose a novel privacy guarantee, d-sigma privacy, that captures the privacy of the order of a data sequence. d-sigma privacy allows tuning the granularity at which the ordinal information is maintained, which formalizes the degree the resistance to inference attacks trading it off with data learnability. Additionally, we propose a novel shuffling mechanism that can achieve d-sigma privacy and demonstrate the practicality of our mechanism via evaluation on real-world datasets.
Understanding Instance-based Interpretability of Variational Auto-Encoders
May 29, 2021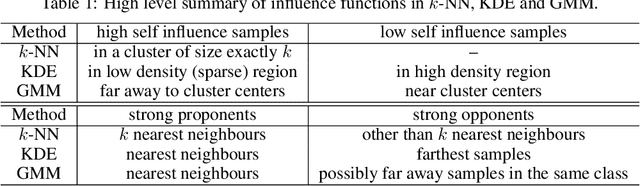

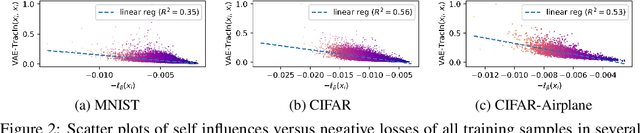
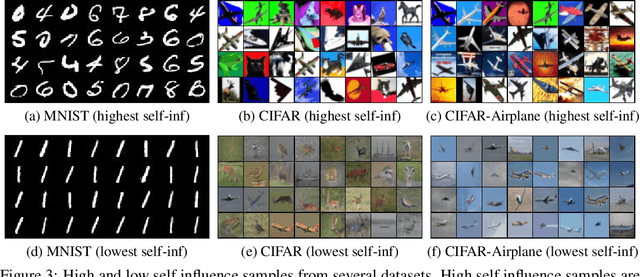
Instance-based interpretation methods have been widely studied for supervised learning methods as they help explain how black box neural networks predict. However, instance-based interpretations remain ill-understood in the context of unsupervised learning. In this paper, we investigate influence functions [20], a popular instance-based interpretation method, for a class of deep generative models called variational auto-encoders (VAE). We formally frame the counter-factual question answered by influence functions in this setting, and through theoretical analysis, examine what they reveal about the impact of training samples on classical unsupervised learning methods. We then introduce VAE-TracIn, a computationally efficient and theoretically sound solution based on Pruthi et al. [28], for VAEs. Finally, we evaluate VAE-TracIn on several real world datasets with extensive quantitative and qualitative analysis.
Privacy Amplification Via Bernoulli Sampling
May 21, 2021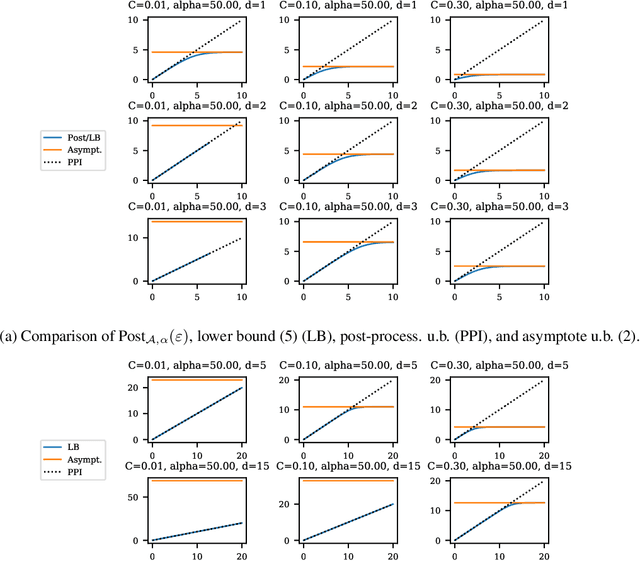
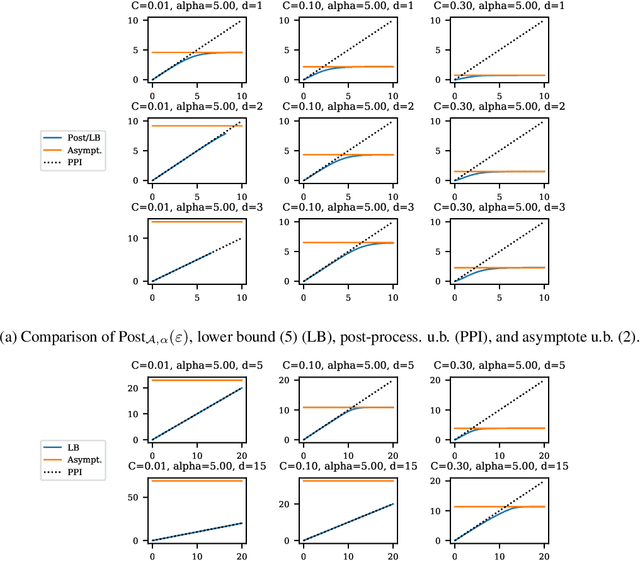
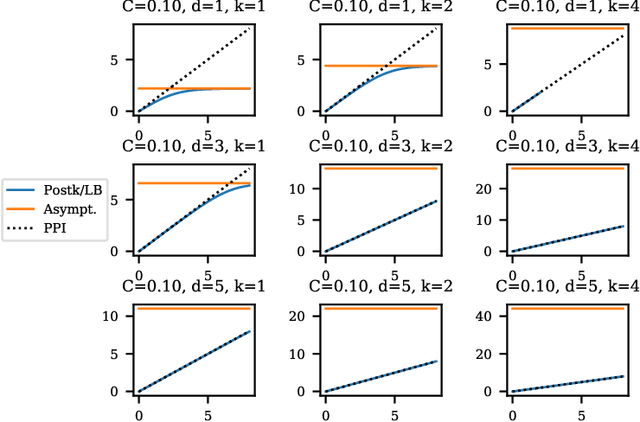
