 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDAE: Dual Attention Mechanism in a Hierarchical Transformer for Efficient Medical Image Segmentation
Sep 03, 2024



In healthcare, medical image segmentation is crucial for accurate disease diagnosis and the development of effective treatment strategies. Early detection can significantly aid in managing diseases and potentially prevent their progression. Machine learning, particularly deep convolutional neural networks, has emerged as a promising approach to addressing segmentation challenges. Traditional methods like U-Net use encoding blocks for local representation modeling and decoding blocks to uncover semantic relationships. However, these models often struggle with multi-scale objects exhibiting significant variations in texture and shape, and they frequently fail to capture long-range dependencies in the input data. Transformers designed for sequence-to-sequence predictions have been proposed as alternatives, utilizing global self-attention mechanisms. Yet, they can sometimes lack precise localization due to insufficient granular details. To overcome these limitations, we introduce TransDAE: a novel approach that reimagines the self-attention mechanism to include both spatial and channel-wise associations across the entire feature space, while maintaining computational efficiency. Additionally, TransDAE enhances the skip connection pathway with an inter-scale interaction module, promoting feature reuse and improving localization accuracy. Remarkably, TransDAE outperforms existing state-of-the-art methods on the Synaps multi-organ dataset, even without relying on pre-trained weights.
Stock Movement and Volatility Prediction from Tweets, Macroeconomic Factors and Historical Prices
Dec 04, 2023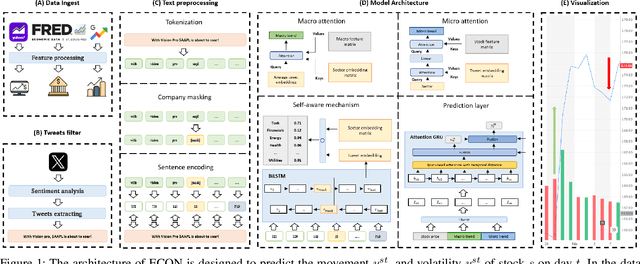
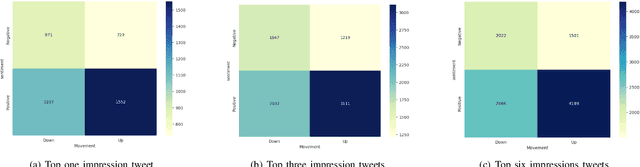

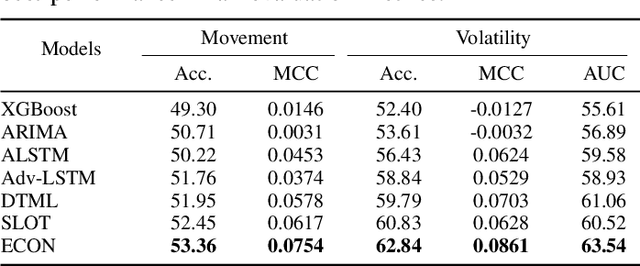
Predicting stock market is vital for investors and policymakers, acting as a barometer of the economic health. We leverage social media data, a potent source of public sentiment, in tandem with macroeconomic indicators as government-compiled statistics, to refine stock market predictions. However, prior research using tweet data for stock market prediction faces three challenges. First, the quality of tweets varies widely. While many are filled with noise and irrelevant details, only a few genuinely mirror the actual market scenario. Second, solely focusing on the historical data of a particular stock without considering its sector can lead to oversight. Stocks within the same industry often exhibit correlated price behaviors. Lastly, simply forecasting the direction of price movement without assessing its magnitude is of limited value, as the extent of the rise or fall truly determines profitability. In this paper, diverging from the conventional methods, we pioneer an ECON. The framework has following advantages: First, ECON has an adept tweets filter that efficiently extracts and decodes the vast array of tweet data. Second, ECON discerns multi-level relationships among stocks, sectors, and macroeconomic factors through a self-aware mechanism in semantic space. Third, ECON offers enhanced accuracy in predicting substantial stock price fluctuations by capitalizing on stock price movement. We showcase the state-of-the-art performance of our proposed model using a dataset, specifically curated by us, for predicting stock market movements and volatility.
