 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Study of Compressive Cross-Language Text Summarization
Oct 24, 2018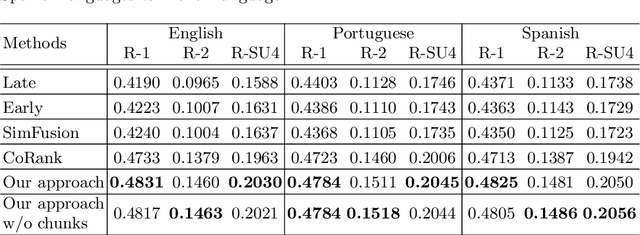
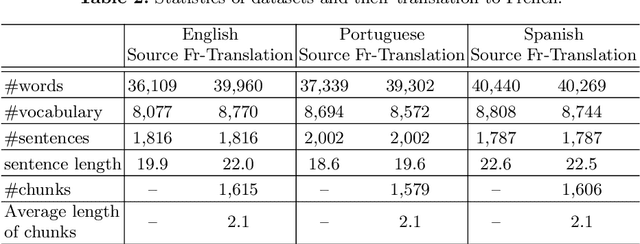
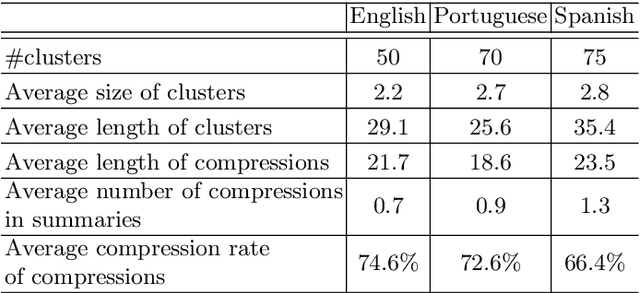
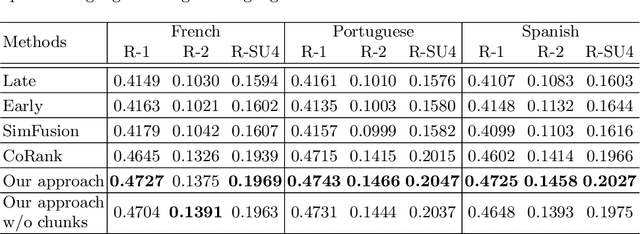
Cross-Language Text Summarization (CLTS) generates summaries in a language different from the language of the source documents. Recent methods use information from both languages to generate summaries with the most informative sentences. However, these methods have performance that can vary according to languages, which can reduce the quality of summaries. In this paper, we propose a compressive framework to generate cross-language summaries. In order to analyze performance and especially stability, we tested our system and extractive baselines on a dataset available in four languages (English, French, Portuguese, and Spanish) to generate English and French summaries. An automatic evaluation showed that our method outperformed extractive state-of-art CLTS methods with better and more stable ROUGE scores for all languages.
