 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Compressive Coding for 3D Reconstruction
Jan 19, 2023



A central goal of visual recognition is to understand objects and scenes from a single image. 2D recognition has witnessed tremendous progress thanks to large-scale learning and general-purpose representations. Comparatively, 3D poses new challenges stemming from occlusions not depicted in the image. Prior works try to overcome these by inferring from multiple views or rely on scarce CAD models and category-specific priors which hinder scaling to novel settings. In this work, we explore single-view 3D reconstruction by learning generalizable representations inspired by advances in self-supervised learning. We introduce a simple framework that operates on 3D points of single objects or whole scenes coupled with category-agnostic large-scale training from diverse RGB-D videos. Our model, Multiview Compressive Coding (MCC), learns to compress the input appearance and geometry to predict the 3D structure by querying a 3D-aware decoder. MCC's generality and efficiency allow it to learn from large-scale and diverse data sources with strong generalization to novel objects imagined by DALL$\cdot$E 2 or captured in-the-wild with an iPhone.
Neural Shape Compiler: A Unified Framework for Transforming between Text, Point Cloud, and Program
Dec 25, 20223D shapes have complementary abstractions from low-level geometry to part-based hierarchies to languages, which convey different levels of information. This paper presents a unified framework to translate between pairs of shape abstractions: $\textit{Text}$ $\Longleftrightarrow$ $\textit{Point Cloud}$ $\Longleftrightarrow$ $\textit{Program}$. We propose $\textbf{Neural Shape Compiler}$ to model the abstraction transformation as a conditional generation process. It converts 3D shapes of three abstract types into unified discrete shape code, transforms each shape code into code of other abstract types through the proposed $\textit{ShapeCode Transformer}$, and decodes them to output the target shape abstraction. Point Cloud code is obtained in a class-agnostic way by the proposed $\textit{Point}$VQVAE. On Text2Shape, ShapeGlot, ABO, Genre, and Program Synthetic datasets, Neural Shape Compiler shows strengths in $\textit{Text}$ $\Longrightarrow$ $\textit{Point Cloud}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Text}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Program}$, and Point Cloud Completion tasks. Additionally, Neural Shape Compiler benefits from jointly training on all heterogeneous data and tasks.
Self-Supervised Correspondence Estimation via Multiview Registration
Dec 06, 2022



Video provides us with the spatio-temporal consistency needed for visual learning. Recent approaches have utilized this signal to learn correspondence estimation from close-by frame pairs. However, by only relying on close-by frame pairs, those approaches miss out on the richer long-range consistency between distant overlapping frames. To address this, we propose a self-supervised approach for correspondence estimation that learns from multiview consistency in short RGB-D video sequences. Our approach combines pairwise correspondence estimation and registration with a novel SE(3) transformation synchronization algorithm. Our key insight is that self-supervised multiview registration allows us to obtain correspondences over longer time frames; increasing both the diversity and difficulty of sampled pairs. We evaluate our approach on indoor scenes for correspondence estimation and RGB-D pointcloud registration and find that we perform on-par with supervised approaches.
RGB no more: Minimally-decoded JPEG Vision Transformers
Nov 29, 2022



Most neural networks for computer vision are designed to infer using RGB images. However, these RGB images are commonly encoded in JPEG before saving to disk; decoding them imposes an unavoidable overhead for RGB networks. Instead, our work focuses on training Vision Transformers (ViT) directly from the encoded features of JPEG. This way, we can avoid most of the decoding overhead, accelerating data load. Existing works have studied this aspect but they focus on CNNs. Due to how these encoded features are structured, CNNs require heavy modification to their architecture to accept such data. Here, we show that this is not the case for ViTs. In addition, we tackle data augmentation directly on these encoded features, which to our knowledge, has not been explored in-depth for training in this setting. With these two improvements -- ViT and data augmentation -- we show that our ViT-Ti model achieves up to 39.2% faster training and 17.9% faster inference with no accuracy loss compared to the RGB counterpart.
