 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphSAM: Learning the Morphological Prompts from Atlases for Spine Image Segmentation
Jun 16, 2025Spine image segmentation is crucial for clinical diagnosis and treatment of spine diseases. The complex structure of the spine and the high morphological similarity between individual vertebrae and adjacent intervertebral discs make accurate spine segmentation a challenging task. Although the Segment Anything Model (SAM) has been developed, it still struggles to effectively capture and utilize morphological information, limiting its ability to enhance spine image segmentation performance. To address these challenges, in this paper, we propose a MorphSAM that explicitly learns morphological information from atlases, thereby strengthening the spine image segmentation performance of SAM. Specifically, the MorphSAM includes two fully automatic prompt learning networks, 1) an anatomical prompt learning network that directly learns morphological information from anatomical atlases, and 2) a semantic prompt learning network that derives morphological information from text descriptions converted from the atlases. Then, the two learned morphological prompts are fed into the SAM model to boost the segmentation performance. We validate our MorphSAM on two spine image segmentation tasks, including a spine anatomical structure segmentation task with CT images and a lumbosacral plexus segmentation task with MR images. Experimental results demonstrate that our MorphSAM achieves superior segmentation performance when compared to the state-of-the-art methods.
Low-Dose CT Denoising via Sinogram Inner-Structure Transformer
Apr 18, 2022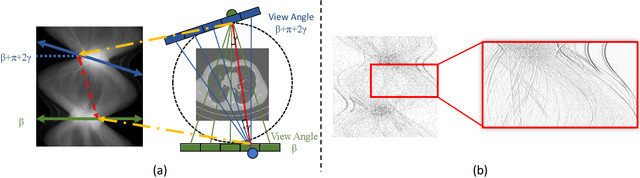
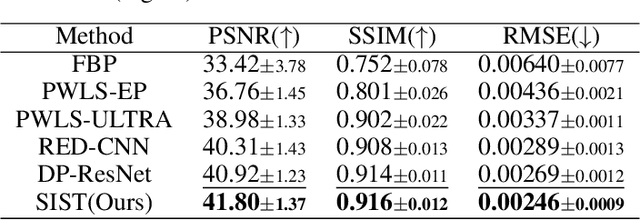
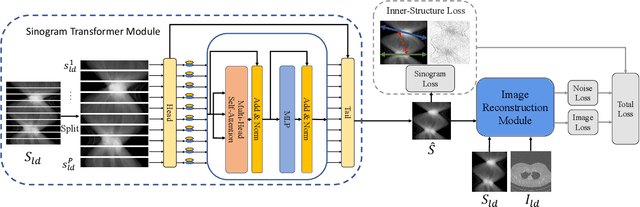

Low-Dose Computed Tomography (LDCT) technique, which reduces the radiation harm to human bodies, is now attracting increasing interest in the medical imaging field. As the image quality is degraded by low dose radiation, LDCT exams require specialized reconstruction methods or denoising algorithms. However, most of the recent effective methods overlook the inner-structure of the original projection data (sinogram) which limits their denoising ability. The inner-structure of the sinogram represents special characteristics of the data in the sinogram domain. By maintaining this structure while denoising, the noise can be obviously restrained. Therefore, we propose an LDCT denoising network namely Sinogram Inner-Structure Transformer (SIST) to reduce the noise by utilizing the inner-structure in the sinogram domain. Specifically, we study the CT imaging mechanism and statistical characteristics of sinogram to design the sinogram inner-structure loss including the global and local inner-structure for restoring high-quality CT images. Besides, we propose a sinogram transformer module to better extract sinogram features. The transformer architecture using a self-attention mechanism can exploit interrelations between projections of different view angles, which achieves an outstanding performance in sinogram denoising. Furthermore, in order to improve the performance in the image domain, we propose the image reconstruction module to complementarily denoise both in the sinogram and image domain.