 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Native Games: A Survey and Roadmap
Jul 01, 2026Generative AI now enables games to produce dialogue, quests, characters, images, and worlds at runtime. Yet generation alone does not make a game AI-native, nor does it guarantee playability. This paper defines AI-native games by whether runtime generative AI is constitutive of the core loop: if the AI component were removed or trivially replaced, the central form of play would collapse or become fundamentally different. This counterfactual criterion separates AI-native games from AI-augmented games, boundary artifacts, chatbots, tavern-style role-play, procedural content generation, and AI-assisted production. Using this definition, we screen candidate artifacts and analyze 53 publicly available AI-native games and prototypes. We introduce a dual-axis G/N taxonomy: the G-axis captures player-facing game type, while the N-axis captures the dominant AI mechanic that makes generative AI indispensable to play. The corpus is concentrated around language-forward designs, especially narrative adventure, epistemic interaction, and generative narrative, while categories such as semantic adjudication, multi-agent simulation, generative construction, and relationship/companion play remain less represented. We argue that the central design problem is organizing semantic openness into stable gameplay. AI-native design depends on mechanical invariants: goals, rules, state, feedback, pacing, and player agency that make open-ended AI outputs interpretable and consequential. We conclude with a roadmap for controllable generation, AI-as-mechanic design, multimodal and multi-agent systems, inference economics, evaluation, safety, and regulation.
Navigating the Safety-Fidelity Trade-off: Massive-Variate Time Series Forecasting for Power Systems via Probabilistic Scenarios
Jun 11, 2026Probabilistic forecasting models are increasingly deployed on multivariate systems with distinct channel physics and operational constraints, but existing benchmarks evaluate neither property at scale. Public canonical multivariate benchmarks cap out at 2,000 channels, while power-system benchmarks either lack temporal structure or probabilistic evaluation. We introduce PowerPhase, a probabilistic forecasting benchmark built on six transmission grids ranging from 2,000 to 36,964 jointly forecasted channels, more than an order of magnitude beyond popular canonical multivariate benchmarks. Each target trajectory is the output of an AC power-flow solve, and PowerPhase ships with constraint-aware metrics, including Safety_mBrier, NECV, and CVaR-alpha, that complement CRPS and Distortion. Across eight baselines and three seeds, distributional accuracy and constraint satisfaction rank models differently, a trade-off we term safety-fidelity. We further propose PowerForge, a scenario-based quantile forecaster with type-specific decoding heads and a causal bridge between variable groups, which achieves the best average rank on every grid.
How Far Can We Go with Pixels Alone? A Pilot Study on Screen-Only Navigation in Commercial 3D ARPGs
Feb 21, 2026Modern 3D game levels rely heavily on visual guidance, yet the navigability of level layouts remains difficult to quantify. Prior work either simulates play in simplified environments or analyzes static screenshots for visual affordances, but neither setting faithfully captures how players explore complex, real-world game levels. In this paper, we build on an existing open-source visual affordance detector and instantiate a screen-only exploration and navigation agent that operates purely from visual affordances. Our agent consumes live game frames, identifies salient interest points, and drives a simple finite-state controller over a minimal action space to explore Dark Souls-style linear levels and attempt to reach expected goal regions. Pilot experiments show that the agent can traverse most required segments and exhibits meaningful visual navigation behavior, but also highlight that limitations of the underlying visual model prevent truly comprehensive and reliable auto-navigation. We argue that this system provides a concrete, shared baseline and evaluation protocol for visual navigation in complex games, and we call for more attention to this necessary task. Our results suggest that purely vision-based sense-making models, with discrete single-modality inputs and without explicit reasoning, can effectively support navigation and environment understanding in idealized settings, but are unlikely to be a general solution on their own.