The 8-Point Algorithm as an Inductive Bias for Relative Pose Prediction by ViTs
Aug 18, 2022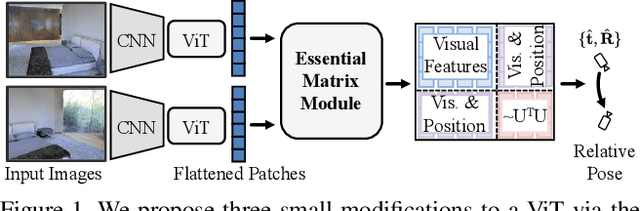
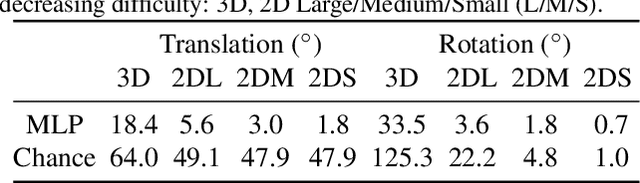
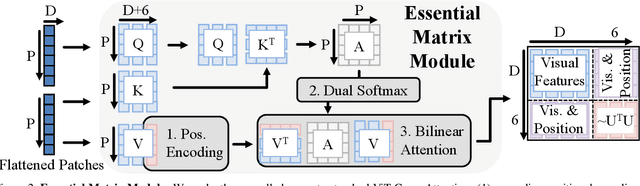
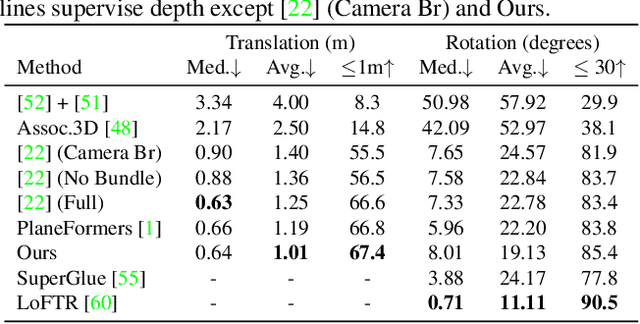
We present a simple baseline for directly estimating the relative pose (rotation and translation, including scale) between two images. Deep methods have recently shown strong progress but often require complex or multi-stage architectures. We show that a handful of modifications can be applied to a Vision Transformer (ViT) to bring its computations close to the Eight-Point Algorithm. This inductive bias enables a simple method to be competitive in multiple settings, often substantially improving over the state of the art with strong performance gains in limited data regimes.
Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
Jul 21, 2022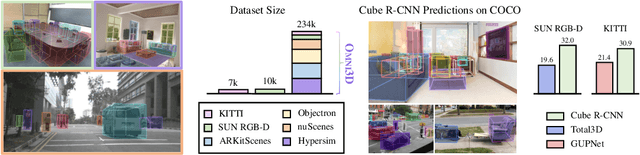
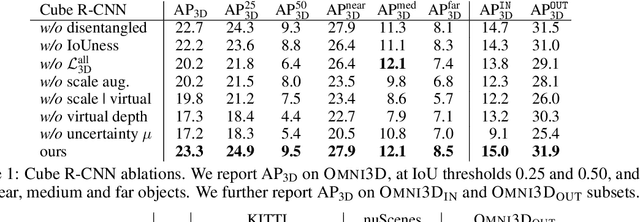
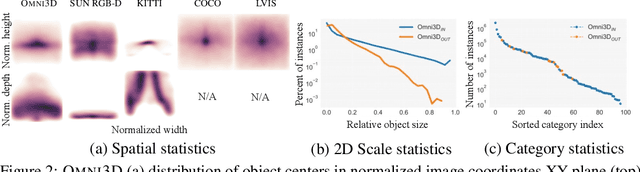
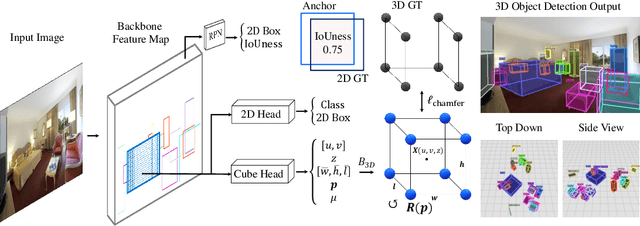
Recognizing scenes and objects in 3D from a single image is a longstanding goal of computer vision with applications in robotics and AR/VR. For 2D recognition, large datasets and scalable solutions have led to unprecedented advances. In 3D, existing benchmarks are small in size and approaches specialize in few object categories and specific domains, e.g. urban driving scenes. Motivated by the success of 2D recognition, we revisit the task of 3D object detection by introducing a large benchmark, called Omni3D. Omni3D re-purposes and combines existing datasets resulting in 234k images annotated with more than 3 million