 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Attempt at Building Parallel Corpora for Machine Translation of Northeast India's Very Low-Resource Languages
Dec 08, 2023



This paper presents the creation of initial bilingual corpora for thirteen very low-resource languages of India, all from Northeast India. It also presents the results of initial translation efforts in these languages. It creates the first-ever parallel corpora for these languages and provides initial benchmark neural machine translation results for these languages. We intend to extend these corpora to include a large number of low-resource Indian languages and integrate the effort with our prior work with African and American-Indian languages to create corpora covering a large number of languages from across the world.
The Less the Merrier? Investigating Language Representation in Multilingual Models
Oct 20, 2023Multilingual Language Models offer a way to incorporate multiple languages in one model and utilize cross-language transfer learning to improve performance for different Natural Language Processing (NLP) tasks. Despite progress in multilingual models, not all languages are supported as well, particularly in low-resource settings. In this work, we investigate the linguistic representation of different languages in multilingual models. We start by asking the question which languages are supported in popular multilingual models and which languages are left behind. Then, for included languages, we look at models' learned representations based on language family and dialect and try to understand how models' learned representations for~(1) seen and~(2) unseen languages vary across different language groups. In addition, we test and analyze performance on downstream tasks such as text generation and Named Entity Recognition. We observe from our experiments that community-centered models -- models that focus on languages of a given family or geographical location and are built by communities who speak them -- perform better at distinguishing between languages in the same family for low-resource languages. Our paper contributes to the literature in understanding multilingual models and their shortcomings and offers insights on potential ways to improve them.
Explaining Math Word Problem Solvers
Jul 24, 2023Automated math word problem solvers based on neural networks have successfully managed to obtain 70-80\% accuracy in solving arithmetic word problems. However, it has been shown that these solvers may rely on superficial patterns to obtain their equations. In order to determine what information math word problem solvers use to generate solutions, we remove parts of the input and measure the model's performance on the perturbed dataset. Our results show that the model is not sensitive to the removal of many words from the input and can still manage to find a correct answer when given a nonsense question. This indicates that automatic solvers do not follow the semantic logic of math word problems, and may be overfitting to the presence of specific words.
Training-free Neural Architecture Search for RNNs and Transformers
Jun 01, 2023Neural architecture search (NAS) has allowed for the automatic creation of new and effective neural network architectures, offering an alternative to the laborious process of manually designing complex architectures. However, traditional NAS algorithms are slow and require immense amounts of computing power. Recent research has investigated training-free NAS metrics for image classification architectures, drastically speeding up search algorithms. In this paper, we investigate training-free NAS metrics for recurrent neural network (RNN) and BERT-based transformer architectures, targeted towards language modeling tasks. First, we develop a new training-free metric, named hidden covariance, that predicts the trained performance of an RNN architecture and significantly outperforms existing training-free metrics. We experimentally evaluate the effectiveness of the hidden covariance metric on the NAS-Bench-NLP benchmark. Second, we find that the current search space paradigm for transformer architectures is not optimized for training-free neural architecture search. Instead, a simple qualitative analysis can effectively shrink the search space to the best performing architectures. This conclusion is based on our investigation of existing training-free metrics and new metrics developed from recent transformer pruning literature, evaluated on our own benchmark of trained BERT architectures. Ultimately, our analysis shows that the architecture search space and the training-free metric must be developed together in order to achieve effective results.
Enhancing Translation for Indigenous Languages: Experiments with Multilingual Models
May 27, 2023


This paper describes CIC NLP's submission to the AmericasNLP 2023 Shared Task on machine translation systems for indigenous languages of the Americas. We present the system descriptions for three methods. We used two multilingual models, namely M2M-100 and mBART50, and one bilingual (one-to-one) -- Helsinki NLP Spanish-English translation model, and experimented with different transfer learning setups. We experimented with 11 languages from America and report the setups we used as well as the results we achieved. Overall, the mBART setup was able to improve upon the baseline for three out of the eleven languages.
Abstractive Text Summarization Using the BRIO Training Paradigm
May 23, 2023



Summary sentences produced by abstractive summarization models may be coherent and comprehensive, but they lack control and rely heavily on reference summaries. The BRIO training paradigm assumes a non-deterministic distribution to reduce the model's dependence on reference summaries, and improve model performance during inference. This paper presents a straightforward but effective technique to improve abstractive summaries by fine-tuning pre-trained language models, and training them with the BRIO paradigm. We build a text summarization dataset for Vietnamese, called VieSum. We perform experiments with abstractive summarization models trained with the BRIO paradigm on the CNNDM and the VieSum datasets. The results show that the models, trained on basic hardware, outperform all existing abstractive summarization models, especially for Vietnamese.
* 6 pages, Findings of the Association for Computational Linguistics: ACL 2023
Spatiotemporal Transformer for Stock Movement Prediction
May 05, 2023



Financial markets are an intriguing place that offer investors the potential to gain large profits if timed correctly. Unfortunately, the dynamic, non-linear nature of financial markets makes it extremely hard to predict future price movements. Within the US stock exchange, there are a countless number of factors that play a role in the price of a company's stock, including but not limited to financial statements, social and news sentiment, overall market sentiment, political happenings and trading psychology. Correlating these factors is virtually impossible for a human. Therefore, we propose STST, a novel approach using a Spatiotemporal Transformer-LSTM model for stock movement prediction. Our model obtains accuracies of 63.707 and 56.879 percent against the ACL18 and KDD17 datasets, respectively. In addition, our model was used in simulation to determine its real-life applicability. It obtained a minimum of 10.41% higher profit than the S&P500 stock index, with a minimum annualized return of 31.24%.
Utilizing Priming to Identify Optimal Class Ordering to Alleviate Catastrophic Forgetting
Dec 24, 2022