Étude de l'informativité des transcriptions : une approche basée sur le résumé automatique
Sep 04, 2018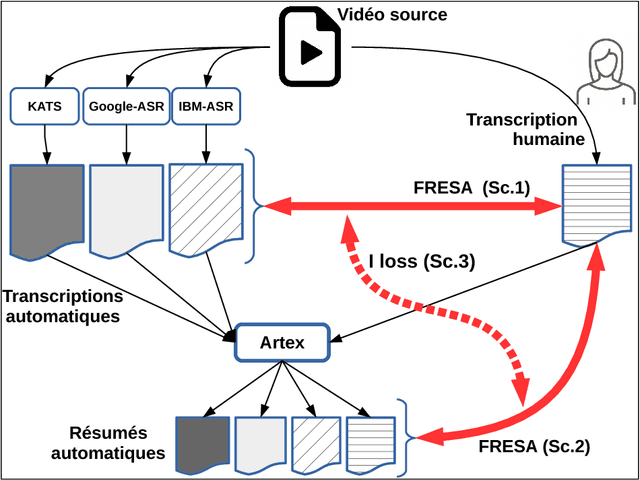
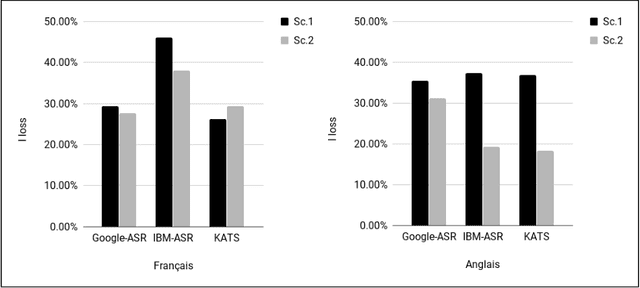
In this paper we propose a new approach to evaluate the informativeness of transcriptions coming from Automatic Speech Recognition systems. This approach, based in the notion of informativeness, is focused on the framework of Automatic Text Summarization performed over these transcriptions. At a first glance we estimate the informative content of the various automatic transcriptions, then we explore the capacity of Automatic Text Summarization to overcome the informative loss. To do this we use an automatic summary evaluation protocol without reference (based on the informative content), which computes the divergence between probability distributions of different textual representations: manual and automatic transcriptions and their summaries. After a set of evaluations this analysis allowed us to judge both the quality of the transcriptions in terms of informativeness and to assess the ability of automatic text summarization to compensate the problems raised during the transcription phase.
WiSeBE: Window-based Sentence Boundary Evaluation
Aug 27, 2018
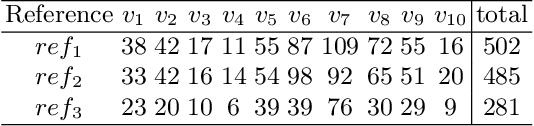

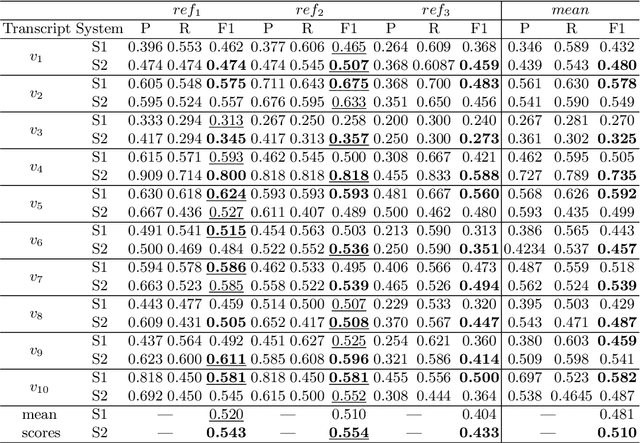
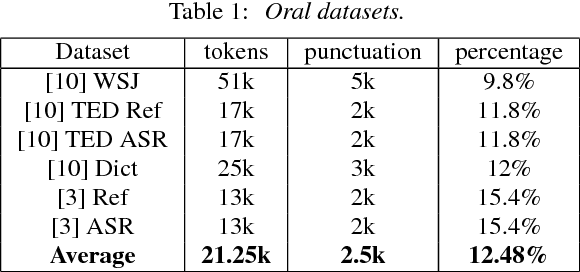
Sentence Boundary Detection (SBD) has been a major research topic since Automatic Speech Recognition transcripts have been used for further Natural Language Processing tasks like Part of Speech Tagging, Question Answering or Automatic Summarization. But what about evaluation? Do standard evaluation metrics like precision, recall, F-score or classification error; and more important, evaluating an automatic system against a unique reference is enough to conclude how well a SBD system is performing given the final application of the transcript? In this paper we propose Window-based Sentence Boundary Evaluation (WiSeBE), a semi-supervised metric for evaluating Sentence Boundary Detection systems based on multi-reference (dis)agreement. We evaluate and compare the performance of different SBD systems over a set of Youtube transcripts using WiSeBE and standard metrics. This double evaluation gives an understanding of how WiSeBE is a more reliable metric for the SBD task.
