 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Keystroke Synthesis for Improved Bot Detection
Jul 28, 2022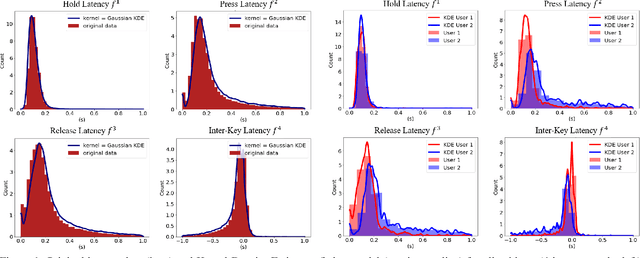
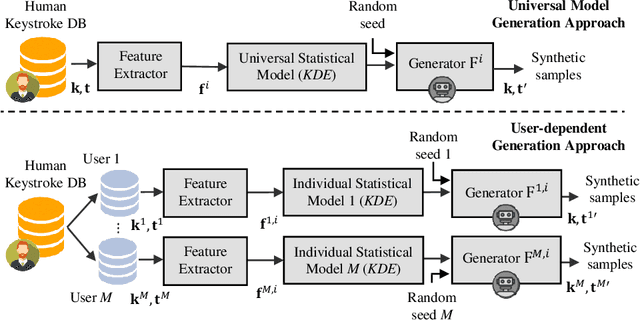
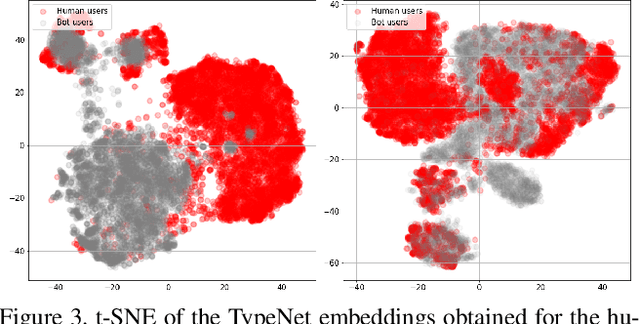
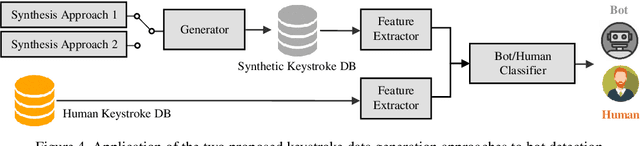
This work proposes two statistical approaches for the synthesis of keystroke biometric data based on Universal and User-dependent Models. Both approaches are validated on the bot detection task, using the keystroke synthetic data to better train the systems. Our experiments include a dataset with 136 million keystroke events from 168,000 subjects. We have analyzed the performance of the two synthesis approaches through qualitative and quantitative experiments. Different bot detectors are considered based on two supervised classifiers (Support Vector Machine and Long Short-Term Memory network) and a learning framework including human and generated samples. Our results prove that the proposed statistical approaches are able to generate realistic human-like synthetic keystroke samples. Also, the classification results suggest that in scenarios with large labeled data, these synthetic samples can be detected with high accuracy. However, in few-shot learning scenarios it represents an important challenge.
