 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClip4Retrofit: Enabling Real-Time Image Labeling on Edge Devices via Cross-Architecture CLIP Distillation
May 23, 2025Foundation models like CLIP (Contrastive Language-Image Pretraining) have revolutionized vision-language tasks by enabling zero-shot and few-shot learning through cross-modal alignment. However, their computational complexity and large memory footprint make them unsuitable for deployment on resource-constrained edge devices, such as in-car cameras used for image collection and real-time processing. To address this challenge, we propose Clip4Retrofit, an efficient model distillation framework that enables real-time image labeling on edge devices. The framework is deployed on the Retrofit camera, a cost-effective edge device retrofitted into thousands of vehicles, despite strict limitations on compute performance and memory. Our approach distills the knowledge of the CLIP model into a lightweight student model, combining EfficientNet-B3 with multi-layer perceptron (MLP) projection heads to preserve cross-modal alignment while significantly reducing computational requirements. We demonstrate that our distilled model achieves a balance between efficiency and performance, making it ideal for deployment in real-world scenarios. Experimental results show that Clip4Retrofit can perform real-time image labeling and object identification on edge devices with limited resources, offering a practical solution for applications such as autonomous driving and retrofitting existing systems. This work bridges the gap between state-of-the-art vision-language models and their deployment in resource-constrained environments, paving the way for broader adoption of foundation models in edge computing.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024



Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometry Constrained Keypoints in Real-Time
Jun 23, 2020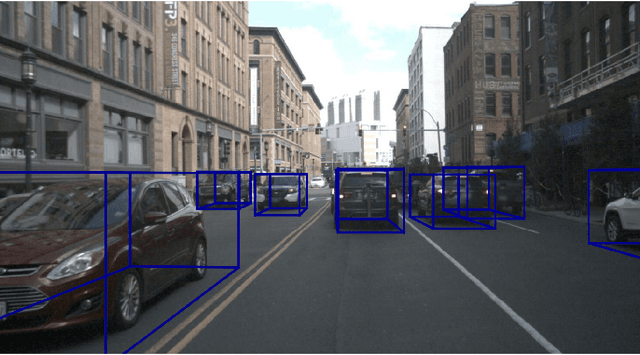
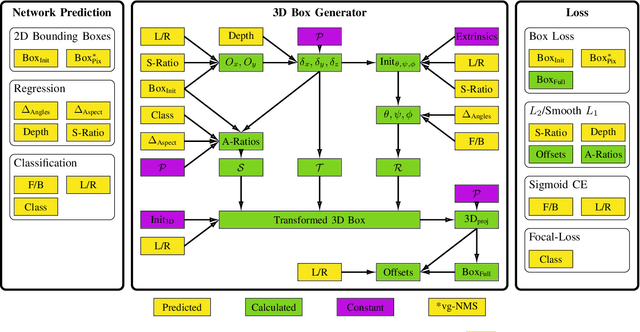
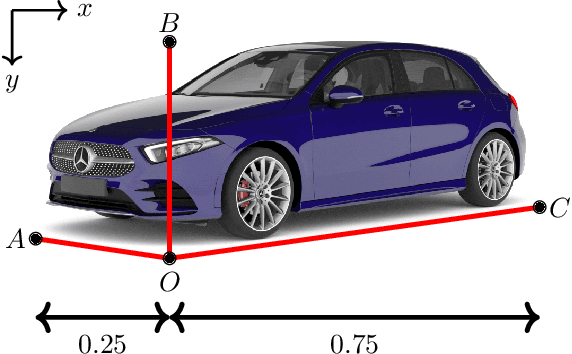

In this paper we propose a novel 3D single-shot object detection method for detecting vehicles in monocular RGB images. Our approach lifts 2D detections to 3D space by predicting additional regression and classification parameters and hence keeping the runtime close to pure 2D object detection. The additional parameters are transformed to 3D bounding box keypoints within the network under geometric constraints. Our proposed method features a full 3D description including all three angles of rotation without supervision by any labeled ground truth data for the object's orientation, as it focuses on certain keypoints within the image plane. While our approach can be combined with any modern object detection framework with only little computational overhead, we exemplify the extension of SSD for the prediction of 3D bounding boxes. We test our approach on different datasets for autonomous driving and evaluate it using the challenging KITTI 3D Object Detection as well as the novel nuScenes Object Detection benchmarks. While we achieve competitive results on both benchmarks we outperform current state-of-the-art methods in terms of speed with more than 20 FPS for all tested datasets and image resolutions.