 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement of Generative AI Workload Power Profiles for Whole-Facility Data Center Infrastructure Planning
Apr 08, 2026The rapid growth of generative artificial intelligence (AI) has introduced unprecedented computational demands, driving significant increases in the energy footprint of data centers. However, existing power consumption data is largely proprietary and reported at varying resolutions, creating challenges for estimating whole-facility energy use and planning infrastructure. In this work, we present a methodology that bridges this gap by linking high-resolution workload power measurements to whole-facility energy demand. Using NLR's high-performance computing data center equipped with NVIDIA H100 GPUs, we measure power consumption of AI workloads at 0.1-second resolution for AI training, fine-tuning and inference jobs. Workloads are characterized using MLCommons benchmarks for model training and fine-tuning, and vLLM benchmarks for inference, enabling reproducible and standardized workload profiling. The dataset of power consumption profiles is made publicly available. These power profiles are then scaled to the whole-facility-level using a bottom-up, event-driven, data center energy model. The resulting whole-facility energy profiles capture realistic temporal fluctuations driven by AI workloads and user-behavior, and can be used to inform infrastructure planning for grid connection, on-site energy generation, and distributed microgrids.
Practical Efficient Global Optimization is No-regret
Mar 26, 2026Efficient global optimization (EGO) is one of the most widely used noise-free Bayesian optimization algorithms.It comprises the Gaussian process (GP) surrogate model and expected improvement (EI) acquisition function. In practice, when EGO is applied, a scalar matrix of a small positive value (also called a nugget or jitter) is usually added to the covariance matrix of the deterministic GP to improve numerical stability. We refer to this EGO with a positive nugget as the practical EGO. Despite its wide adoption and empirical success, to date, cumulative regret bounds for practical EGO have yet to be established. In this paper, we present for the first time the cumulative regret upper bound of practical EGO. In particular, we show that practical EGO has sublinear cumulative regret bounds and thus is a no-regret algorithm for commonly used kernels including the squared exponential (SE) and Matérn kernels ($ν>\frac{1}{2}$). Moreover, we analyze the effect of the nugget on the regret bound and discuss the theoretical implication on its choice. Numerical experiments are conducted to support and validate our findings.
A Self-Supervised Approach to Reconstruction in Sparse X-Ray Computed Tomography
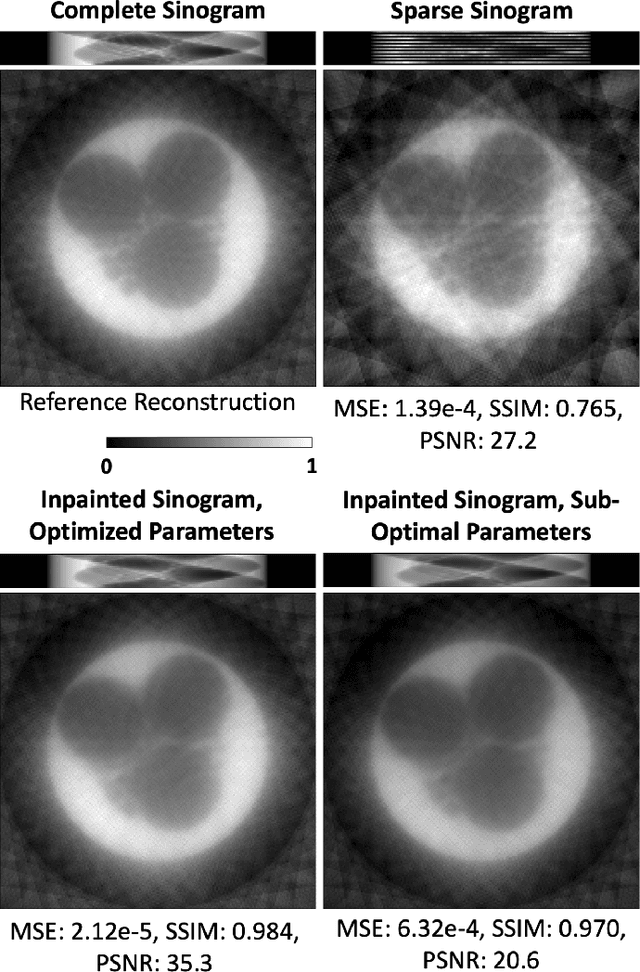
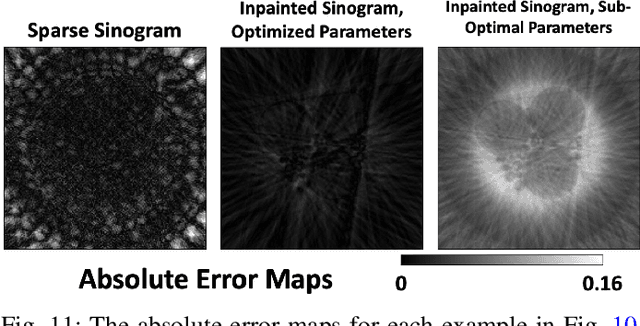
Oct 30, 2022Computed tomography has propelled scientific advances in fields from biology to materials science. This technology allows for the elucidation of 3-dimensional internal structure by the attenuation of x-rays through an object at different rotations relative to the beam. By imaging 2-dimensional projections, a 3-dimensional object can be reconstructed through a computational algorithm. Imaging at a greater number of rotation angles allows for improved reconstruction. However, taking more measurements increases the x-ray dose and may cause sample damage. Deep neural networks have been used to transform sparse 2-D projection measurements to a 3-D reconstruction by training on a dataset of known similar objects. However, obtaining high-quality object reconstructions for the training dataset requires high x-ray dose measurements that can destroy or alter the specimen before imaging is complete. This becomes a chicken-and-egg problem: high-quality reconstructions cannot be generated without deep learning, and the deep neural network cannot be learned without the reconstructions. This work develops and validates a self-supervised probabilistic deep learning technique, the physics-informed variational autoencoder, to solve this problem. A dataset consisting solely of sparse projection measurements from each object is used to jointly reconstruct all objects of the set. This approach has the potential to allow visualization of fragile samples with x-ray computed tomography. We release our code for reproducing our results at: https://github.com/vganapati/CT_PVAE .