Fingerprint Liveness Detection Based on Quality Measures
Jul 11, 2022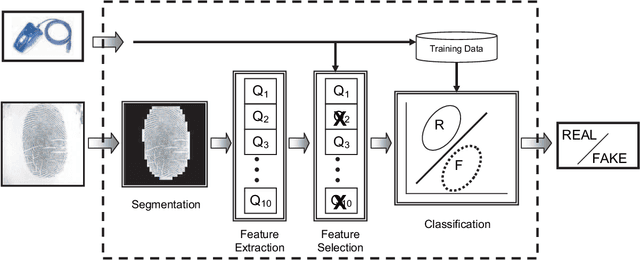
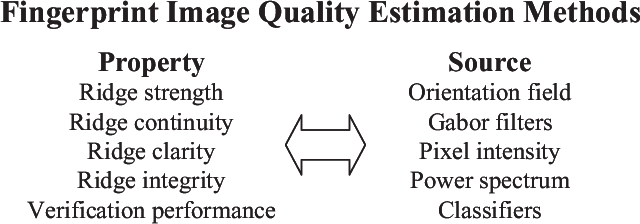

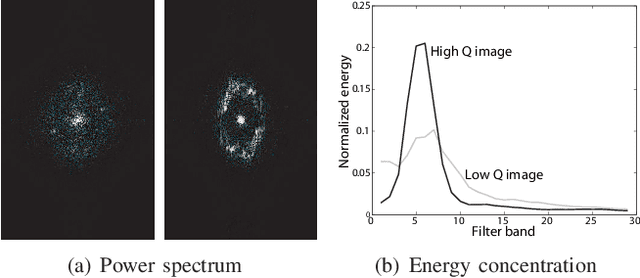
A new fingerprint parameterization for liveness detection based on quality measures is presented. The novel feature set is used in a complete liveness detection system and tested on the development set of the LivDET competition, comprising over 4,500 real and fake images acquired with three different optical sensors. The proposed solution proves to be robust to the multi-sensor scenario, and presents an overall rate of 93% of correctly classified samples. Furthermore, the liveness detection method presented has the added advantage over previously studied techniques of needing just one image from a finger to decide whether it is real or fake.
Biometric Signature Verification Using Recurrent Neural Networks
May 03, 2022
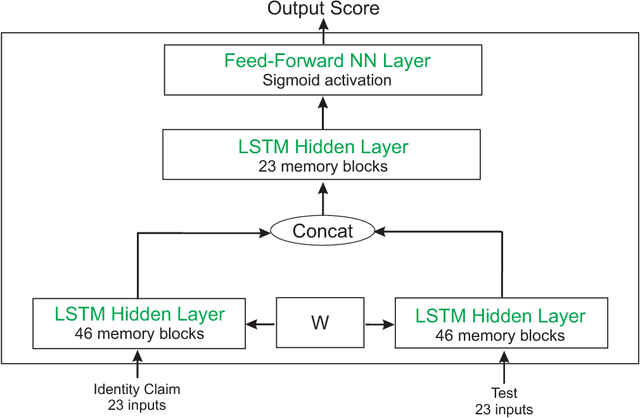
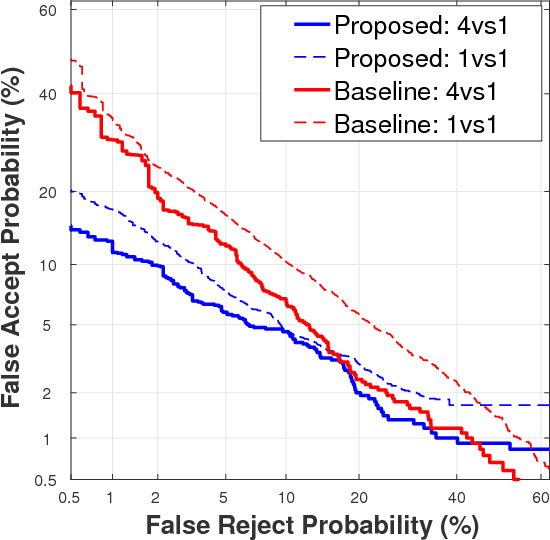
Architectures based on Recurrent Neural Networks (RNNs) have been successfully applied to many different tasks such as speech or handwriting recognition with state-of-the-art results. The main contribution of this work is to analyse the feasibility of RNNs for on-line signature verification in real practical scenarios. We have considered a system based on Long Short-Term Memory (LSTM) with a Siamese architecture whose goal is to learn a similarity metric from pairs of signatures. For the experimental work, the BiosecurID database comprised of 400 users and 4 separated acquisition sessions are considered. Our proposed LSTM RNN system has outperformed the results of recent published works on the BiosecurID benchmark in figures ranging from 17.76% to 28.00% relative verification performance improvement for skilled forgeries.
