 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching in Space and Time: Unified Memory-Action Loops for Open-World Object Retrieval
Nov 19, 2025



Service robots must retrieve objects in dynamic, open-world settings where requests may reference attributes ("the red mug"), spatial context ("the mug on the table"), or past states ("the mug that was here yesterday"). Existing approaches capture only parts of this problem: scene graphs capture spatial relations but ignore temporal grounding, temporal reasoning methods model dynamics but do not support embodied interaction, and dynamic scene graphs handle both but remain closed-world with fixed vocabularies. We present STAR (SpatioTemporal Active Retrieval), a framework that unifies memory queries and embodied actions within a single decision loop. STAR leverages non-parametric long-term memory and a working memory to support efficient recall, and uses a vision-language model to select either temporal or spatial actions at each step. We introduce STARBench, a benchmark of spatiotemporal object search tasks across simulated and real environments. Experiments in STARBench and on a Tiago robot show that STAR consistently outperforms scene-graph and memory-only baselines, demonstrating the benefits of treating search in time and search in space as a unified problem.
Adaptive Diffusion Terrain Generator for Autonomous Uneven Terrain Navigation
Oct 14, 2024



Model-free reinforcement learning has emerged as a powerful method for developing robust robot control policies capable of navigating through complex and unstructured terrains. The effectiveness of these methods hinges on two essential elements: (1) the use of massively parallel physics simulations to expedite policy training, and (2) an environment generator tasked with crafting sufficiently challenging yet attainable terrains to facilitate continuous policy improvement. Existing methods of environment generation often rely on heuristics constrained by a set of parameters, limiting the diversity and realism. In this work, we introduce the Adaptive Diffusion Terrain Generator (ADTG), a novel method that leverages Denoising Diffusion Probabilistic Models to dynamically expand existing training environments by adding more diverse and complex terrains adaptive to the current policy. ADTG guides the diffusion model's generation process through initial noise optimization, blending noise-corrupted terrains from existing training environments weighted by the policy's performance in each corresponding environment. By manipulating the noise corruption level, ADTG seamlessly transitions between generating similar terrains for policy fine-tuning and novel ones to expand training diversity. Our experiments show that the policy trained by ADTG outperforms both procedural generated and natural environments, along with popular navigation methods.
Context-Generative Default Policy for Bounded Rational Agent
Sep 17, 2024Bounded rational agents often make decisions by evaluating a finite selection of choices, typically derived from a reference point termed the $`$default policy,' based on previous experience. However, the inherent rigidity of the static default policy presents significant challenges for agents when operating in unknown environment, that are not included in agent's prior knowledge. In this work, we introduce a context-generative default policy that leverages the region observed by the robot to predict unobserved part of the environment, thereby enabling the robot to adaptively adjust its default policy based on both the actual observed map and the $\textit{imagined}$ unobserved map. Furthermore, the adaptive nature of the bounded rationality framework enables the robot to manage unreliable or incorrect imaginations by selectively sampling a few trajectories in the vicinity of the default policy. Our approach utilizes a diffusion model for map prediction and a sampling-based planning with B-spline trajectory optimization to generate the default policy. Extensive evaluations reveal that the context-generative policy outperforms the baseline methods in identifying and avoiding unseen obstacles. Additionally, real-world experiments conducted with the Crazyflie drones demonstrate the adaptability of our proposed method, even when acting in environments outside the domain of the training distribution.
CIMRL: Combining IMitation and Reinforcement Learning for Safe Autonomous Driving
Jun 17, 2024



Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
Boundary-Aware Value Function Generation for Safe Stochastic Motion Planning
Mar 22, 2024



Navigation safety is critical for many autonomous systems such as self-driving vehicles in an urban environment. It requires an explicit consideration of boundary constraints that describe the borders of any infeasible, non-navigable, or unsafe regions. We propose a principled boundary-aware safe stochastic planning framework with promising results. Our method generates a value function that can strictly distinguish the state values between free (safe) and non-navigable (boundary) spaces in the continuous state, naturally leading to a safe boundary-aware policy. At the core of our solution lies a seamless integration of finite elements and kernel-based functions, where the finite elements allow us to characterize safety-critical states' borders accurately, and the kernel-based function speeds up computation for the non-safety-critical states. The proposed method was evaluated through extensive simulations and demonstrated safe navigation behaviors in mobile navigation tasks. Additionally, we demonstrate that our approach can maneuver safely and efficiently in cluttered real-world environments using a ground vehicle with strong external disturbances, such as navigating on a slippery floor and against external human intervention.
