 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Scaled Logit Distillation for Ternary Weight Generative Language Models
Aug 13, 2023Generative Language Models (GLMs) have shown impressive performance in tasks such as text generation, understanding, and reasoning. However, the large model size poses challenges for practical deployment. To solve this problem, Quantization-Aware Training (QAT) has become increasingly popular. However, current QAT methods for generative models have resulted in a noticeable loss of accuracy. To counteract this issue, we propose a novel knowledge distillation method specifically designed for GLMs. Our method, called token-scaled logit distillation, prevents overfitting and provides superior learning from the teacher model and ground truth. This research marks the first evaluation of ternary weight quantization-aware training of large-scale GLMs with less than 1.0 degradation in perplexity and no loss of accuracy in a reasoning task.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023



3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.
Teacher Intervention: Improving Convergence of Quantization Aware Training for Ultra-Low Precision Transformers
Feb 23, 2023Pre-trained Transformer models such as BERT have shown great success in a wide range of applications, but at the cost of substantial increases in model complexity. Quantization-aware training (QAT) is a promising method to lower the implementation cost and energy consumption. However, aggressive quantization below 2-bit causes considerable accuracy degradation due to unstable convergence, especially when the downstream dataset is not abundant. This work proposes a proactive knowledge distillation method called Teacher Intervention (TI) for fast converging QAT of ultra-low precision pre-trained Transformers. TI intervenes layer-wise signal propagation with the intact signal from the teacher to remove the interference of propagated quantization errors, smoothing loss surface of QAT and expediting the convergence. Furthermore, we propose a gradual intervention mechanism to stabilize the recovery of subsections of Transformer layers from quantization. The proposed schemes enable fast convergence of QAT and improve the model accuracy regardless of the diverse characteristics of downstream fine-tuning tasks. We demonstrate that TI consistently achieves superior accuracy with significantly lower fine-tuning iterations on well-known Transformers of natural language processing as well as computer vision compared to the state-of-the-art QAT methods.
Exploring Attention Map Reuse for Efficient Transformer Neural Networks
Jan 29, 2023



Transformer-based deep neural networks have achieved great success in various sequence applications due to their powerful ability to model long-range dependency. The key module of Transformer is self-attention (SA) which extracts features from the entire sequence regardless of the distance between positions. Although SA helps Transformer performs particularly well on long-range tasks, SA requires quadratic computation and memory complexity with the input sequence length. Recently, attention map reuse, which groups multiple SA layers to share one attention map, has been proposed and achieved significant speedup for speech recognition models. In this paper, we provide a comprehensive study on attention map reuse focusing on its ability to accelerate inference. We compare the method with other SA compression techniques and conduct a breakdown analysis of its advantages for a long sequence. We demonstrate the effectiveness of attention map reuse by measuring the latency on both CPU and GPU platforms.
Automatic Network Adaptation for Ultra-Low Uniform-Precision Quantization
Jan 04, 2023Uniform-precision neural network quantization has gained popularity since it simplifies densely packed arithmetic unit for high computing capability. However, it ignores heterogeneous sensitivity to the impact of quantization errors across the layers, resulting in sub-optimal inference accuracy. This work proposes a novel neural architecture search called neural channel expansion that adjusts the network structure to alleviate accuracy degradation from ultra-low uniform-precision quantization. The proposed method selectively expands channels for the quantization sensitive layers while satisfying hardware constraints (e.g., FLOPs, PARAMs). Based on in-depth analysis and experiments, we demonstrate that the proposed method can adapt several popular networks channels to achieve superior 2-bit quantization accuracy on CIFAR10 and ImageNet. In particular, we achieve the best-to-date Top-1/Top-5 accuracy for 2-bit ResNet50 with smaller FLOPs and the parameter size.