Balancing privacy and accuracy is a major challenge in designing differentially private machine learning algorithms. To improve this tradeoff, prior work has looked at privacy amplification methods which analyze how common training operations such as iteration and subsampling the data can lead to higher privacy. In this paper, we analyze privacy amplification properties of a new operation, sampling from the posterior, that is used in Bayesian inference. In particular, we look at Bernoulli sampling from a posterior that is described by a differentially private parameter. We provide an algorithm to compute the amplification factor in this setting, and establish upper and lower bounds on this factor. Finally, we look at what happens when we draw k posterior samples instead of one.
Universal Approximation of Residual Flows in Maximum Mean Discrepancy
Mar 10, 2021Normalizing flows are a class of flexible deep generative models that offer easy likelihood computation. Despite their empirical success, there is little theoretical understanding of their expressiveness. In this work, we study residual flows, a class of normalizing flows composed of Lipschitz residual blocks. We prove residual flows are universal approximators in maximum mean discrepancy. We provide upper bounds on the number of residual blocks to achieve approximation under different assumptions.
Location Trace Privacy Under Conditional Priors
Feb 23, 2021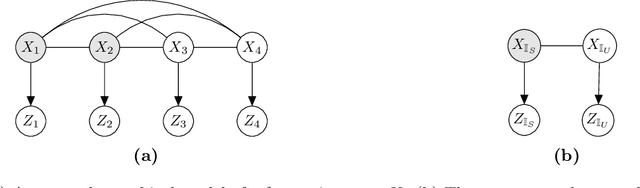
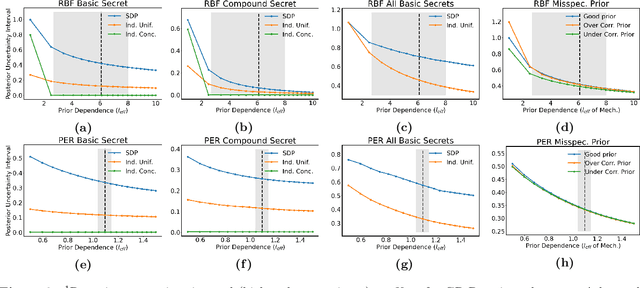
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a R\'enyi divergence based privacy framework for bounding expected privacy loss for conditionally dependent data. Additionally, we demonstrate an algorithm for achieving this privacy under Gaussian process conditional priors. This framework both exemplifies why conditionally dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user's trace.