ALERTA-Net: A Temporal Distance-Aware Recurrent Networks for Stock Movement and Volatility Prediction
Oct 28, 2023For both investors and policymakers, forecasting the stock market is essential as it serves as an indicator of economic well-being. To this end, we harness the power of social media data, a rich source of public sentiment, to enhance the accuracy of stock market predictions. Diverging from conventional methods, we pioneer an approach that integrates sentiment analysis, macroeconomic indicators, search engine data, and historical prices within a multi-attention deep learning model, masterfully decoding the complex patterns inherent in the data. We showcase the state-of-the-art performance of our proposed model using a dataset, specifically curated by us, for predicting stock market movements and volatility.
LaTeX: Language Pattern-aware Triggering Event Detection for Adverse Experience during Pandemics
Oct 05, 2023The COVID-19 pandemic has accentuated socioeconomic disparities across various racial and ethnic groups in the United States. While previous studies have utilized traditional survey methods like the Household Pulse Survey (HPS) to elucidate these disparities, this paper explores the role of social media platforms in both highlighting and addressing these challenges. Drawing from real-time data sourced from Twitter, we analyzed language patterns related to four major types of adverse experiences: loss of employment income (LI), food scarcity (FS), housing insecurity (HI), and unmet needs for mental health services (UM). We first formulate a sparsity optimization problem that extracts low-level language features from social media data sources. Second, we propose novel constraints on feature similarity exploiting prior knowledge about the similarity of the language patterns among the adverse experiences. The proposed problem is challenging to solve due to the non-convexity objective and non-smoothness penalties. We develop an algorithm based on the alternating direction method of multipliers (ADMM) framework to solve the proposed formulation. Extensive experiments and comparisons to other models on real-world social media and the detection of adverse experiences justify the efficacy of our model.
DG-Trans: Dual-level Graph Transformer for Spatiotemporal Incident Impact Prediction on Traffic Networks
Mar 21, 2023The prompt estimation of traffic incident impacts can guide commuters in their trip planning and improve the resilience of transportation agencies' decision-making on resilience. However, it is more challenging than node-level and graph-level forecasting tasks, as it requires extracting the anomaly subgraph or sub-time-series from dynamic graphs. In this paper, we propose DG-Trans, a novel traffic incident impact prediction framework, to foresee the impact of traffic incidents through dynamic graph learning. The proposed framework contains a dual-level spatial transformer and an importance-score-based temporal transformer, and the performance of this framework is justified by two newly constructed benchmark datasets. The dual-level spatial transformer removes unnecessary edges between nodes to isolate the affected subgraph from the other nodes. Meanwhile, the importance-score-based temporal transformer identifies abnormal changes in node features, causing the predictions to rely more on measurement changes after the incident occurs. Therefore, DG-Trans is equipped with dual abilities that extract spatiotemporal dependency and identify anomaly nodes affected by incidents while removing noise introduced by benign nodes. Extensive experiments on real-world datasets verify that DG-Trans outperforms the existing state-of-the-art methods, especially in extracting spatiotemporal dependency patterns and predicting traffic accident impacts. It offers promising potential for traffic incident management systems.
Bridging the Gap between Spatial and Spectral Domains: A Unified Framework for Graph Neural Networks
Aug 07, 2021

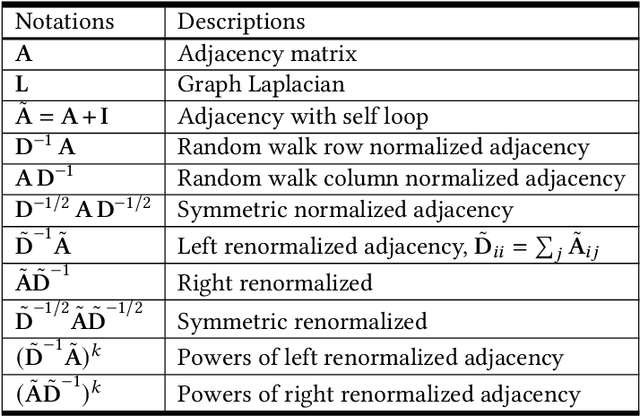
Deep learning's performance has been extensively recognized recently. Graph neural networks (GNNs) are designed to deal with graph-structural data that classical deep learning does not easily manage. Since most GNNs were created using distinct theories, direct comparisons are impossible. Prior research has primarily concentrated on categorizing existing models, with little attention paid to their intrinsic connections. The purpose of this study is to establish a unified framework that integrates GNNs based on spectral graph and approximation theory. The framework incorporates a strong integration between spatial- and spectral-based GNNs while tightly associating approaches that exist within each respective domain.
Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks
Mar 01, 2020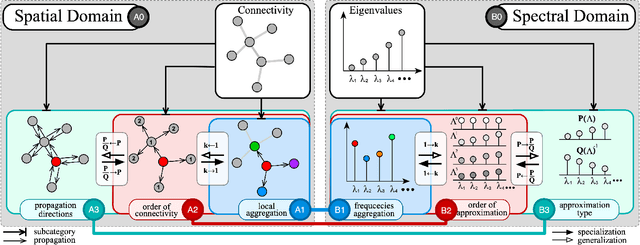
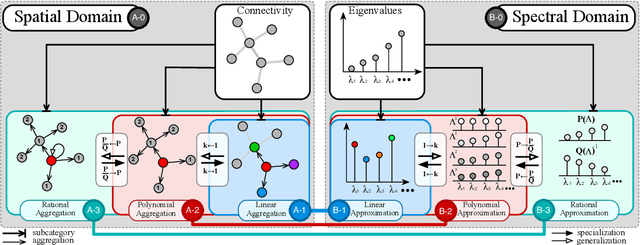
The success of deep learning has been widely recognized in many machine learning tasks during the last decades, ranging from image classification and speech recognition to natural language understanding. As an extension of deep learning, Graph neural networks (GNNs) are designed to solve the non-Euclidean problems on graph-structured data which can hardly be handled by general deep learning techniques. Existing GNNs under various mechanisms, such as random walk, PageRank, graph convolution, and heat diffusion, are designed for different types of graphs and problems, which makes it difficult to compare them directly. Previous GNN surveys focus on categorizing current models into independent groups, lacking analysis regarding their internal connection. This paper proposes a unified framework and provides a novel perspective that can widely fit existing GNNs into our framework methodologically. Specifically, we survey and categorize existing GNN models into the spatial and spectral domains, and reveal connections among subcategories in each domain. Further analysis establishes a strong link across the spatial and spectral domains.
TITAN: A Spatiotemporal Feature Learning Framework for Traffic Incident Duration Prediction
Nov 20, 2019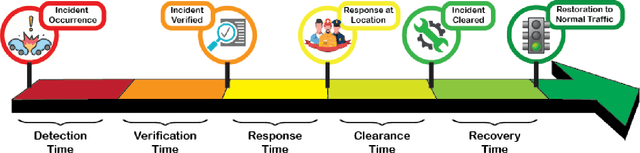
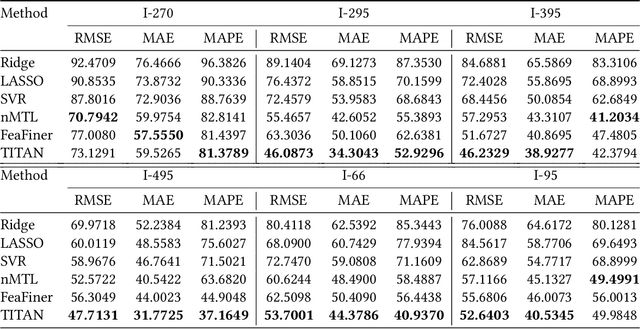
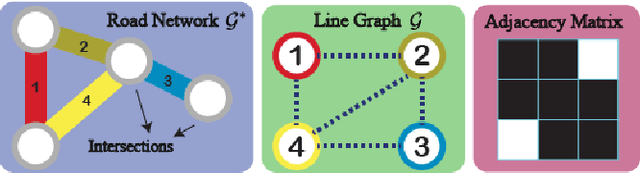
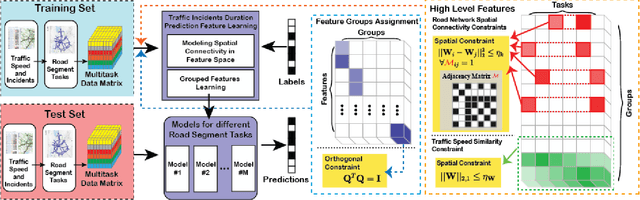
Critical incident stages identification and reasonable prediction of traffic incident duration are essential in traffic incident management. In this paper, we propose a traffic incident duration prediction model that simultaneously predicts the impact of the traffic incidents and identifies the critical groups of temporal features via a multi-task learning framework. First, we formulate a sparsity optimization problem that extracts low-level temporal features based on traffic speed readings and then generalizes higher level features as phases of traffic incidents. Second, we propose novel constraints on feature similarity exploiting prior knowledge about the spatial connectivity of the road network to predict the incident duration. The proposed problem is challenging to solve due to the orthogonality constraints, non-convexity objective, and non-smoothness penalties. We develop an algorithm based on the alternating direction method of multipliers (ADMM) framework to solve the proposed formulation. Extensive experiments and comparisons to other models on real-world traffic data and traffic incident records justify the efficacy of our model.