Understanding and Improving Knowledge Distillation for Quantization-Aware Training of Large Transformer Encoders
Nov 20, 2022



Knowledge distillation (KD) has been a ubiquitous method for model compression to strengthen the capability of a lightweight model with the transferred knowledge from the teacher. In particular, KD has been employed in quantization-aware training (QAT) of Transformer encoders like BERT to improve the accuracy of the student model with the reduced-precision weight parameters. However, little is understood about which of the various KD approaches best fits the QAT of Transformers. In this work, we provide an in-depth analysis of the mechanism of KD on attention recovery of quantized large Transformers. In particular, we reveal that the previously adopted MSE loss on the attention score is insufficient for recovering the self-attention information. Therefore, we propose two KD methods; attention-map and attention-output losses. Furthermore, we explore the unification of both losses to address task-dependent preference between attention-map and output losses. The experimental results on various Transformer encoder models demonstrate that the proposed KD methods achieve state-of-the-art accuracy for QAT with sub-2-bit weight quantization.
Learning from distinctive candidates to optimize reduced-precision convolution program on tensor cores
Feb 24, 2022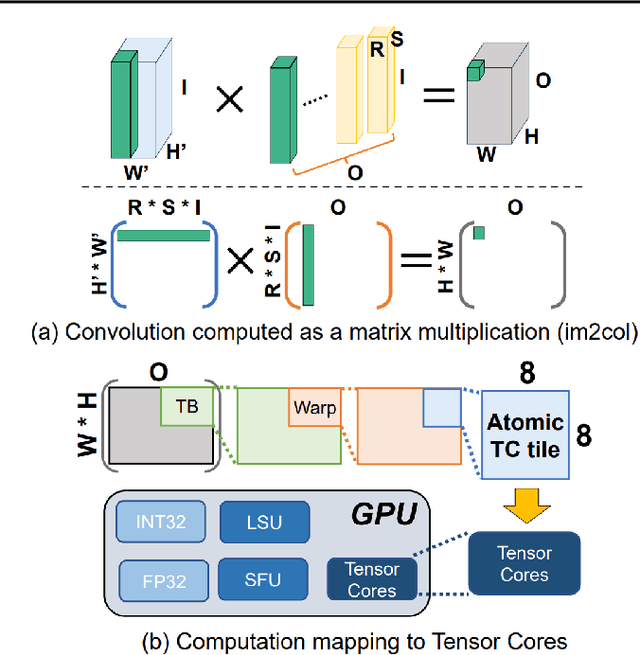
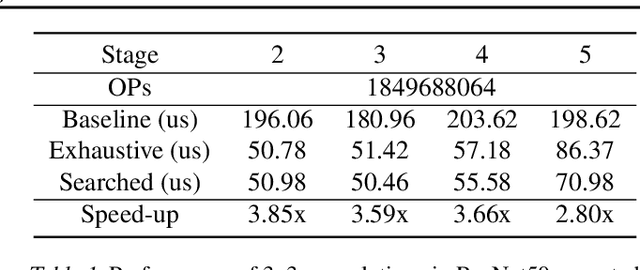
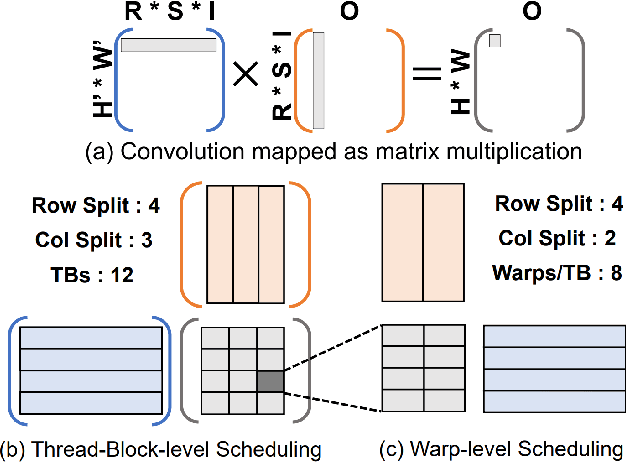
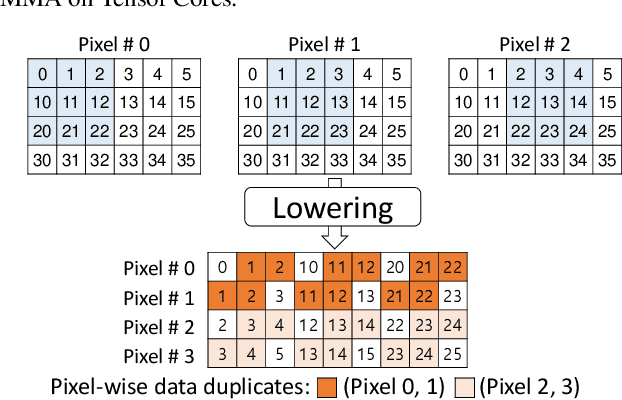
Convolution is one of the fundamental operations of deep neural networks with demanding matrix computation. In a graphic processing unit (GPU), Tensor Core is a specialized matrix processing hardware equipped with reduced-precision matrix-multiply-accumulate (MMA) instructions to increase throughput. However, it is challenging to achieve optimal performance since the best scheduling of MMA instructions varies for