Hyperparameter Optimization of Generative Adversarial Network Models for High-Energy Physics Simulations
Aug 12, 2022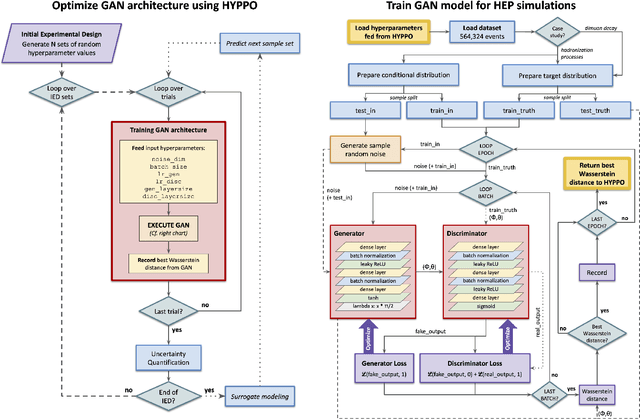
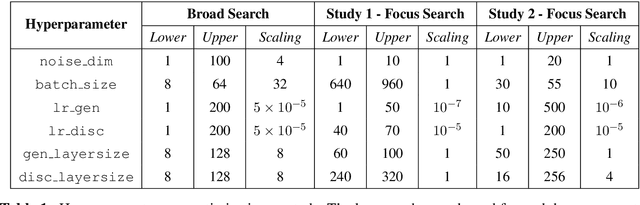
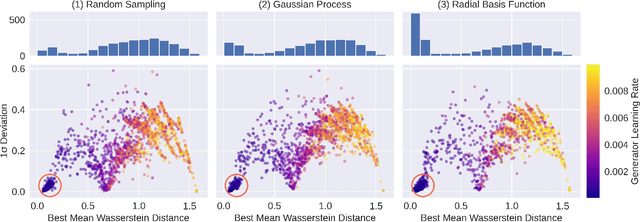
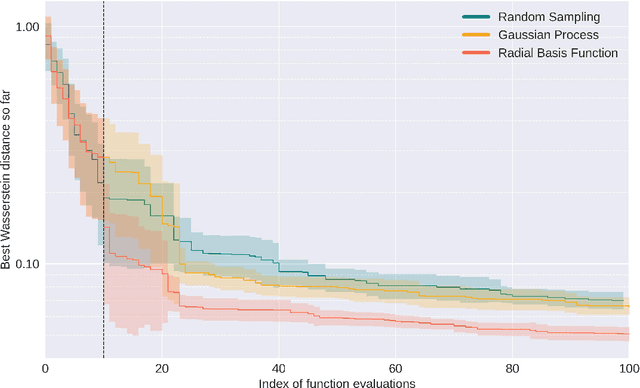
The Generative Adversarial Network (GAN) is a powerful and flexible tool that can generate high-fidelity synthesized data by learning. It has seen many applications in simulating events in High Energy Physics (HEP), including simulating detector responses and physics events. However, training GANs is notoriously hard and optimizing their hyperparameters even more so. It normally requires many trial-and-error training attempts to force a stable training and reach a reasonable fidelity. Significant tuning work has to be done to achieve the accuracy required by physics analyses. This work uses the physics-agnostic and high-performance-computer-friendly hyperparameter optimization tool HYPPO to optimize and examine the sensitivities of the hyperparameters of a GAN for two independent HEP datasets. This work provides the first insights into efficiently tuning GANs for Large Hadron Collider data. We show that given proper hyperparameter tuning, we can find GANs that provide high-quality approximations of the desired quantities. We also provide guidelines for how to go about GAN architecture tuning using the analysis tools in HYPPO.