instances and 97 categories.3D detection at such scale is challenging due to variations in camera intrinsics and the rich diversity of scene and object types. We propose a model, called Cube R-CNN, designed to generalize across camera and scene types with a unified approach. We show that Cube R-CNN outperforms prior works on the larger Omni3D and existing benchmarks. Finally, we prove that Omni3D is a powerful dataset for 3D object recognition, show that it improves single-dataset performance and can accelerate learning on new smaller datasets via pre-training.
FWD: Real-time Novel View Synthesis with Forward Warping and Depth
Jun 21, 2022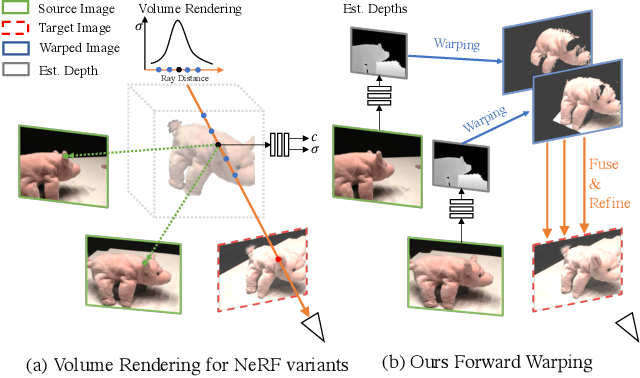


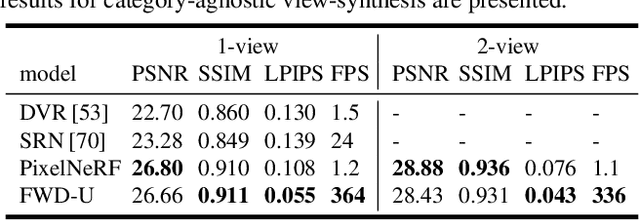
Novel view synthesis (NVS) is a challenging task requiring systems to generate photorealistic images of scenes from new viewpoints, where both quality and speed are important for applications. Previous image-based rendering (IBR) methods are fast, but have poor quality when input views are sparse. Recent Neural Radiance Fields (NeRF) and generalizable variants give impressive results but are not real-time. In our paper, we propose a generalizable NVS method with sparse inputs, called FWD, which gives high-quality synthesis in real-time. With explicit depth and differentiable rendering, it achieves competitive results to the SOTA methods with 130-1000x speedup and better perceptual quality. If available, we can seamlessly integrate sensor depth during either training or inference to improve image quality while retaining real-time speed. With the growing prevalence of depths sensors, we hope that methods making use of depth will become increasingly useful.