BioTouchPass: Handwritten Passwords for Touchscreen Biometrics
May 03, 2022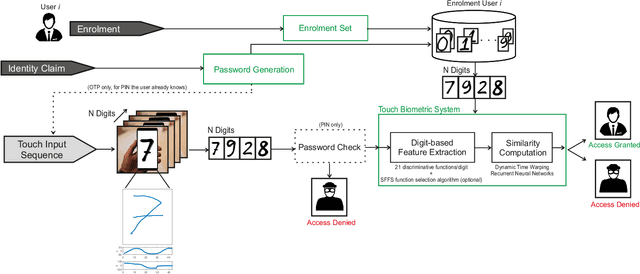
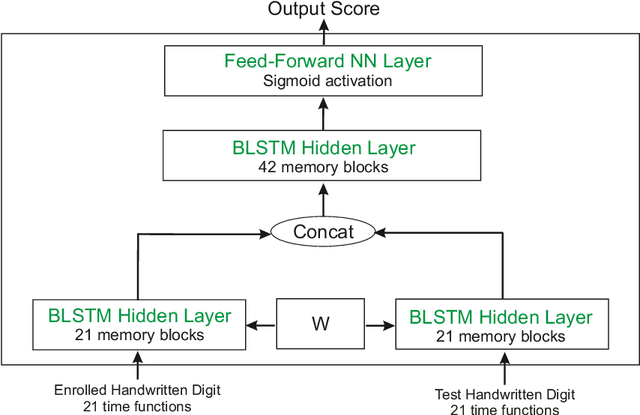
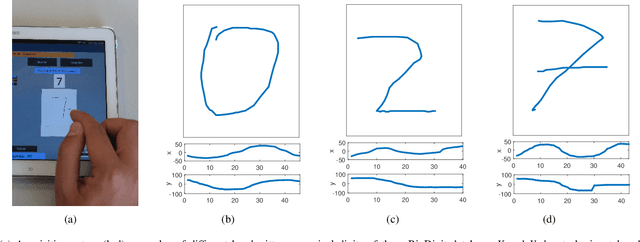
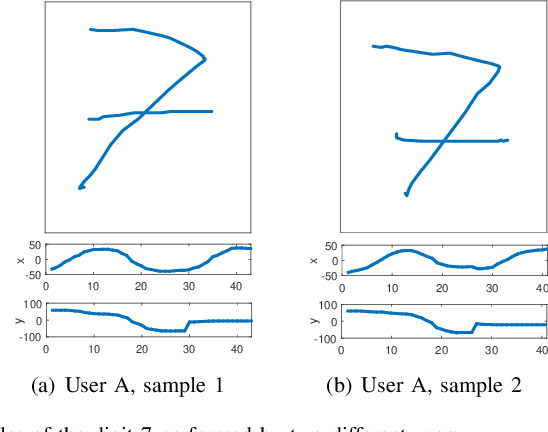
This work enhances traditional authentication systems based on Personal Identification Numbers (PIN) and One-Time Passwords (OTP) through the incorporation of biometric information as a second level of user authentication. In our proposed approach, users draw each digit of the password on the touchscreen of the device instead of typing them as usual. A complete analysis of our proposed biometric system is carried out regarding the discriminative power of each handwritten digit and the robustness when increasing the length of the password and the number of enrolment samples. The new e-BioDigit database, which comprises on-line handwritten digits from 0 to 9, has been acquired using the finger as input on a mobile device. This database is used in the experiments reported in this work and it is available together with benchmark results in GitHub. Finally, we discuss specific details for the deployment of our proposed approach on current PIN and OTP systems, achieving results with Equal Error Rates (EERs) ca. 4.0% when the attacker knows the password. These results encourage the deployment of our proposed approach in comparison to traditional PIN and OTP systems where the attack would have 100% success rate under the same impostor scenario.
