 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Visual Features by Contrasting Cluster Assignments
Jul 17, 2020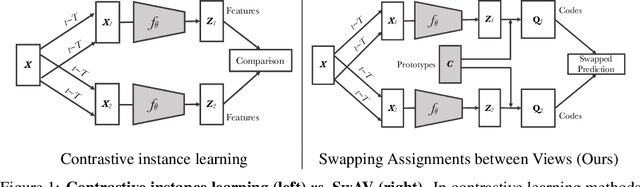
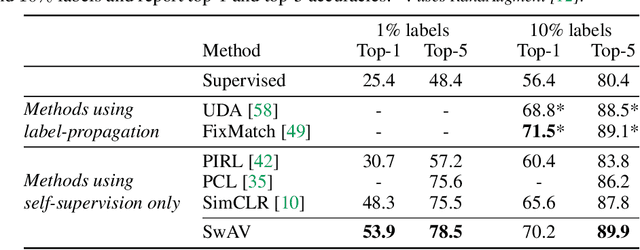
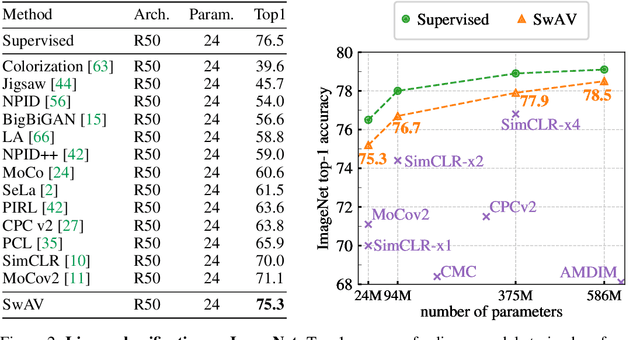

Unsupervised image representations have significantly reduced the gap with supervised pretraining, notably with the recent achievements of contrastive learning methods. These contrastive methods typically work online and rely on a large number of explicit pairwise feature comparisons, which is computationally challenging. In this paper, we propose an online algorithm, SwAV, that takes advantage of contrastive methods without requiring to compute pairwise comparisons. Specifically, our method simultaneously clusters the data while enforcing consistency between cluster assignments produced for different augmentations (or views) of the same image, instead of comparing features directly as in contrastive learning. Simply put, we use a swapped prediction mechanism where we predict the cluster assignment of a view from the representation of another view. Our method can be trained with large and small batches and can scale to unlimited amounts of data. Compared to previous contrastive methods, our method is more memory efficient since it does not require a large memory bank or a special momentum network. In addition, we also propose a new data augmentation strategy, multi-crop, that uses a mix of views with different resolutions in place of two full-resolution views, without increasing the memory or compute requirements much. We validate our findings by achieving 75.3% top-1 accuracy on ImageNet with ResNet-50, as well as surpassing supervised pretraining on all the considered transfer tasks.
Designing and Learning Trainable Priors with Non-Cooperative Games
Jun 26, 2020
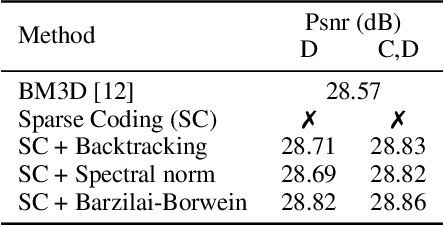
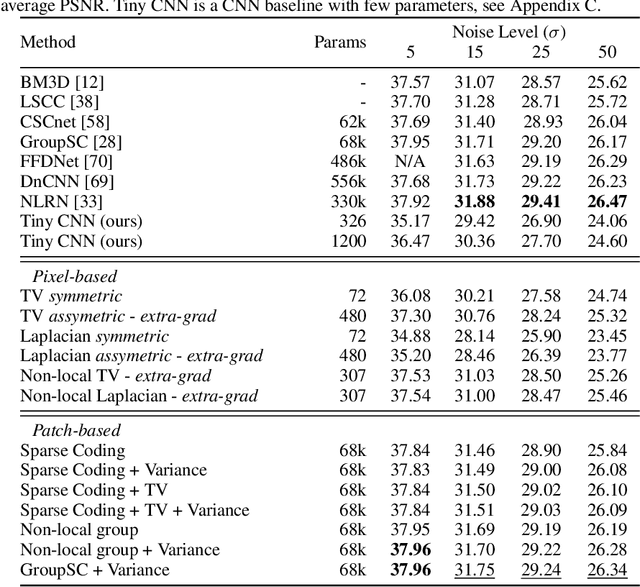
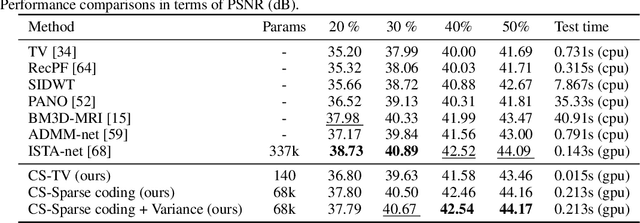