High Dimensional Procedural Content Generation
Feb 21, 2026Procedural content generation (PCG) has made substantial progress in shaping static 2D/3D geometry, while most methods treat gameplay mechanics as auxiliary and optimize only over space. We argue that this limits controllability and expressivity, and formally introduce High-Dimensional PCG (HDPCG): a framework that elevates non-geometric gameplay dimensions to first-class coordinates of a joint state space. We instantiate HDPCG along two concrete directions. Direction-Space augments geometry with a discrete layer dimension and validates reachability in 4D (x,y,z,l), enabling unified treatment of 2.5D/3.5D mechanics such as gravity inversion and parallel-world switching. Direction-Time augments geometry with temporal dynamics via time-expanded graphs, capturing action semantics and conflict rules. For each direction, we present three general, practicable algorithms with a shared pipeline of abstract skeleton generation, controlled grounding, high-dimensional validation, and multi-metric evaluation. Large-scale experiments across diverse settings validate the integrity of our problem formulation and the effectiveness of our methods on playability, structure, style, robustness, and efficiency. Beyond quantitative results, Unity-based case studies recreate playable scenarios that accord with our metrics. We hope HDPCG encourages a shift in PCG toward general representations and the generation of gameplay-relevant dimensions beyond geometry, paving the way for controllable, verifiable, and extensible level generation.
(Perlin) Noise as AI coordinator
Feb 21, 2026Large scale control of nonplayer agents is central to modern games, while production systems still struggle to balance several competing goals: locally smooth, natural behavior, and globally coordinated variety across space and time. Prior approaches rely on handcrafted rules or purely stochastic triggers, which either converge to mechanical synchrony or devolve into uncorrelated noise that is hard to tune. Continuous noise signals such as Perlin noise are well suited to this gap because they provide spatially and temporally coherent randomness, and they are already widely used for terrain, biomes, and other procedural assets. We adapt these signals for the first time to large scale AI control and present a general framework that treats continuous noise fields as an AI coordinator. The framework combines three layers of control: behavior parameterization for movement at the agent level, action time scheduling for when behaviors start and stop, and spawn or event type and feature generation for what appears and where. We instantiate the framework reproducibly and evaluate Perlin noise as a representative coordinator across multiple maps, scales, and seeds against random, filtered, deterministic, neighborhood constrained, and physics inspired baselines. Experiments show that coordinated noise fields provide stable activation statistics without lockstep, strong spatial coverage and regional balance, better diversity with controllable polarization, and competitive runtime. We hope this work motivates a broader exploration of coordinated noise in game AI as a practical path to combine efficiency, controllability, and quality.
CSP4SDG: Constraint and Information-Theory Based Role Identification in Social Deduction Games with LLM-Enhanced Inference
Nov 09, 2025In Social Deduction Games (SDGs) such as Avalon, Mafia, and Werewolf, players conceal their identities and deliberately mislead others, making hidden-role inference a central and demanding task. Accurate role identification, which forms the basis of an agent's belief state, is therefore the keystone for both human and AI performance. We introduce CSP4SDG, a probabilistic, constraint-satisfaction framework that analyses gameplay objectively. Game events and dialogue are mapped to four linguistically-agnostic constraint classes-evidence, phenomena, assertions, and hypotheses. Hard constraints prune impossible role assignments, while weighted soft constraints score the remainder; information-gain weighting links each hypothesis to its expected value under entropy reduction, and a simple closed-form scoring rule guarantees that truthful assertions converge to classical hard logic with minimum error. The resulting posterior over roles is fully interpretable and updates in real time. Experiments on three public datasets show that CSP4SDG (i) outperforms LLM-based baselines in every inference scenario, and (ii) boosts LLMs when supplied as an auxiliary "reasoning tool." Our study validates that principled probabilistic reasoning with information theory is a scalable alternative-or complement-to heavy-weight neural models for SDGs.