* arXiv admin note: text overlap with arXiv:2001.10223
Super-Resolution for Selfie Biometrics: Introduction and Application to Face and Iris
Apr 12, 2022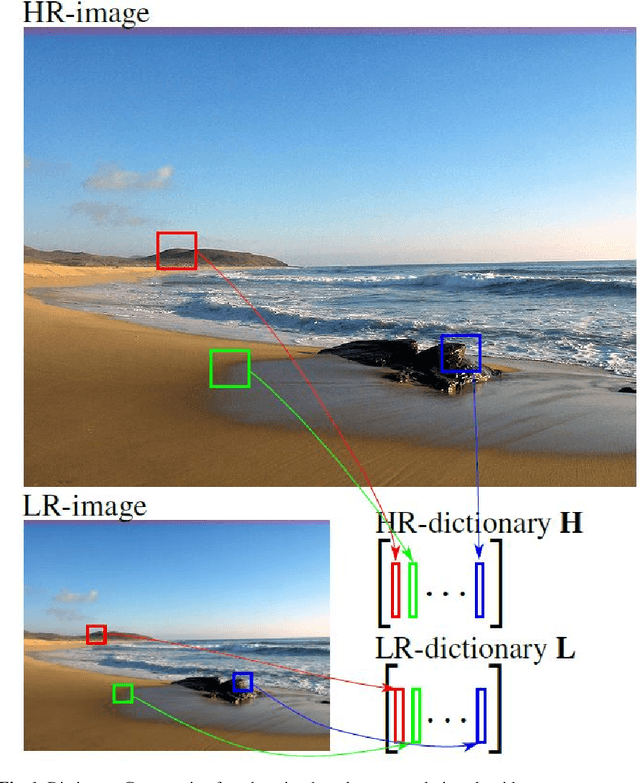
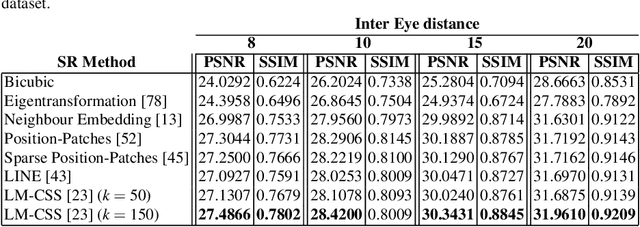
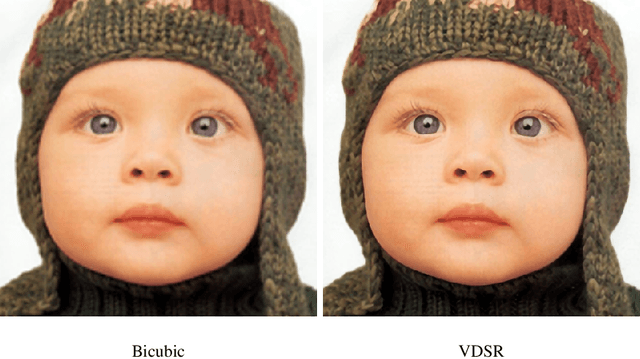
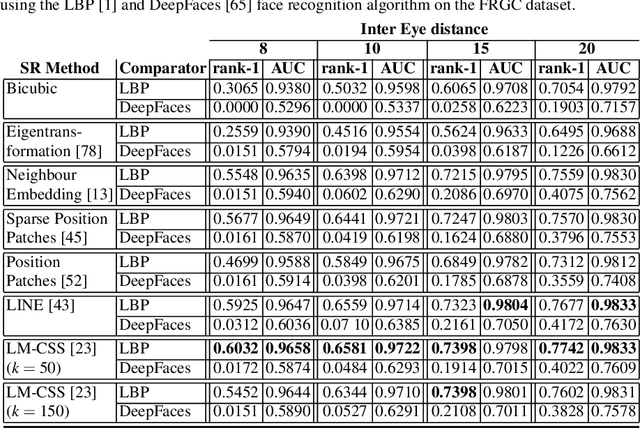
The lack of resolution has a negative impact on the performance of image-based biometrics. Many applications which are becoming ubiquitous in mobile devices do not operate in a controlled environment, and their performance significantly drops due to the lack of pixel resolution. While many generic super-resolution techniques have been studied to restore low-resolution images for biometrics, the results obtained are not always as desired. Those generic methods are usually aimed to enhance the visual appearance of the scene. However, producing an overall visual enhancement of biometric images does not necessarily correlate with a better recognition performance. Such techniques are designed to restore generic images and therefore do not exploit the specific structure found in biometric images (e.g. iris or faces), which causes the solution to be sub-optimal. For this reason, super-resolution techniques have to be adapted for the particularities of images from a specific biometric modality. In recent years, there has been an increased interest in the application of super-resolution to different biometric modalities, such as face iris, gait or fingerprint. This chapter presents an overview of recent advances in super-resolution reconstruction of face and iris images, which are the two prevalent modalities in selfie biometrics. We also provide experimental results using several state-of-the-art reconstruction algorithms, demonstrating the benefits of using super-resolution to improve the quality of face and iris images prior to classification. In the reported experiments, we study the application of super-resolution to face and iris images captured in the visible range, using experimental setups that represent well the selfie biometrics scenario.