different convolution sizes. In particular, reduced-precision MMA requires many elements grouped as a matrix operand, seriously limiting data reuse and imposing packing and layout overhead on the schedule. This work proposes an automatic scheduling method of reduced-precision MMA for convolution operation. In this method, we devise a search space that explores the thread tile and warp sizes to increase the data reuse despite a large matrix operand of reduced-precision MMA. The search space also includes options of register-level packing and layout optimization to lesson overhead of handling reduced-precision data. Finally, we propose a search algorithm to find the best schedule by learning from the distinctive candidates. This reduced-precision MMA optimization method is evaluated on convolution operations of popular neural networks to demonstrate substantial speedup on Tensor Core compared to the state of the arts with shortened search time.
NN-LUT: Neural Approximation of Non-Linear Operations for Efficient Transformer Inference
Dec 03, 2021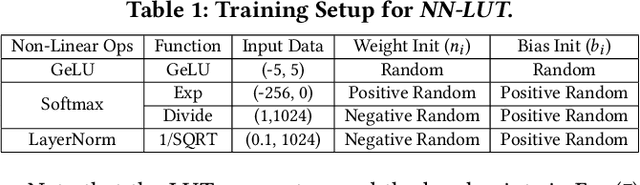
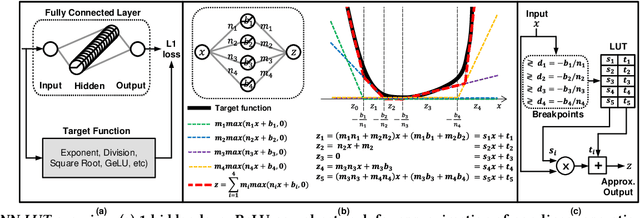
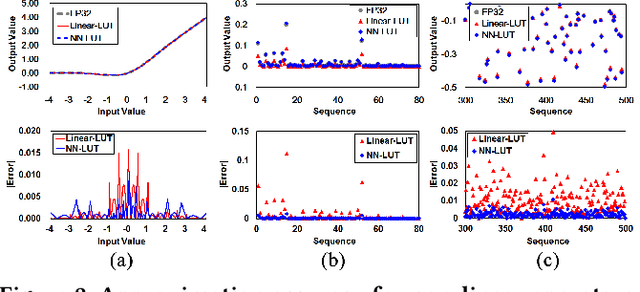
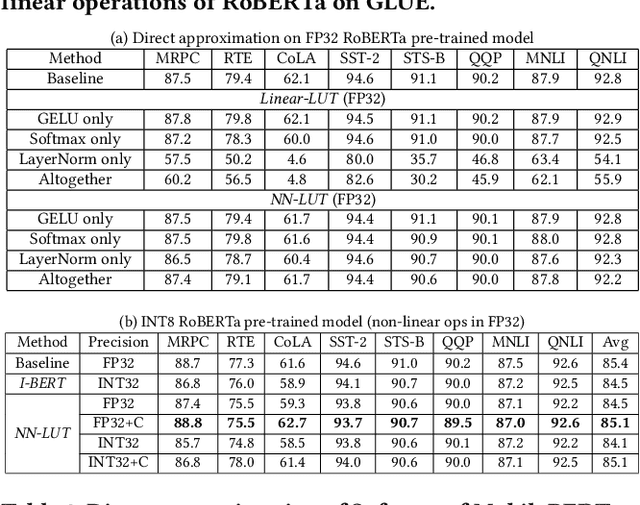
Non-linear operations such as GELU, Layer normalization, and Softmax are essential yet costly building blocks of Transformer models. Several prior works simplified these operations with look-up tables or integer computations, but such approximations suffer inferior accuracy or considerable hardware cost with long latency. This paper proposes an accurate and hardware-friendly approximation framework for efficient Transformer inference. Our framework employs a simple neural network as a universal approximator with its structure equivalently transformed into a LUT. The proposed framework called NN-LUT can accurately replace all the non-linear operations in popular BERT models with significant reductions in area, power consumption, and latency.