Coordination of Bounded Rational Drones through Informed Prior Policy
Jul 28, 2023



Biological agents, such as humans and animals, are capable of making decisions out of a very large number of choices in a limited time. They can do so because they use their prior knowledge to find a solution that is not necessarily optimal but good enough for the given task. In this work, we study the motion coordination of multiple drones under the above-mentioned paradigm, Bounded Rationality (BR), to achieve cooperative motion planning tasks. Specifically, we design a prior policy that provides useful goal-directed navigation heuristics in familiar environments and is adaptive in unfamiliar ones via Reinforcement Learning augmented with an environment-dependent exploration noise. Integrating this prior policy in the game-theoretic bounded rationality framework allows agents to quickly make decisions in a group considering other agents' computational constraints. Our investigation assures that agents with a well-informed prior policy increase the efficiency of the collective decision-making capability of the group. We have conducted rigorous experiments in simulation and in the real world to demonstrate that the ability of informed agents to navigate to the goal safely can guide the group to coordinate efficiently under the BR framework.
Towards Efficient MPPI Trajectory Generation with Unscented Guidance: U-MPPI Control Strategy
Jun 21, 2023



The classical Model Predictive Path Integral (MPPI) control framework lacks reliable safety guarantees since it relies on a risk-neutral trajectory evaluation technique, which can present challenges for safety-critical applications such as autonomous driving. Additionally, if the majority of MPPI sampled trajectories concentrate in high-cost regions, it may generate an infeasible control sequence. To address this challenge, we propose the U-MPPI control strategy, a novel methodology that can effectively manage system uncertainties while integrating a more efficient trajectory sampling strategy. The core concept is to leverage the Unscented Transform (UT) to propagate not only the mean but also the covariance of the system dynamics, going beyond the traditional MPPI method. As a result, it introduces a novel and more efficient trajectory sampling strategy, significantly enhancing state-space exploration and ultimately reducing the risk of being trapped in local minima. Furthermore, by leveraging the uncertainty information provided by UT, we incorporate a risk-sensitive cost function that explicitly accounts for risk or uncertainty throughout the trajectory evaluation process, resulting in a more resilient control system capable of handling uncertain conditions. By conducting extensive simulations of 2D aggressive autonomous navigation in both known and unknown cluttered environments, we verify the efficiency and robustness of our proposed U-MPPI control strategy compared to the baseline MPPI. We further validate the practicality of U-MPPI through real-world demonstrations in unknown cluttered environments, showcasing its superior ability to incorporate both the UT and local costmap into the optimization problem without introducing additional complexity.
Causal Inference for De-biasing Motion Estimation from Robotic Observational Data
Oct 17, 2022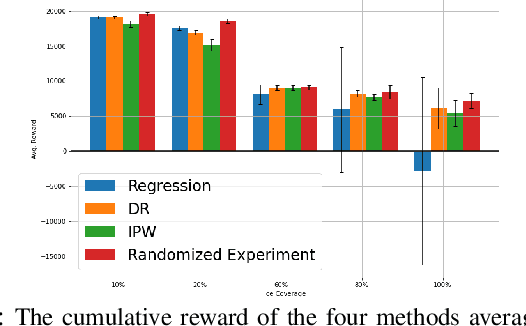
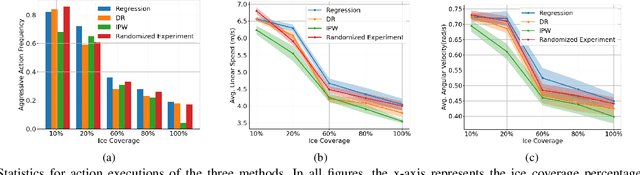
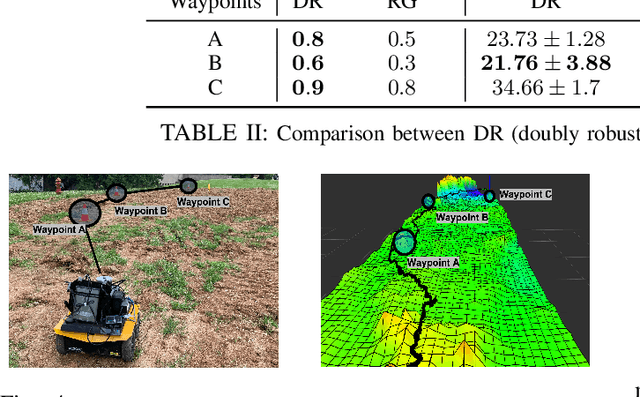
Robot data collected in complex real-world scenarios are often biased due to safety concerns, human preferences, and mission or platform constraints. Consequently, robot learning from such observational data poses great challenges for accurate parameter estimation. We propose a principled causal inference framework for robots to learn the parameters of a stochastic motion model using observational data. Specifically, we leverage the de-biasing functionality of the potential-outcome causal inference framework, the Inverse Propensity Weighting (IPW), and the Doubly Robust (DR) methods, to obtain a better parameter estimation of the robot's stochastic motion model. The IPW is a re-weighting approach to ensure unbiased estimation, and the DR approach further combines any two estimators to strengthen the unbiased result even if one of these estimators is biased. We then develop an approximate policy iteration algorithm using the bias-eliminated estimated state transition function. We validate our framework using both simulation and real-world experiments, and the results have revealed that the proposed causal inference-based navigation and control framework can correctly and efficiently learn the parameters from biased observational data.