Handwriting Biometrics: Applications and Future Trends in e-Security and e-Health
Feb 24, 2022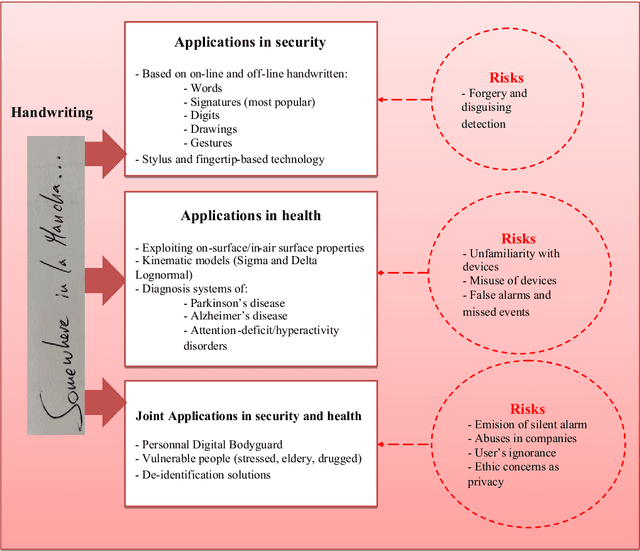

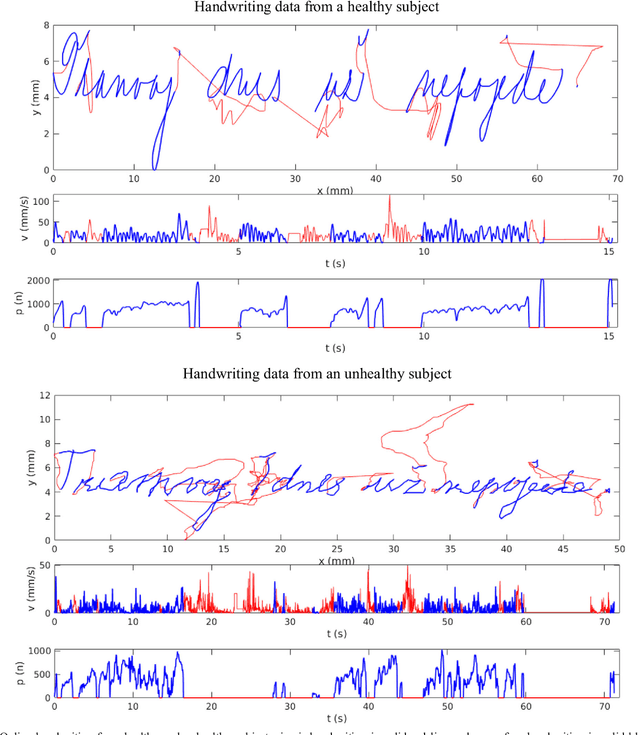
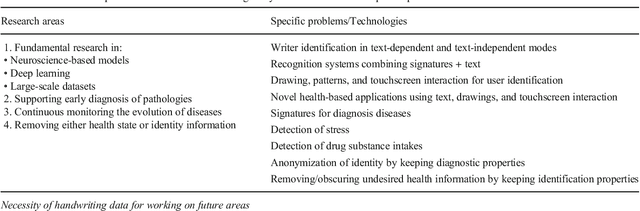
Background- This paper summarizes the state-of-the-art and applications based on online handwritting signals with special emphasis on e-security and e-health fields. Methods- In particular, we focus on the main achievements and challenges that should be addressed by the scientific community, providing a guide document for future research. Conclusions- Among all the points discussed in this article, we remark the importance of considering security, health, and metadata from a joint perspective. This is especially critical due to the double use possibilities of these behavioral signals.
