 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReQAT: Achieving Full-Precision Reasoning Accuracy with 4-bit Floating-Point Quantization-Aware Training
Jun 14, 2026Large Reasoning Models (LRMs) achieve strong problem-solving through long chain-of-thought, but their deployment is constrained by the high cost of full-precision inference and growing KV cache footprints. Microscaled FP4 formats enable efficient FP4 deployment; however, fully quantizing weights, activations, and KV caches (W4A4KV4) causes severe reasoning degradation that existing PTQ and QAT fail to recover. We identify that FP4 failures concentrate on low-entropy tokens--precise symbolic commitments such as digits and operators--where quantization noise inflates sampling errors that cascade through reasoning traces. Based on this insight, we propose ReQAT, a reasoning-centric FP4 training framework with three components: (i) Trace-Aligned QAT (TAQ), which revisits identical reasoning traces to focus updates on critical low-entropy decisions; (ii) Selective Entropy Minimization (SEM), which reinforces confidence at low-entropy positions; and (iii) Q-FIT, a quantization-friendly initialization that jointly calibrates RoPE-consistent KV cache transformations to stabilize QAT. Under the same training budget, ReQAT not only recovers but surpasses BF16 fine-tuning accuracy, while delivering up to 3.9x throughput speedup on NVIDIA DGX Spark and 3.1x on B200.
Automatic Network Adaptation for Ultra-Low Uniform-Precision Quantization
Jan 04, 2023Uniform-precision neural network quantization has gained popularity since it simplifies densely packed arithmetic unit for high computing capability. However, it ignores heterogeneous sensitivity to the impact of quantization errors across the layers, resulting in sub-optimal inference accuracy. This work proposes a novel neural architecture search called neural channel expansion that adjusts the network structure to alleviate accuracy degradation from ultra-low uniform-precision quantization. The proposed method selectively expands channels for the quantization sensitive layers while satisfying hardware constraints (e.g., FLOPs, PARAMs). Based on in-depth analysis and experiments, we demonstrate that the proposed method can adapt several popular networks channels to achieve superior 2-bit quantization accuracy on CIFAR10 and ImageNet. In particular, we achieve the best-to-date Top-1/Top-5 accuracy for 2-bit ResNet50 with smaller FLOPs and the parameter size.
Learning from distinctive candidates to optimize reduced-precision convolution program on tensor cores
Feb 24, 2022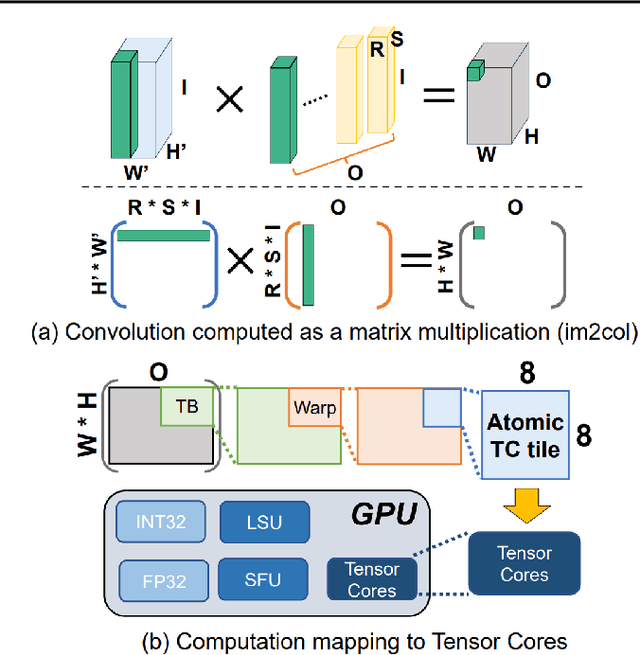
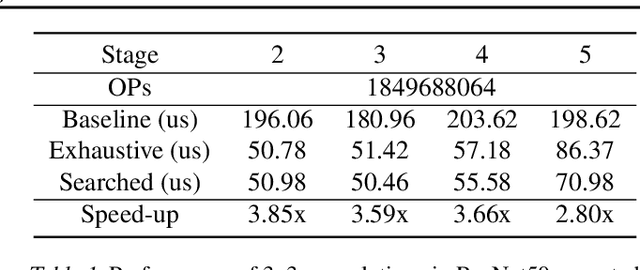
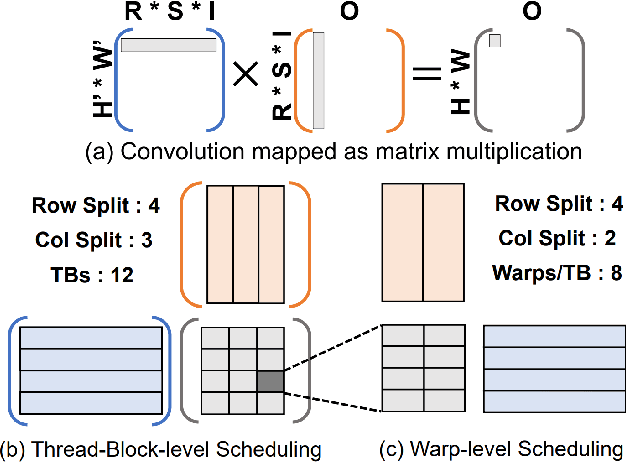
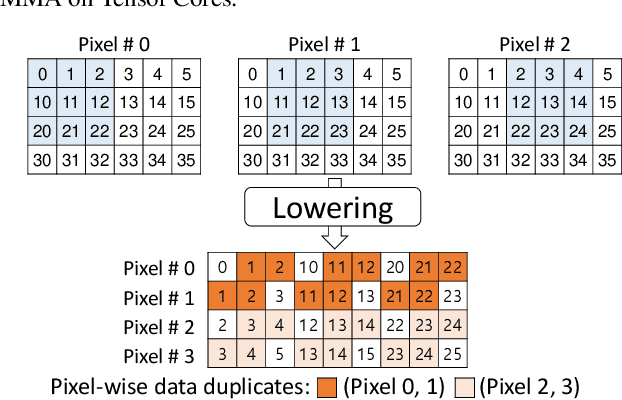
Convolution is one of the fundamental operations of deep neural networks with demanding matrix computation. In a graphic processing unit (GPU), Tensor Core is a specialized matrix processing hardware equipped with reduced-precision matrix-multiply-accumulate (MMA) instructions to increase throughput. However, it is challenging to achieve optimal performance since the best scheduling of MMA instructions varies for different convolution sizes. In particular, reduced-precision MMA requires many elements grouped as a matrix operand, seriously limiting data reuse and imposing packing and layout overhead on the schedule. This work proposes an automatic scheduling method of reduced-precision MMA for convolution operation. In this method, we devise a search space that explores the thread tile and warp sizes to increase the data reuse despite a large matrix operand of reduced-precision MMA. The search space also includes options of register-level packing and layout optimization to lesson overhead of handling reduced-precision data. Finally, we propose a search algorithm to find the best schedule by learning from the distinctive candidates. This reduced-precision MMA optimization method is evaluated on convolution operations of popular neural networks to demonstrate substantial speedup on Tensor Core compared to the state of the arts with shortened search time.