Decision-Making Among Bounded Rational Agents
Oct 17, 2022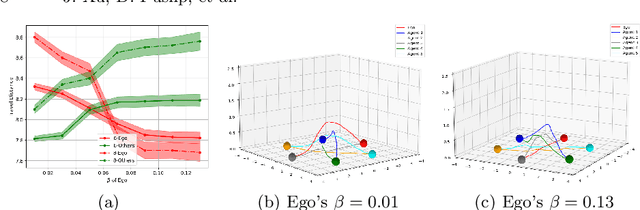
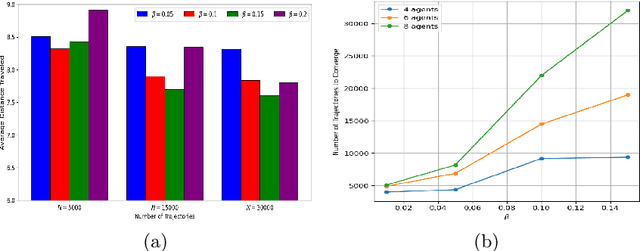
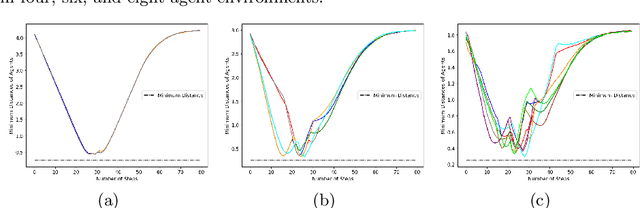
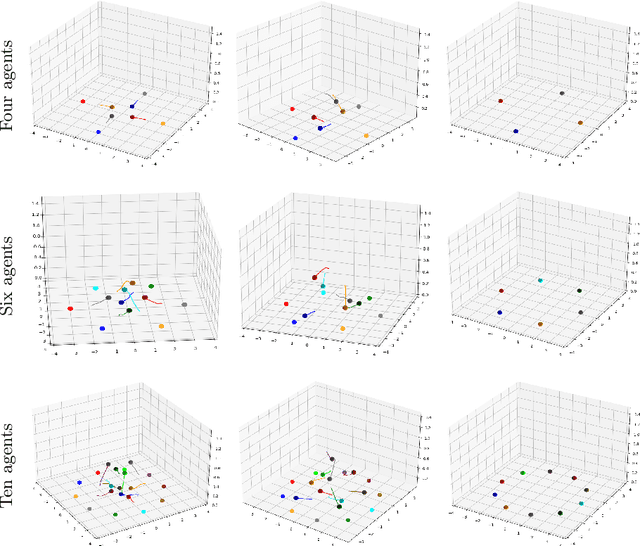
When robots share the same workspace with other intelligent agents (e.g., other robots or humans), they must be able to reason about the behaviors of their neighboring agents while accomplishing the designated tasks. In practice, frequently, agents do not exhibit absolutely rational behavior due to their limited computational resources. Thus, predicting the optimal agent behaviors is undesirable (because it demands prohibitive computational resources) and undesirable (because the prediction may be wrong). Motivated by this observation, we remove the assumption of perfectly rational agents and propose incorporating the concept of bounded rationality from an information-theoretic view into the game-theoretic framework. This allows the robots to reason other agents' sub-optimal behaviors and act accordingly under their computational constraints. Specifically, bounded rationality directly models the agent's information processing ability, which is represented as the KL-divergence between nominal and optimized stochastic policies, and the solution to the bounded-optimal policy can be obtained by an efficient importance sampling approach. Using both simulated and real-world experiments in multi-robot navigation tasks, we demonstrate that the resulting framework allows the robots to reason about different levels of rational behaviors of other agents and compute a reasonable strategy under its computational constraint.