* 24 pages
FaceQgen: Semi-Supervised Deep Learning for Face Image Quality Assessment
Jan 03, 2022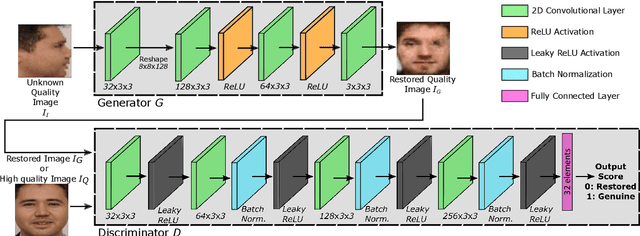
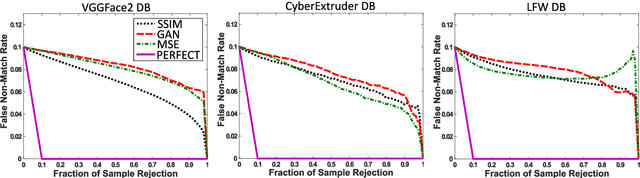
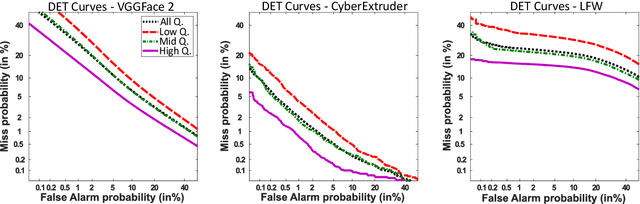
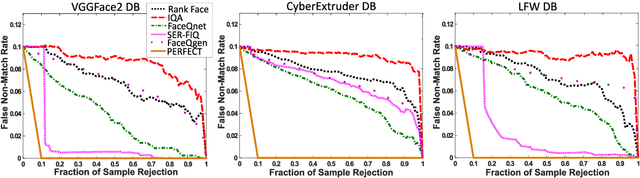
In this paper we develop FaceQgen, a No-Reference Quality Assessment approach for face images based on a Generative Adversarial Network that generates a scalar quality measure related with the face recognition accuracy. FaceQgen does not require labelled quality measures for training. It is trained from scratch using the SCface database. FaceQgen applies image restoration to a face image of unknown quality, transforming it into a canonical high quality image, i.e., frontal pose, homogeneous background, etc. The quality estimation is built as the similarity between the original and the restored images, since low quality images experience bigger changes due to restoration. We compare three different numerical quality measures: a) the MSE between the original and the restored images, b) their SSIM, and c) the output score of the Discriminator of the GAN. The results demonstrate that FaceQgen's quality measures are good estimators of face recognition accuracy. Our experiments include a comparison with other quality assessment methods designed for faces and for general images, in order to position FaceQgen in the state of the art. This comparison shows that, even though FaceQgen does not surpass the best existing face quality assessment methods in terms of face recognition accuracy prediction, it achieves good enough results to demonstrate the potential of semi-supervised learning approaches for quality estimation (in particular, data-driven learning based on a single high quality image per subject), having the capacity to improve its performance in the future with adequate refinement of the model and the significant advantage over competing methods of not needing quality labels for its development. This makes FaceQgen flexible and scalable without expensive data curation.