We introduce a general framework for designing and learning neural networks whose forward passes can be interpreted as solving convex optimization problems, and whose architectures are derived from an optimization algorithm. We focus on non-cooperative convex games, solved by local agents represented by the nodes of a graph and interacting through regularization functions. This approach is appealing for solving imaging problems, as it allows the use of classical image priors within deep models that are trainable end to end. The priors used in this presentation include variants of total variation, Laplacian regularization, sparse coding on learned dictionaries, and non-local self similarities. Our models are parameter efficient and fully interpretable, and our experiments demonstrate their effectiveness on a large diversity of tasks ranging from image denoising and compressed sensing for fMRI to dense stereo matching.
An Optimal Transport Kernel for Feature Aggregation and its Relationship to Attention
Jun 23, 2020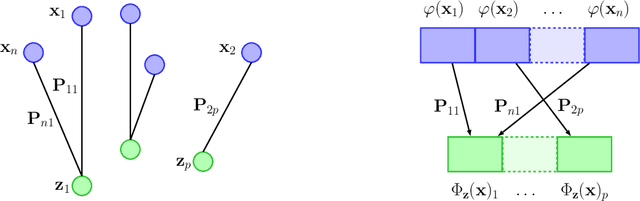
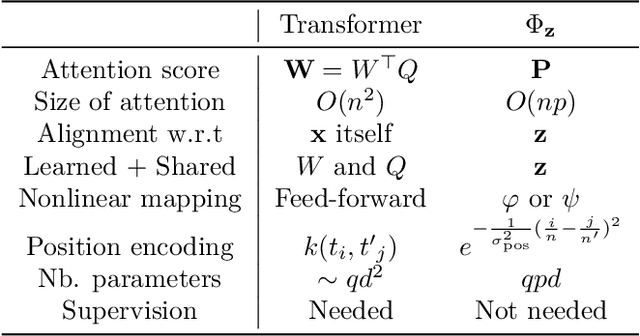
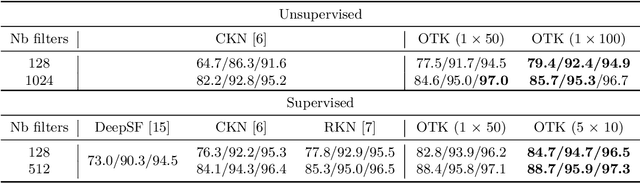
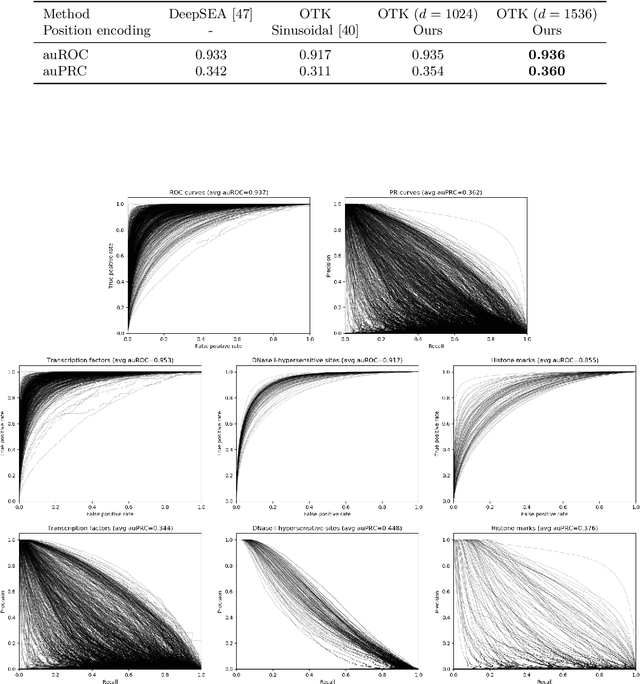
We introduce a kernel for sets of features based on an optimal transport distance, along with an explicit embedding function. Our approach addresses the problem of feature aggregation, or pooling, for sets that exhibit long-range dependencies between their members. More precisely, our embedding aggregates the features of a given set according to the transport plan between the set and a reference shared across the data set. Unlike traditional hand-crafted kernels, our embedding can be optimized for a specific task or data set. It also has a natural connection to attention mechanisms in neural networks, which are commonly used to deal with sets, yet requires less data. Our embedding is particularly suited for biological sequence classification tasks and shows promising results for natural language sequences. We provide an implementation of our embedding that can be used alone or as a module in larger learning models. Our code is freely available at https://github.com/claying/OTK.