HYPPO: A Surrogate-Based Multi-Level Parallelism Tool for Hyperparameter Optimization
Oct 04, 2021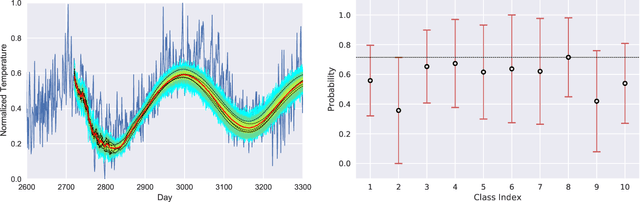
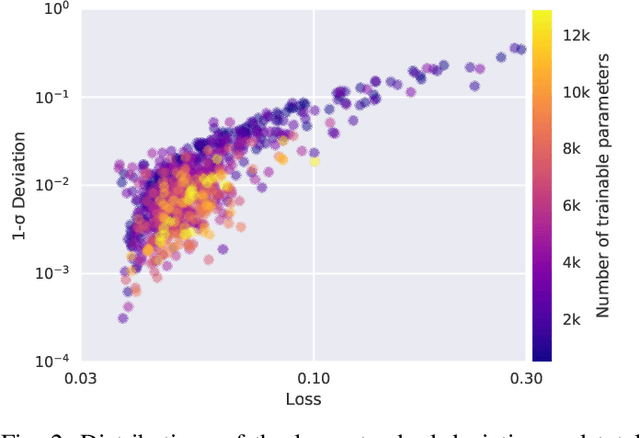
We present a new software, HYPPO, that enables the automatic tuning of hyperparameters of various deep learning (DL) models. Unlike other hyperparameter optimization (HPO) methods, HYPPO uses adaptive surrogate models and directly accounts for uncertainty in model predictions to find accurate and reliable models that make robust predictions. Using asynchronous nested parallelism, we are able to significantly alleviate the computational burden of training complex architectures and quantifying the uncertainty. HYPPO is implemented in Python and can be used with both TensorFlow and PyTorch libraries. We demonstrate various software features on time-series prediction and image classification problems as well as a scientific application in computed tomography image reconstruction. Finally, we show that (1) we can reduce by an order of magnitude the number of evaluations necessary to find the most optimal region in the hyperparameter space and (2) we can reduce by two orders of magnitude the throughput for such HPO process to complete.
Surrogate Optimization of Deep Neural Networks for Groundwater Predictions
Aug 30, 2019

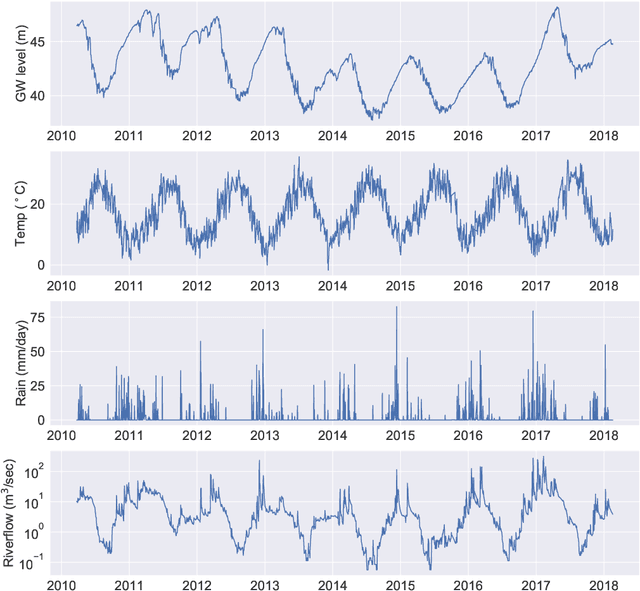

Sustainable management of groundwater resources under changing climatic conditions require an application of reliable and accurate predictions of groundwater levels. Mechanistic multi-scale, multi-physics simulation models are often too hard to use for this purpose, especially for groundwater managers who do not have access to the complex compute resources and data. Therefore, we analyzed the applicability and performance of four modern deep learning computational models for predictions of groundwater levels. We compare three methods for optimizing the models' hyperparameters, including two surrogate model-based algorithms and a random sampling method. The models were tested using predictions of the groundwater level in Butte County, California, USA, taking into account the temporal variability of streamflow, precipitation, and ambient temperature. Our numerical study shows that the optimization of the hyperparameters can lead to reasonably accurate performance of all models, but the "simplest" network, namely a multilayer perceptron (MLP) performs overall better for learning and predicting groundwater data than the more advanced long short-term memory or convolutional neural networks in terms of prediction accuracy and time-to-solution, making the MLP a suitable candidate for groundwater prediction.