ALEBk: Feasibility Study of Attention Level Estimation via Blink Detection applied to e-Learning
Dec 16, 2021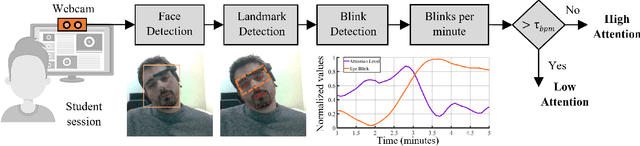
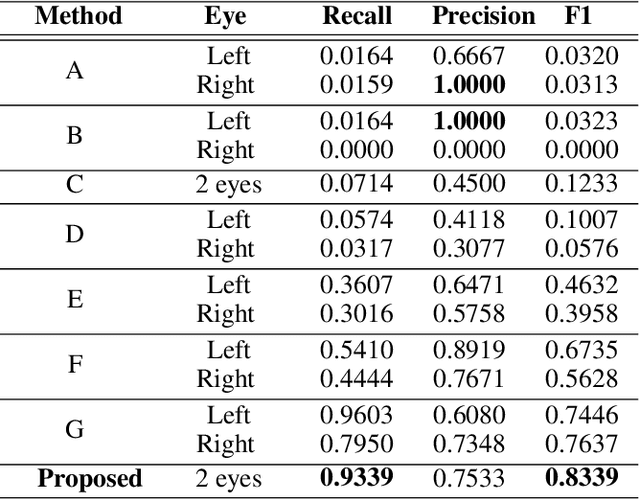
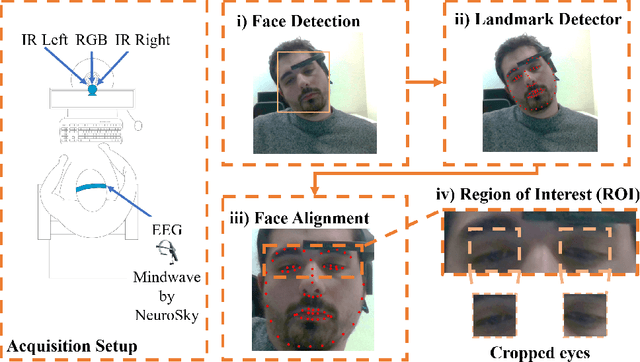
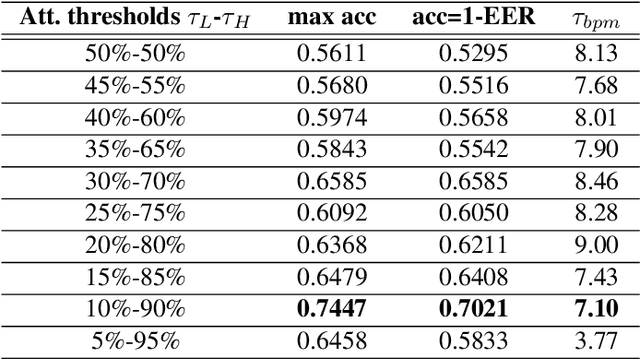
This work presents a feasibility study of remote attention level estimation based on eye blink frequency. We first propose an eye blink detection system based on Convolutional Neural Networks (CNNs), very competitive with respect to related works. Using this detector, we experimentally evaluate the relationship between the eye blink rate and the attention level of students captured during online sessions. The experimental framework is carried out using a public multimodal database for eye blink detection and attention level estimation called mEBAL, which comprises data from 38 students and multiples acquisition sensors, in particular, i) an electroencephalogram (EEG) band which provides the time signals coming from the student's cognitive information, and ii) RGB and NIR cameras to capture the students face gestures. The results achieved suggest an inverse correlation between the eye blink frequency and the attention level. This relation is used in our proposed method called ALEBk for estimating the attention level as the inverse of the eye blink frequency. Our results open a new research line to introduce this technology for attention level estimation on future e-learning platforms, among other applications of this kind of behavioral biometrics based on face analysis.