Optimization Approaches for Counterfactual Risk Minimization with Continuous Actions
Apr 22, 2020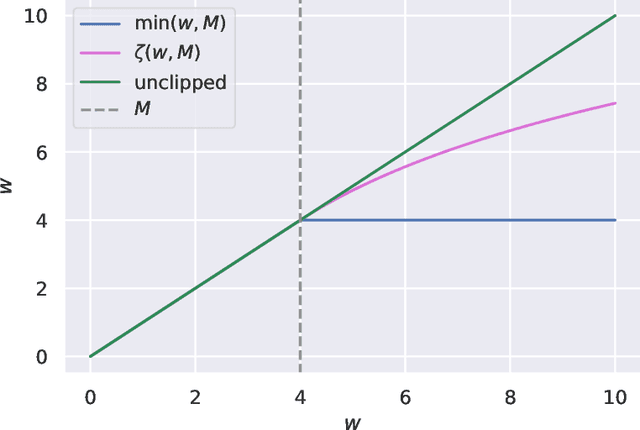
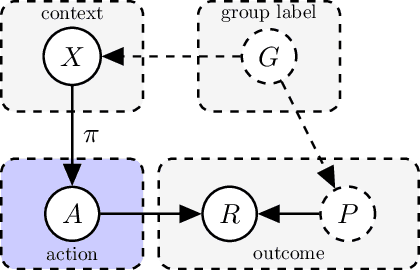
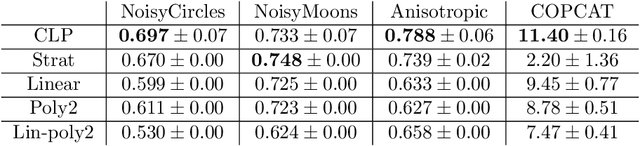

Counterfactual reasoning from logged data has become increasingly important for a large range of applications such as web advertising or healthcare. In this paper, we address the problem of counterfactual risk minimization for learning a stochastic policy with a continuous action space. Whereas previous works have mostly focused on deriving statistical estimators with importance sampling, we show that the optimization perspective is equally important for solving the resulting nonconvex optimization problems.Specifically, we demonstrate the benefits of proximal point algorithms and soft-clipping estimators which are more amenable to gradient-based optimization than classical hard clipping. We propose multiple synthetic, yet realistic, evaluation setups, and we release a new large-scale dataset based on web advertising data for this problem that is crucially missing public benchmarks.