A Deep Learning-Based Supervised Transfer Learning Framework for DOA Estimation with Array Imperfections
Apr 18, 2025In practical scenarios, processes such as sensor design, manufacturing, and installation will introduce certain errors. Furthermore, mutual interference occurs when the sensors receive signals. These defects in array systems are referred to as array imperfections, which can significantly degrade the performance of Direction of Arrival (DOA) estimation. In this study, we propose a deep-learning based transfer learning approach, which effectively mitigates the degradation of deep-learning based DOA estimation performance caused by array imperfections. In the proposed approach, we highlight three major contributions. First, we propose a Vision Transformer (ViT) based method for DOA estimation, which achieves excellent performance in scenarios with low signal-to-noise ratios (SNR) and limited snapshots. Second, we introduce a transfer learning framework that extends deep learning models from ideal simulation scenarios to complex real-world scenarios with array imperfections. By leveraging prior knowledge from ideal simulation data, the proposed transfer learning framework significantly improves deep learning-based DOA estimation performance in the presence of array imperfections, without the need for extensive real-world data. Finally, we incorporate visualization and evaluation metrics to assess the performance of DOA estimation algorithms, which allow for a more thorough evaluation of algorithms and further validate the proposed method. Our code can be accessed at https://github.com/zzb-nice/DOA_est_Master.
A Novel Fuzzy Bi-Clustering Algorithm with AFS for Identification of Co-Regulated Genes
Feb 03, 2023The identification of co-regulated genes and their transcription-factor binding sites (TFBS) are the key steps toward understanding transcription regulation. In addition to effective laboratory assays, various bi-clustering algorithms for detection of the co-expressed genes have been developed. Bi-clustering methods are used to discover subgroups of genes with similar expression patterns under to-be-identified subsets of experimental conditions when applied to gene expression data. By building two fuzzy partition matrices of the gene expression data with the Axiomatic Fuzzy Set (AFS) theory, this paper proposes a novel fuzzy bi-clustering algorithm for identification of co-regulated genes. Specifically, the gene expression data is