Introduction to Presentation Attack Detection in Face Biometrics and Recent Advances
Nov 26, 2021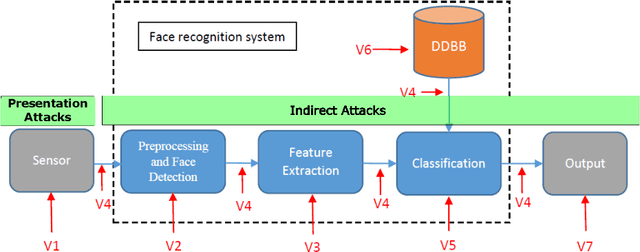


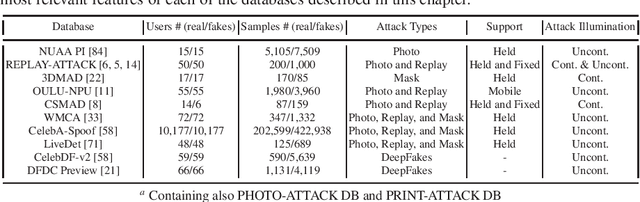
The main scope of this chapter is to serve as an introduction to face presentation attack detection, including key resources and advances in the field in the last few years. The next pages present the different presentation attacks that a face recognition system can confront, in which an attacker presents to the sensor, mainly a camera, a Presentation Attack Instrument (PAI), that is generally a photograph, a video, or a mask, to try to impersonate a genuine user. First, we make an introduction of the current status of face recognition, its level of deployment, and its challenges. In addition, we present the vulnerabilities and the possible attacks that a face recognition system may be exposed to, showing that way the high importance of presentation attack detection methods. We review different types of presentation attack methods, from simpler to more complex ones, and in which cases they could be effective. Then, we summarize the most popular presentation attack detection methods to deal with these attacks. Finally, we introduce public datasets used by the research community for exploring vulnerabilities of face biometrics to presentation attacks and developing effective countermeasures against known PAIs.
OTB-morph: One-Time Biometrics via Morphing applied to Face Templates
Nov 25, 2021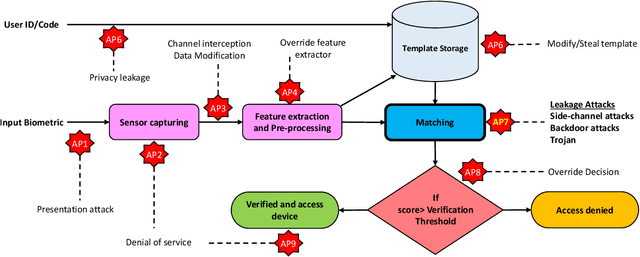

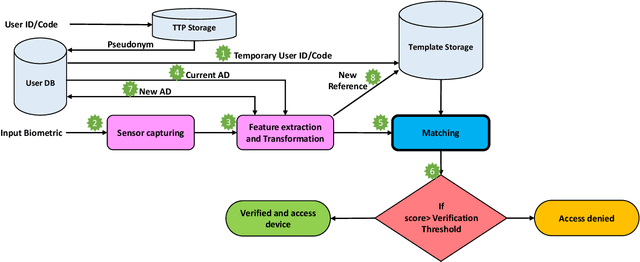
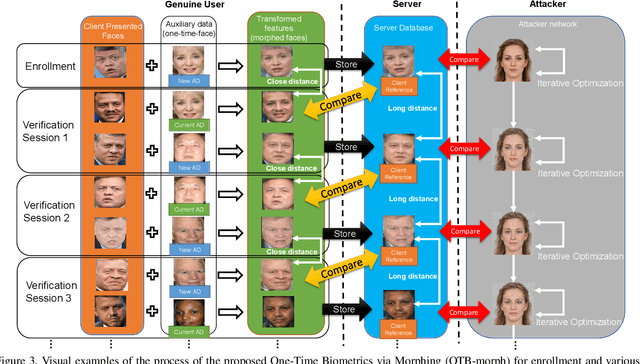
Cancelable biometrics refers to a group of techniques in which the biometric inputs are transformed intentionally using a key before processing or storage. This transformation is repeatable enabling subsequent biometric comparisons. This paper introduces a new scheme for cancelable biometrics aimed at protecting the templates against potential attacks, applicable to any biometric-based recognition system. Our proposed scheme is based on time-varying keys obtained from morphing random biometric information. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.