Selecting Relevant Features from a Universal Representation for Few-shot Classification
Mar 20, 2020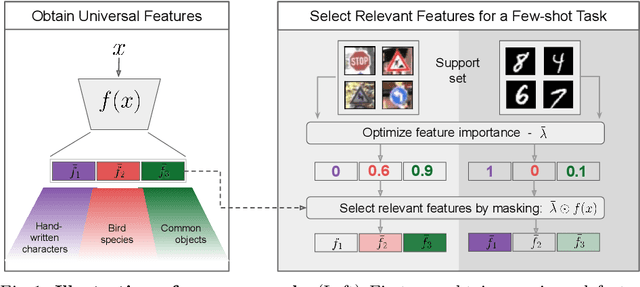
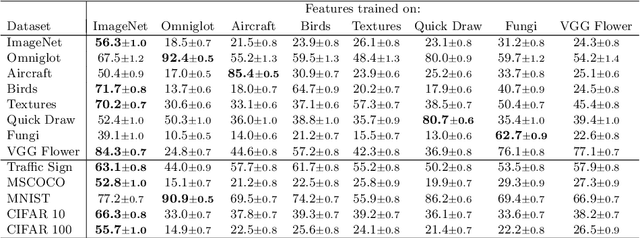
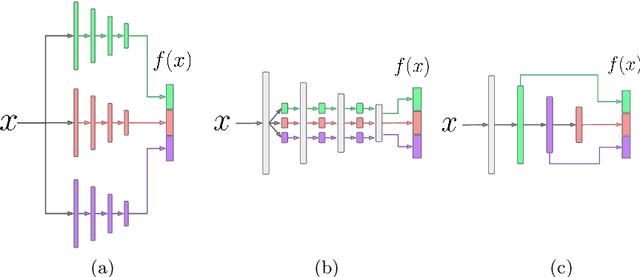
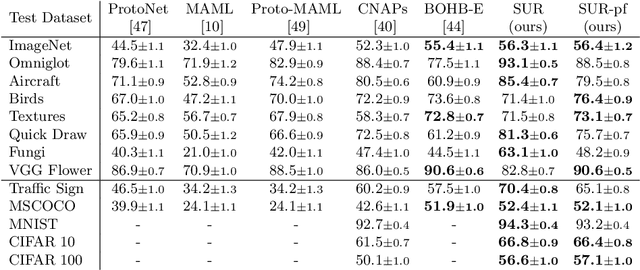
Popular approaches for few-shot classification consist of first learning a generic data representation based on a large annotated dataset, before adapting the representation to new classes given only a few labeled samples. In this work, we propose a new strategy based on feature selection, which is both simpler and more effective than previous feature adaptation approaches. First, we obtain a universal representation by training a set of semantically different feature extractors. Then, given a few-shot learning task, we use our universal feature bank to automatically select the most relevant representations. We show that a simple non-parametric classifier built on top of such features produces high accuracy and generalizes to domains never seen during training, which leads to state-of-the-art results on MetaDataset and improved accuracy on mini-ImageNet.
Convolutional Kernel Networks for Graph-Structured Data
Mar 11, 2020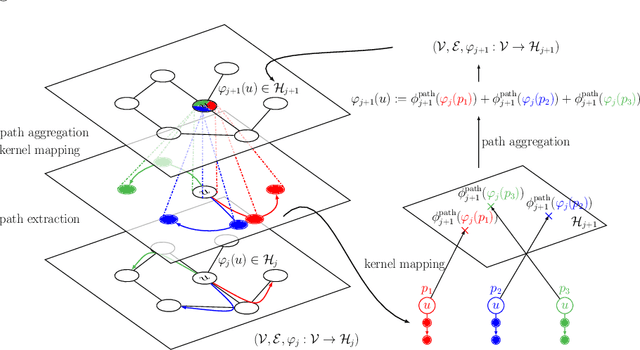
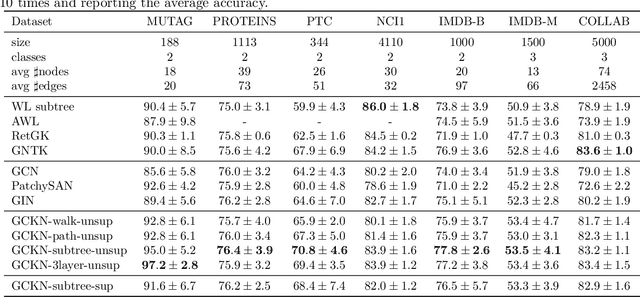
We introduce a family of multilayer graph kernels and establish new links between graph convolutional neural networks and kernel methods. Our approach generalizes convolutional kernel networks to graph-structured data, by representing graphs as a sequence of kernel feature maps, where each node carries information about local graph substructures. On the one hand, the kernel point of view offers an unsupervised, expressive, and easy-to-regularize data representation, which is useful when limited samples are available. On the other hand, our model can also be trained end-to-end on large-scale data, leading to new types of graph convolutional neural networks. We show that our method achieves competitive performance on several graph classification benchmarks, while offering simple model interpretation. Our code is freely available at https://github.com/claying/GCKN.
