 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Apr 12, 2022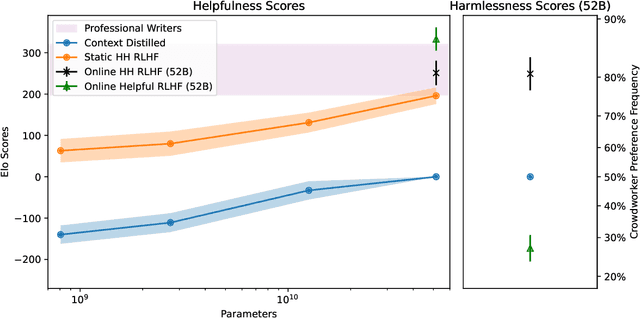
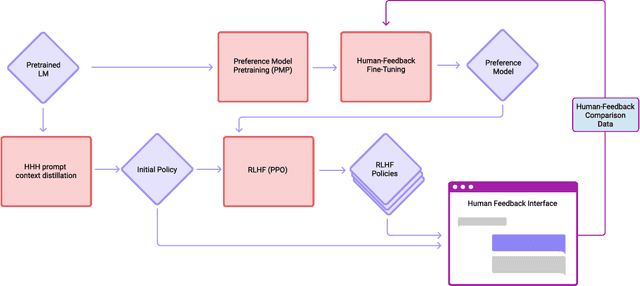
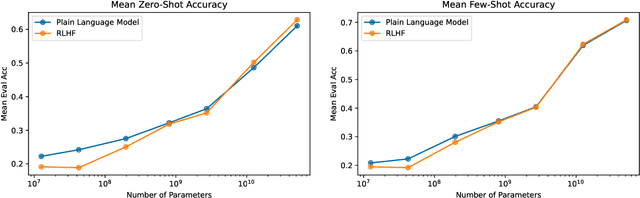
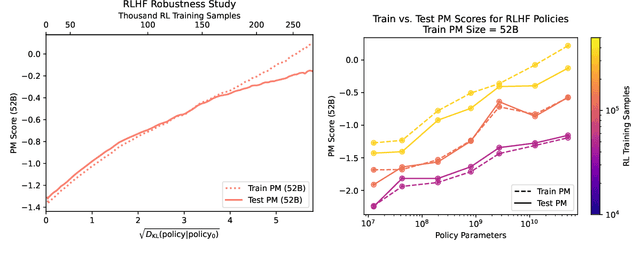
We apply preference modeling and reinforcement learning from human feedback (RLHF) to finetune language models to act as helpful and harmless assistants. We find this alignment training improves performance on almost all NLP evaluations, and is fully compatible with training for specialized skills such as python coding and summarization. We explore an iterated online mode of training, where preference models and RL policies are updated on a weekly cadence with fresh human feedback data, efficiently improving our datasets and models. Finally, we investigate the robustness of RLHF training, and identify a roughly linear relation between the RL reward and the square root of the KL divergence between the policy and its initialization. Alongside our main results, we perform peripheral analyses on calibration, competing objectives, and the use of OOD detection, compare our models with human writers, and provide samples from our models using prompts appearing in recent related work.
A General Language Assistant as a Laboratory for Alignment
Dec 09, 2021
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a `preference model pre-training' stage of training, with the goal of improving sample efficiency when finetuning on human preferences.
Multi-agent Social Reinforcement Learning Improves Generalization
Oct 01, 2020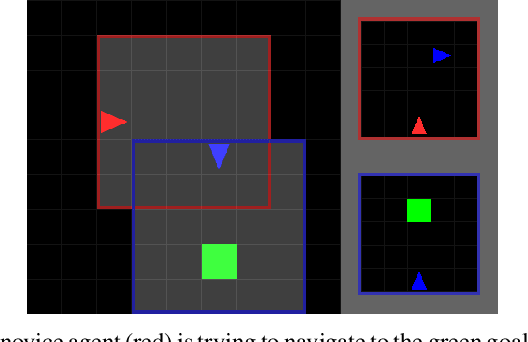
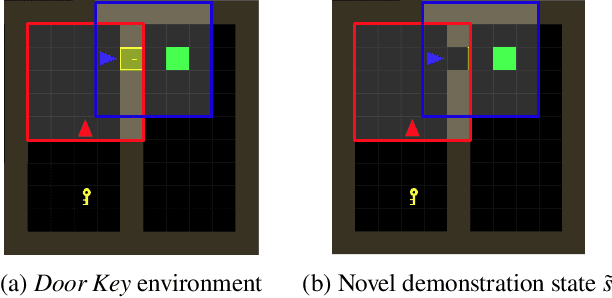
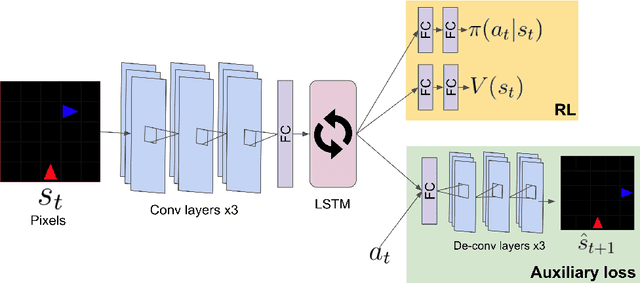
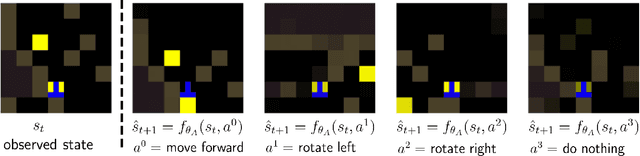
Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can use social learning to improve their performance using cues from other agents. We find that in most circumstances, vanilla model-free RL agents do not use social learning, even in environments in which individual exploration is expensive. We analyze the reasons for this deficiency, and show that by introducing a model-based auxiliary loss we are able to train agents to lever-age cues from experts to solve hard exploration tasks. The generalized social learning policy learned by these agents allows them to not only outperform the experts with which they trained, but also achieve better zero-shot transfer performance than solo learners when deployed to novel environments with experts. In contrast, agents that have not learned to rely on social learning generalize poorly and do not succeed in the transfer task. Further,we find that by mixing multi-agent and solo training, we can obtain agents that use social learning to out-perform agents trained alone, even when experts are not avail-able. This demonstrates that social learning has helped improve agents' representation of the task itself. Our results indicate that social learning can enable RL agents to not only improve performance on the task at hand, but improve generalization to novel environments.