Layer-wise Pruning of Transformer Attention Heads for Efficient Language Modeling
Oct 07, 2021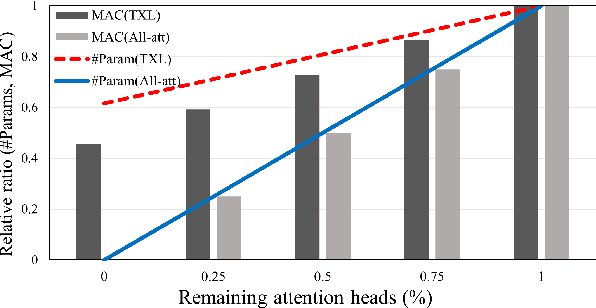
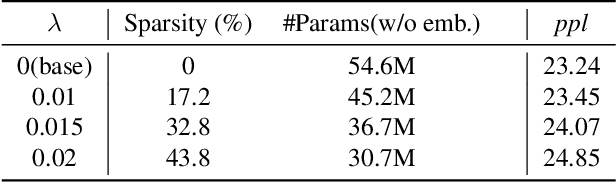
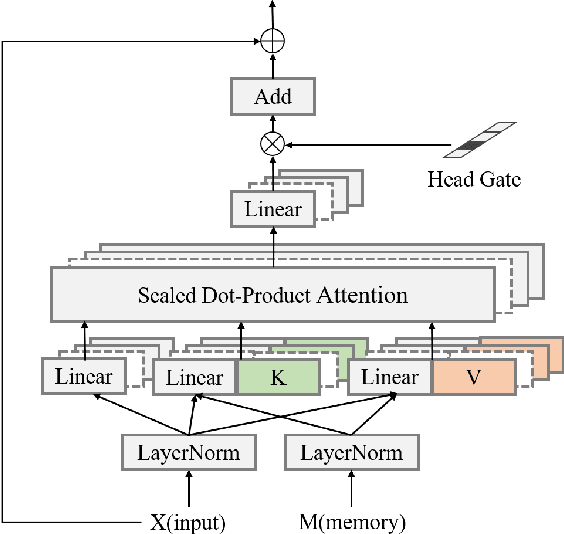
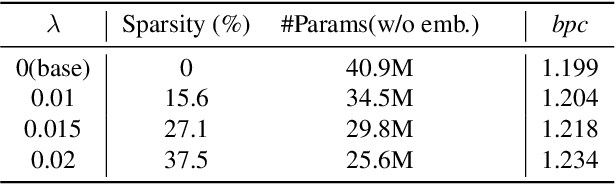
While Transformer-based models have shown impressive language modeling performance, the large computation cost is often prohibitive for practical use. Attention head pruning, which removes unnecessary attention heads in the multihead attention, is a promising technique to solve this problem. However, it does not evenly reduce the overall load because the heavy feedforward module is not affected by head pruning. In this paper, we apply layer-wise attention head pruning on All-attention Transformer so that the entire computation and the number of parameters can be reduced proportionally to the number of pruned heads. While the architecture has the potential to fully utilize head pruning, we propose three training methods that are especially helpful to minimize performance degradation and stabilize the pruning process. Our pruned model shows consistently lower perplexity within a comparable parameter size than Transformer-XL on WikiText-103 language modeling benchmark.
Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead
Jan 04, 2021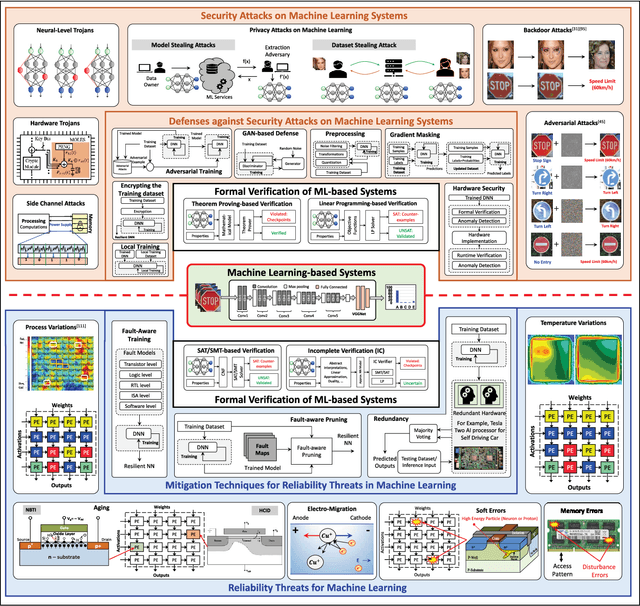
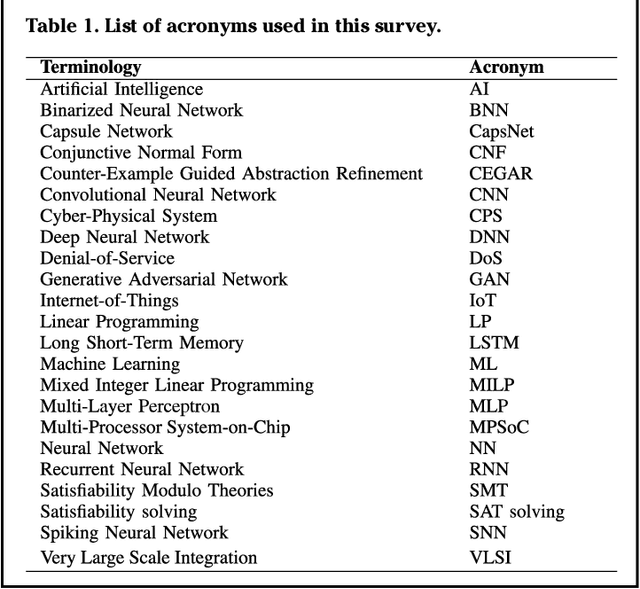

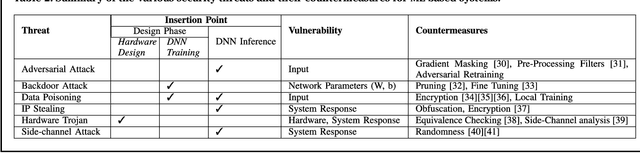
Machine Learning (ML) techniques have been rapidly adopted by smart Cyber-Physical Systems (CPS) and Internet-of-Things (IoT) due to their powerful decision-making capabilities. However, they are vulnerable to various security and reliability threats, at both hardware and software levels, that compromise their accuracy. These threats get aggravated in emerging edge ML devices that have stringent constraints in terms of resources (e.g., compute, memory, power/energy), and that therefore cannot employ costly security and reliability measures. Security, reliability, and vulnerability mitigation techniques span from network security measures to hardware protection, with an increased interest towards formal verification of trained ML models. This paper summarizes the prominent vulnerabilities of modern ML systems, highlights successful defenses and mitigation techniques against these vulnerabilities, both at the cloud (i.e., during the ML training phase) and edge (i.e., during the ML inference stage), discusses the implications of a resource-constrained design on the reliability and security of the system, identifies verification methodologies to ensure correct system behavior, and describes open research challenges for building secure and reliable ML systems at both the edge and the cloud.
* Final version appears in https://ieeexplore.ieee.org/document/8979377