Revisiting Non Local Sparse Models for Image Restoration
Jan 28, 2020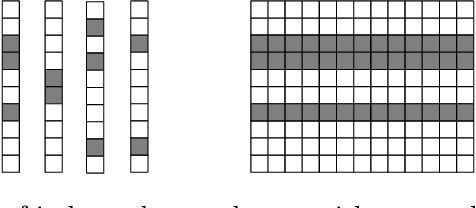


We propose a differentiable algorithm for image restoration inspired by the success of sparse models and self-similarity priors for natural images. Our approach builds upon the concept of joint sparsity between groups of similar image patches, and we show how this simple idea can be implemented in a differentiable architecture, allowing end-to-end training. The algorithm has the advantage of being interpretable, performing sparse decompositions of image patches, while being more parameter efficient than recent deep learning methods. We evaluate our algorithm on grayscale and color denoising, where we achieve competitive results, and on demoisaicking, where we outperform the most recent state-of-the-art deep learning model with 47 times less parameters and a much shallower architecture.
Pruning Convolutional Neural Networks with Self-Supervision
Jan 10, 2020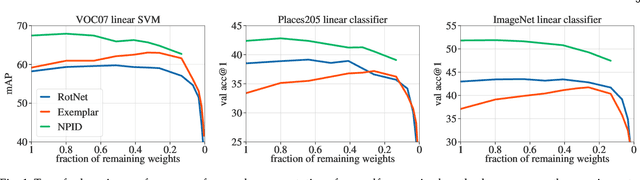
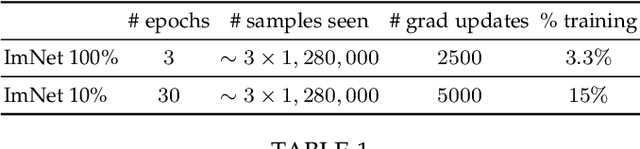
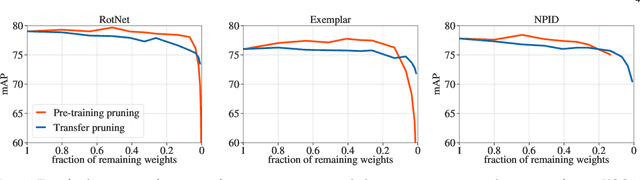
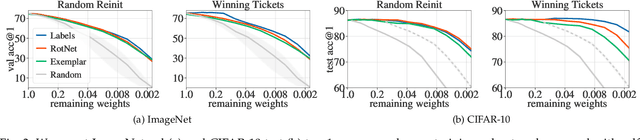
Convolutional neural networks trained without supervision come close to matching performance with supervised pre-training, but sometimes at the cost of an even higher number of parameters. Extracting subnetworks from these large unsupervised convnets with preserved performance is of particular interest to make them less computationally intensive. Typical pruning methods operate during training on a task while trying to maintain the performance of the pruned network on the same task. However, in self-supervised feature learning, the training objective is agnostic on the representation transferability to downstream tasks. Thus, preserving performance for this objective does not ensure that the pruned subnetwork remains effective for solving downstream tasks. In this work, we investigate the use of standard pruning methods, developed primarily for supervised learning, for networks trained without labels (i.e. on self-supervised tasks). We show that pruned masks obtained with or without labels reach comparable performance when re-trained on labels, suggesting that pruning operates similarly for self-supervised and supervised learning. Interestingly, we also find that pruning preserves the transfer performance of self-supervised subnetwork representations.