Learning 3D Object Shape and Layout without 3D Supervision
Jun 14, 2022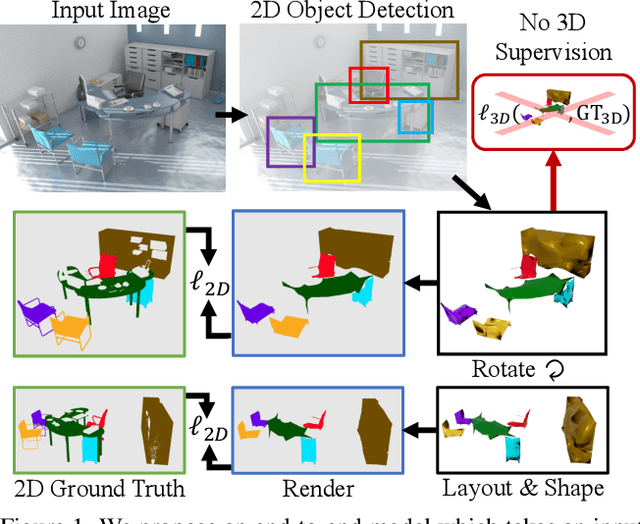
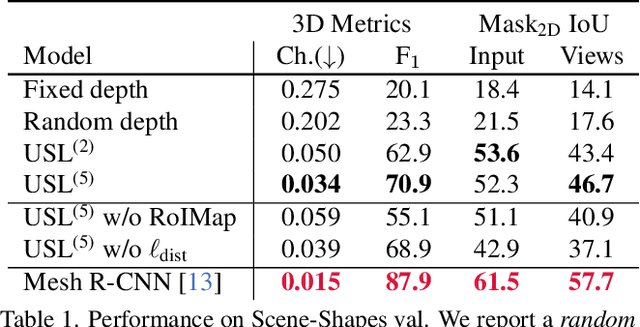
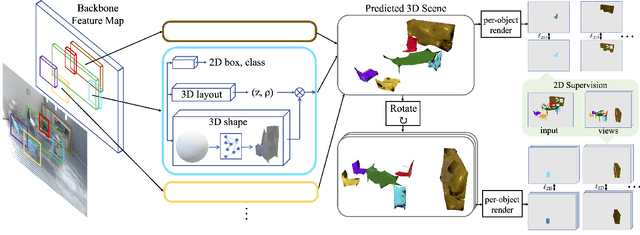
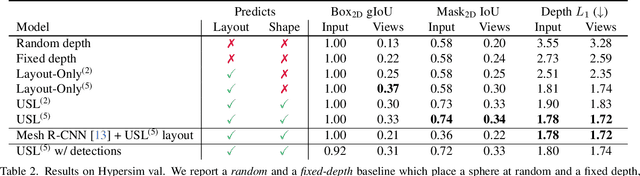
A 3D scene consists of a set of objects, each with a shape and a layout giving their position in space. Understanding 3D scenes from 2D images is an important goal, with applications in robotics and graphics. While there have been recent advances in predicting 3D shape and layout from a single image, most approaches rely on 3D ground truth for training which is expensive to collect at scale. We overcome these limitations and propose a method that learns to predict 3D shape and layout for objects without any ground truth shape or layout information: instead we rely on multi-view images with 2D supervision which can more easily be collected at scale. Through extensive experiments on 3D Warehouse, Hypersim, and ScanNet we demonstrate that our approach scales to large datasets of realistic images, and compares favorably to methods relying on 3D ground truth. On Hypersim and ScanNet where reliable 3D ground truth is not available, our approach outperforms supervised approaches trained on smaller and less diverse datasets.