Kernel-based Diffusion Approximated Markov Decision Processes for Off-Road Autonomous Navigation and Control
Nov 16, 2021
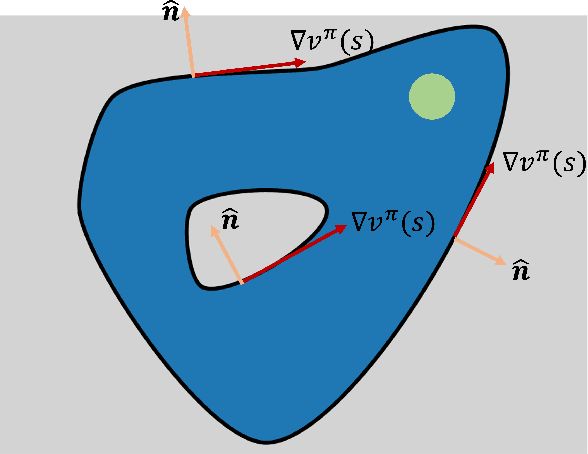
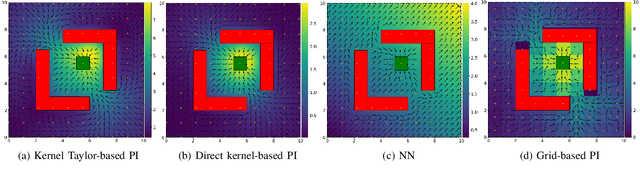
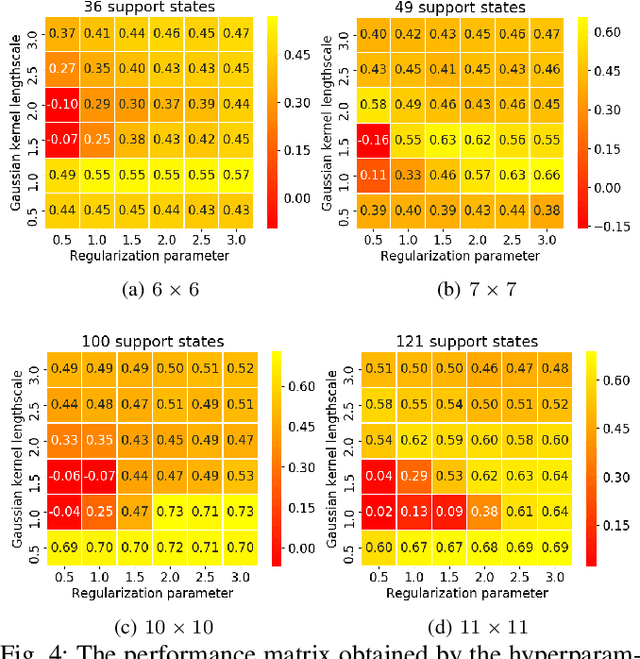
We propose a diffusion approximation method to the continuous-state Markov Decision Processes (MDPs) that can be utilized to address autonomous navigation and control in unstructured off-road environments. In contrast to most decision-theoretic planning frameworks that assume fully known state transition models, we design a method that eliminates such a strong assumption that is often extremely difficult to engineer in reality. We first take the second-order Taylor expansion of the value function. The Bellman optimality equation is then approximated by a partial differential equation, which only relies on the first and second moments of the transition model. By combining the kernel representation of the value function, we then design an efficient policy iteration algorithm whose policy evaluation step can be represented as a linear system of equations characterized by a finite set of supporting states. We first validate the proposed method through extensive simulations in $2D$ obstacle avoidance and $2.5D$ terrain navigation problems. The results show that the proposed approach leads to a much superior performance over several baselines. We then develop a system that integrates our decision-making framework with onboard perception and conduct real-world experiments in both cluttered indoor and unstructured outdoor environments. The results from the physical systems further demonstrate the applicability of our method in challenging real-world environments.