transformed into two fuzzy partition matrices via sub-preference relations theory of AFS at first. One of the matrices is considering the genes as the universe and the conditions as the concept, the other one is considering the genes as the concept and the conditions as the universe. The identification of the co-regulated genes (bi-clusters) is carried out on the two partition matrices at the same time. Then, a novel fuzzy-based similarity criterion is defined based on the partition matrixes, and a cyclic optimization algorithm is designed to discover the significant bi-clusters at expression level. The above procedures guarantee that the generated bi-clusters have more significant expression values than that of extracted by the traditional bi-clustering methods. Finally, the performance of the proposed method is evaluated with the performance of the three well-known bi-clustering algorithms on publicly available real microarray datasets. The experimental results are in agreement with the theoretical analysis and show that the proposed algorithm can effectively detect the co-regulated genes without any prior knowledge of the gene expression data.
An Enhanced Adaptive Bi-clustering Algorithm through Building a Shielding Complex Sub-Matrix
Nov 12, 2021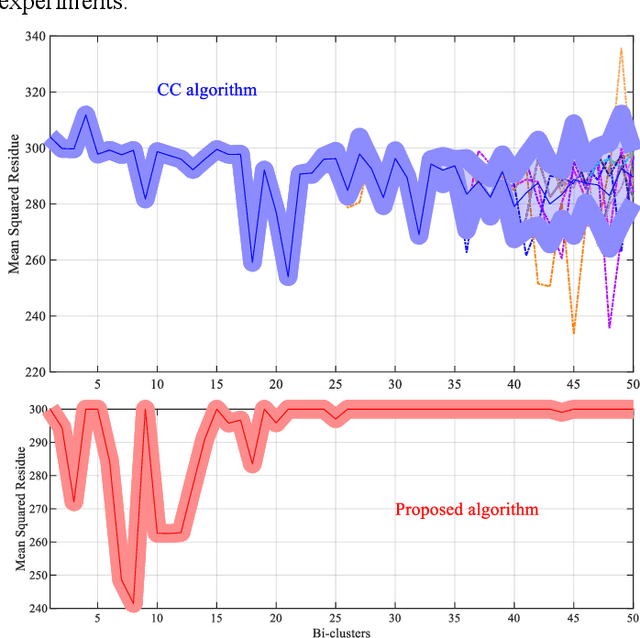
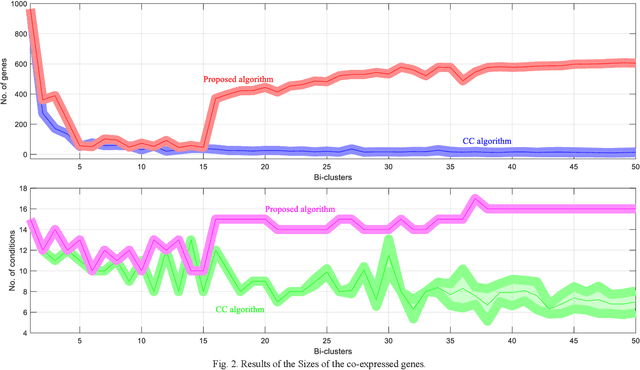
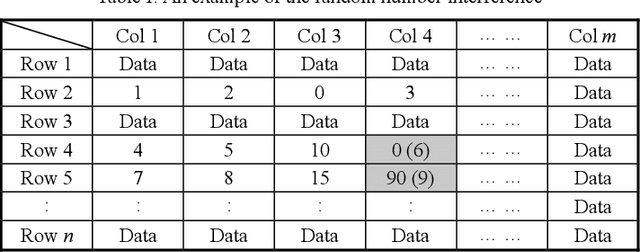
Bi-clustering refers to the task of finding sub-matrices (indexed by a group of columns and a group of rows) within a matrix of data such that the elements of each sub-matrix (data and features) are related in a particular way, for instance, that they are similar with respect to some metric. In this paper, after analyzing the well-known Cheng and Church (CC) bi-clustering algorithm which has been proved to be an effective tool for mining co-expressed genes. However, Cheng and Church bi-clustering algorithm and summarizing its limitations (such as interference of random numbers in the greedy strategy; ignoring overlapping bi-clusters), we propose a novel enhancement of the adaptive bi-clustering algorithm, where a shielding complex sub-matrix is constructed to shield the bi-clusters that have been obtained and to discover the overlapping bi-clusters. In the shielding complex sub-matrix, the imaginary and the real parts are used to shield and extend the new bi-clusters, respectively, and to form a series of optimal bi-clusters. To assure that the obtained bi-clusters have no effect on the