What's Behind the Couch? Directed Ray Distance Functions for 3D Scene Reconstruction
Dec 08, 2021
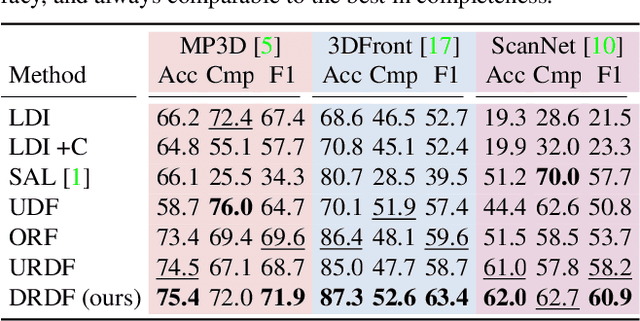
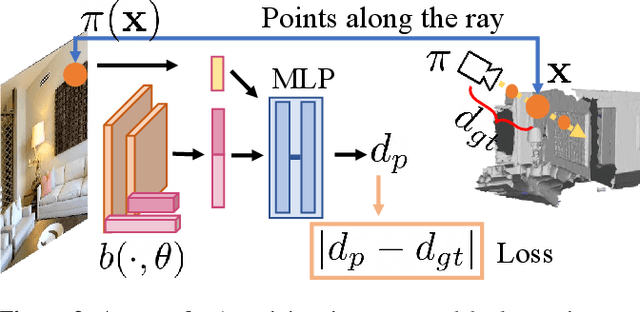
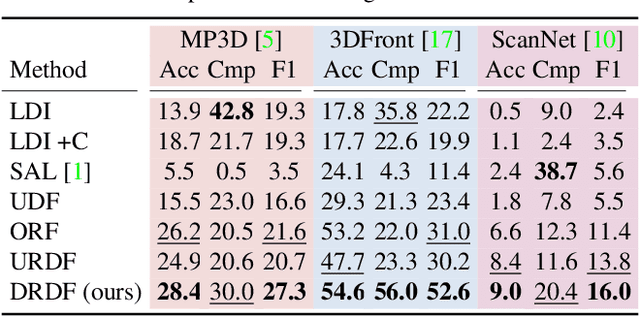
We present an approach for scene-level 3D reconstruction, including occluded regions, from an unseen RGB image. Our approach is trained on real 3D scans and images. This problem has proved difficult for multiple reasons; Real scans are not watertight, precluding many methods; distances in scenes require reasoning across objects (making it even harder); and, as we show, uncertainty about surface locations motivates networks to produce outputs that lack basic distance function properties. We propose a new distance-like function that can be computed on unstructured scans and has good behavior under uncertainty about surface location. Computing this function over rays reduces the complexity further. We train a deep network to predict this function and show it outperforms other methods on Matterport3D, 3D Front, and ScanNet.
StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions
Dec 02, 2021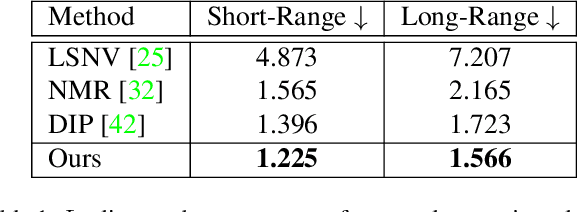
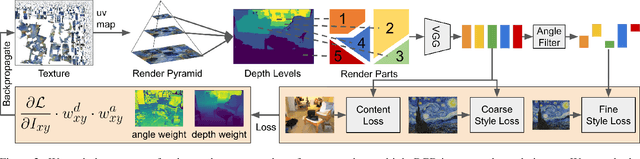
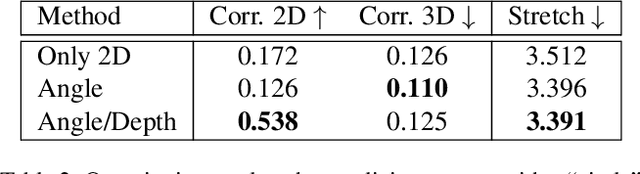
We apply style transfer on mesh reconstructions of indoor scenes. This enables VR applications like experiencing 3D environments painted in the style of a favorite artist. Style transfer typically operates on 2D images, making stylization of a mesh challenging. When optimized over a variety of poses, stylization patterns become stretched out and inconsistent in size. On the other hand, model-based 3D style transfer methods exist that allow stylization from a sparse set of images, but they require a network at inference time. To this end, we optimize an explicit texture for the reconstructed mesh of a scene and stylize it jointly from all available input images. Our depth- and angle-aware optimization leverages surface normal and depth data of the underlying mesh to create a uniform and consistent stylization for the whole scene. Our experiments show that our method creates sharp and detailed results for the complete scene without view-dependent artifacts. Through extensive ablation studies, we show that the proposed 3D awareness enables style transfer to be applied to the 3D domain of a mesh. Our method can be used to render a stylized mesh in real-time with traditional rendering pipelines.