Cyanure: An Open-Source Toolbox for Empirical Risk Minimization for Python, C++, and soon more
Dec 20, 2019
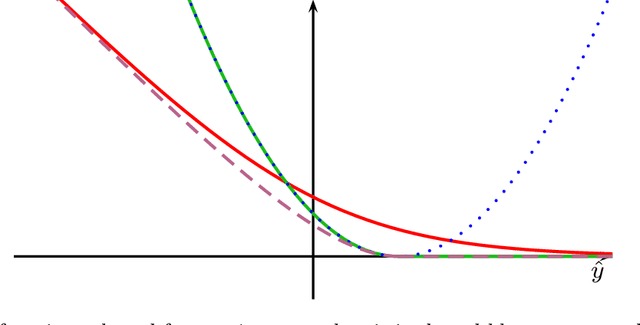
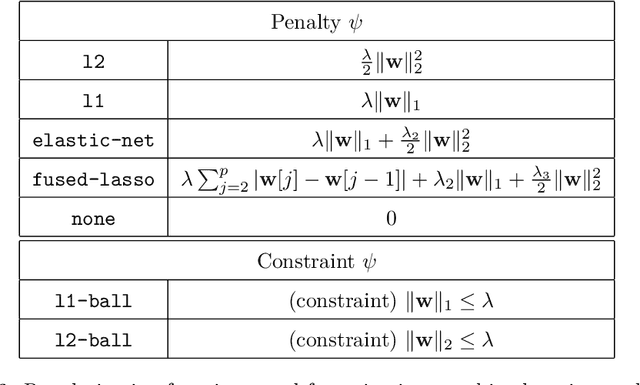
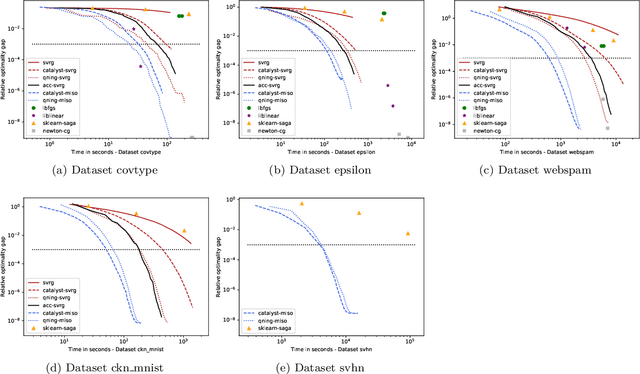
Cyanure is an open-source C++ software package with a Python interface. The goal of Cyanure is to provide state-of-the-art solvers for learning linear models, based on stochastic variance-reduced stochastic optimization with acceleration mechanisms. Cyanure can handle a large variety of loss functions (logistic, square, squared hinge, multinomial logistic) and regularization functions (l_2, l_1, elastic-net, fused Lasso, multi-task group Lasso). It provides a simple Python API, which is very close to that of scikit-learn, which should be extended to other languages such as R or Matlab in a near future.
Screening Data Points in Empirical Risk Minimization via Ellipsoidal Regions and Safe Loss Function
Dec 05, 2019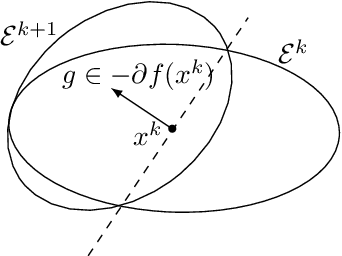
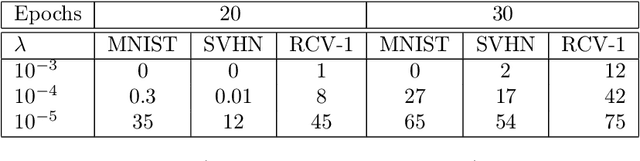
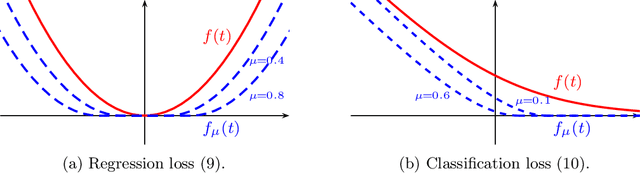
We design simple screening tests to automatically discard data samples in empirical risk minimization without losing optimization guarantees. We derive loss functions that produce dual objectives with a sparse solution. We also show how to regularize convex losses to ensure such a dual sparsity-inducing property, and propose a general method to design screening tests for classification or regression based on ellipsoidal approximations of the optimal set. In addition to producing computational gains, our approach also allows us to compress a dataset into a subset of representative points.