Patent Citation Dynamics Modeling via Multi-Attention Recurrent Networks
May 22, 2019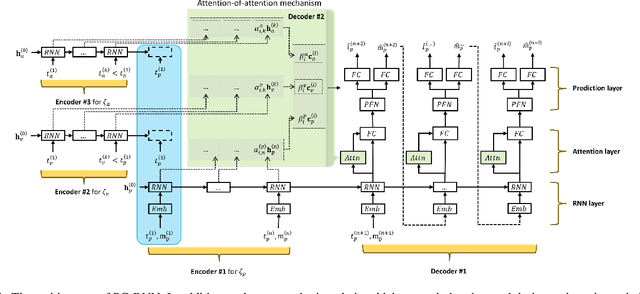
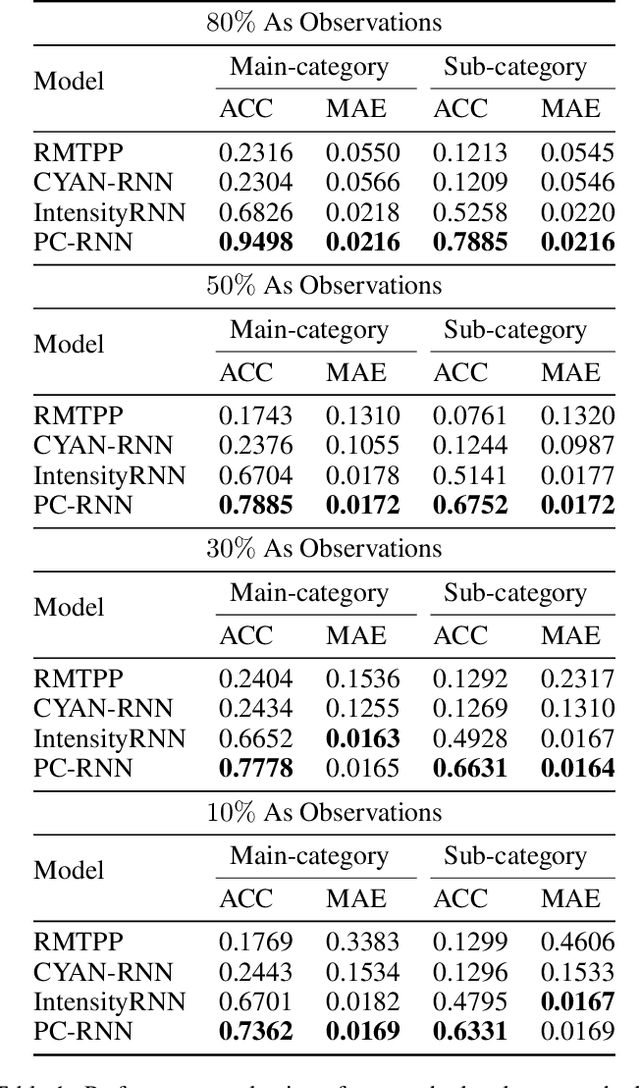
Modeling and forecasting forward citations to a patent is a central task for the discovery of emerging technologies and for measuring the pulse of inventive progress. Conventional methods for forecasting these forward citations cast the problem as analysis of temporal point processes which rely on the conditional intensity of previously received citations. Recent approaches model the conditional intensity as a chain of recurrent neural networks to capture memory dependency in hopes of reducing the restrictions of the parametric form of the intensity function. For the problem of patent citations, we observe that forecasting a patent's chain of citations benefits from not only the patent's history itself but also from the historical citations of assignees and inventors associated with that patent. In this paper, we propose a sequence-to-sequence model which employs an attention-of-attention mechanism to capture the dependencies of these multiple time sequences. Furthermore, the proposed model is able to forecast both the timestamp and the category of a patent's next citation. Extensive experiments on a large patent citation dataset collected from USPTO demonstrate that the proposed model outperforms state-of-the-art models at forward citation forecasting.