In order for artificial neural networks to begin accurately mimicking biological ones, they must be able to adapt to new exigencies without forgetting what they have learned from previous training. Lifelong learning approaches to artificial neural networks attempt to strive towards this goal, yet have not progressed far enough to be realistically deployed for natural language processing tasks. The proverbial roadblock of catastrophic forgetting still gate-keeps researchers from an adequate lifelong learning model. While efforts are being made to quell catastrophic forgetting, there is a lack of research that looks into the importance of class ordering when training on new classes for incremental learning. This is surprising as the ordering of "classes" that humans learn is heavily monitored and incredibly important. While heuristics to develop an ideal class order have been researched, this paper examines class ordering as it relates to priming as a scheme for incremental class learning. By examining the connections between various methods of priming found in humans and how those are mimicked yet remain unexplained in life-long machine learning, this paper provides a better understanding of the similarities between our biological systems and the synthetic systems while simultaneously improving current practices to combat catastrophic forgetting. Through the merging of psychological priming practices with class ordering, this paper is able to identify a generalizable method for class ordering in NLP incremental learning tasks that consistently outperforms random class ordering.
CAMeMBERT: Cascading Assistant-Mediated Multilingual BERT
Dec 22, 2022Large language models having hundreds of millions, and even billions, of parameters have performed extremely well on a variety of natural language processing (NLP) tasks. Their widespread use and adoption, however, is hindered by the lack of availability and portability of sufficiently large computational resources. This paper proposes a knowledge distillation (KD) technique building on the work of LightMBERT, a student model of multilingual BERT (mBERT). By repeatedly distilling mBERT through increasingly compressed toplayer distilled teacher assistant networks, CAMeMBERT aims to improve upon the time and space complexities of mBERT while keeping loss of accuracy beneath an acceptable threshold. At present, CAMeMBERT has an average accuracy of around 60.1%, which is subject to change after future improvements to the hyperparameters used in fine-tuning.
Facial Expression Recognition and Image Description Generation in Vietnamese
Aug 12, 2022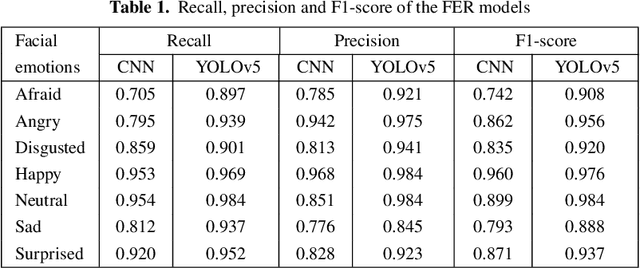
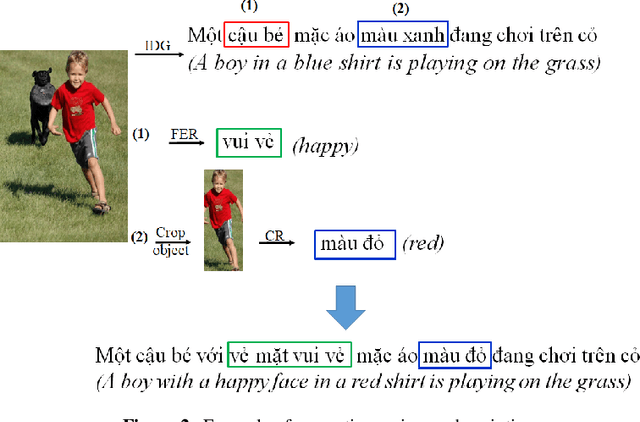

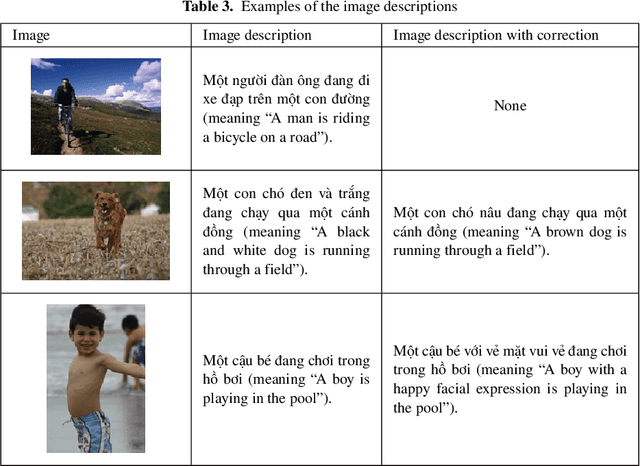
This paper discusses a facial expression recognition model and a description generation model to build descriptive sentences for images and facial expressions of people in images. Our study shows that YOLOv5 achieves better results than a traditional CNN for all emotions on the KDEF dataset. In particular, the accuracies of the CNN and YOLOv5 models for emotion recognition are 0.853 and 0.938, respectively. A model for generating descriptions for images based on a merged architecture is proposed using VGG16 with the descriptions encoded over an LSTM model. YOLOv5 is also used to recognize dominant colors of objects in the images and correct the color words in the descriptions generated if it is necessary. If the description contains words referring to a person, we recognize the emotion of the person in the image. Finally, we combine the results of all models to create sentences that describe the visual content and the human emotions in the images. Experimental results on the Flickr8k dataset in Vietnamese achieve BLEU-1, BLEU-2, BLEU-3, BLEU-4 scores of 0.628; 0.425; 0.280; and 0.174, respectively.
* 7 pages