bi-clusters already produced, a unit impulse signal is introduced to adaptively detect and shield the constructed bi-clusters. Meanwhile, to effectively shield the null data (zero-size data), another unit impulse signal is set for adaptive detecting and shielding. In addition, we add a shielding factor to adjust the mean squared residue score of the rows (or columns), which contains the shielded data of the sub-matrix, to decide whether to retain them or not. We offer a thorough analysis of the developed scheme. The experimental results are in agreement with the theoretical analysis. The results obtained on a publicly available real microarray dataset show the enhancement of the bi-clusters performance thanks to the proposed method.
Exploiting a Supervised Index for High-accuracy Parameter Estimation in Low SNR
Jun 29, 2021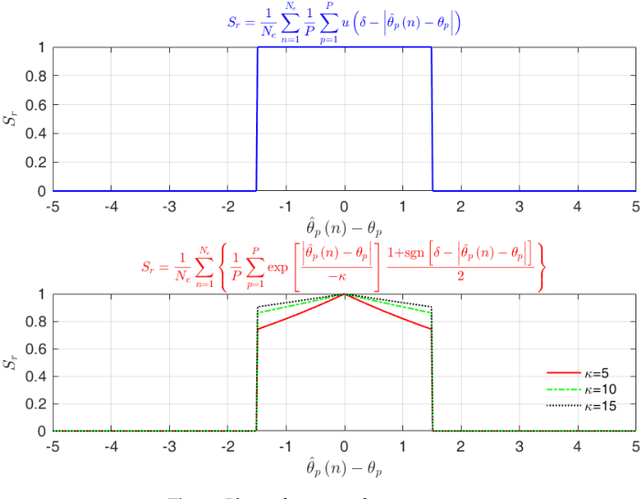
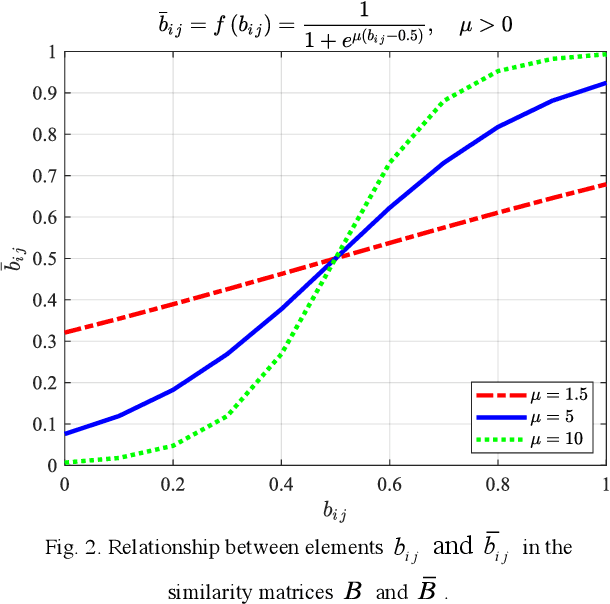
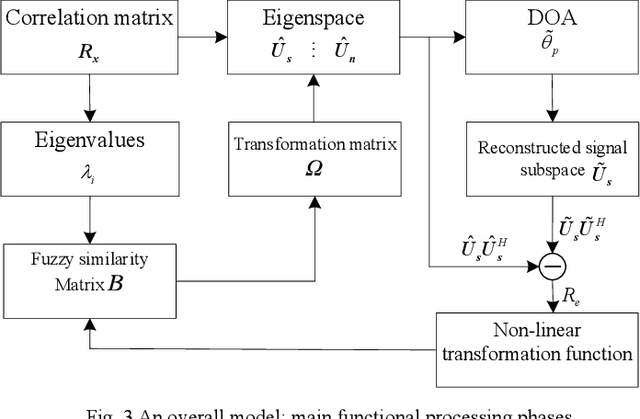
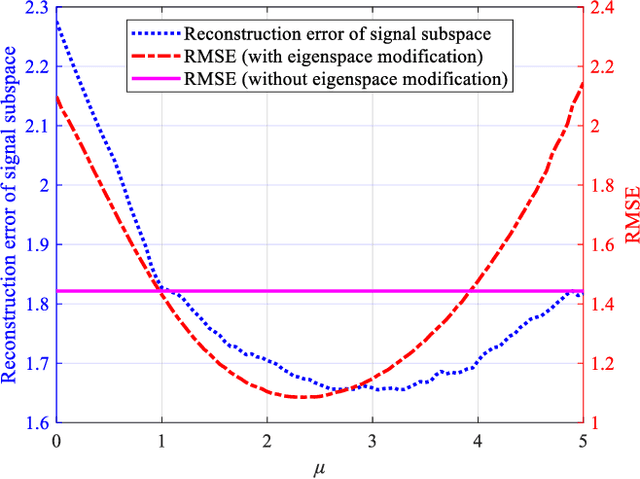
Performance of parameter estimation is one of the most important issues in array signal processing. The root mean square error, probability of success, resolution probabilities, and computational complexity are frequently used indexes for evaluating the performance of the parameter estimation methods. However, a common characteristic of these indexes is that they are unsupervised indexes, and are passively used for evaluating the estimation results. In other words, these indexes cannot participate in the design of estimation methods. It seems that exploiting a validity supervised index for the parameter estimation that can guide the design of the methods will be an interesting and meaningful work. In this study, we exploit an index to build a supervised learning model of the parameter estimation. With the developed model we refine the signal subspace so as to enhance the performance of the parameter estimation method. The main characteristic of the proposed model is a circularly applied feedback of the estimated parameter for refining the estimated subspace. It is a closed loop and supervised method not reported before. This research opens a specific way for improving the performance of the parameter estimation by a supervised index. However, the proposed method is still unsatisfying in some scopes of signal-to-noise ratio (SNR). We believe that exploiting a validity index for the parameter estimation in array signal processing is still a general and interesting problem.