Sentence Boundary Detection for French with Subword-Level Information Vectors and Convolutional Neural Networks
Feb 13, 2018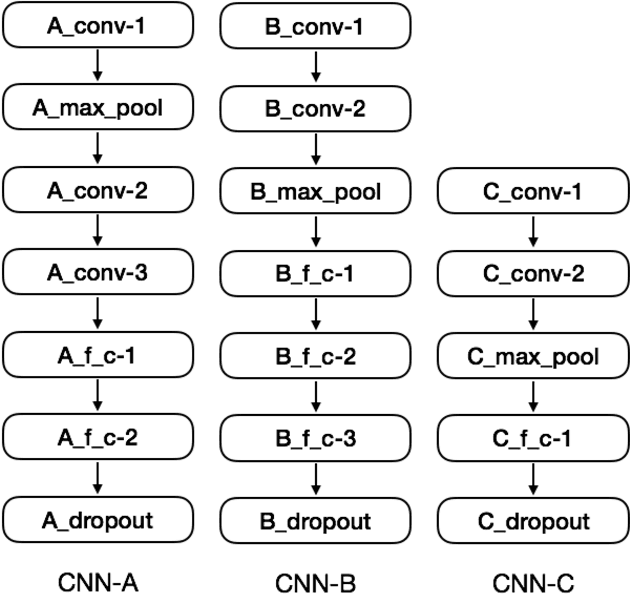
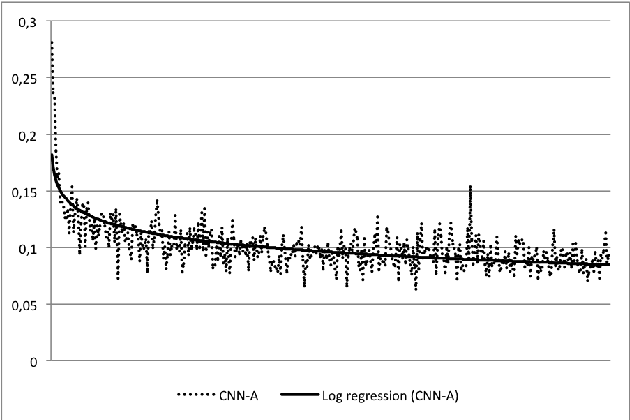
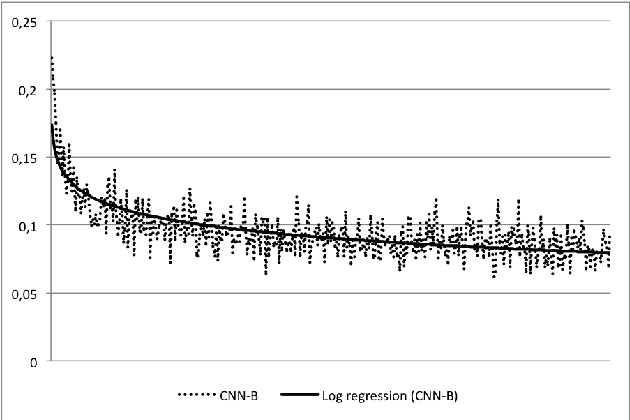
In this work we tackle the problem of sentence boundary detection applied to French as a binary classification task ("sentence boundary" or "not sentence boundary"). We combine convolutional neural networks with subword-level information vectors, which are word embedding representations learned from Wikipedia that take advantage of the words morphology; so each word is represented as a bag of their character n-grams. We decide to use a big written dataset (French Gigaword) instead of standard size transcriptions to train and evaluate the proposed architectures with the intention of using the trained models in posterior real life ASR transcriptions. Three different architectures are tested showing similar results; general accuracy for all models overpasses 0.96. All three models have good F1 scores reaching values over 0.97 regarding the "not sentence boundary" class. However, the "sentence boundary" class reflects lower scores decreasing the F1 metric to 0.778 for one of the models. Using subword-level information vectors seem to be very effective leading to conclude that the morphology of words encoded in the embeddings representations behave like pixels in an image making feasible the use of convolutional neural network architectures.
Unsupervised Sentence Representations as Word Information Series: Revisiting TF--IDF
Oct 20, 2017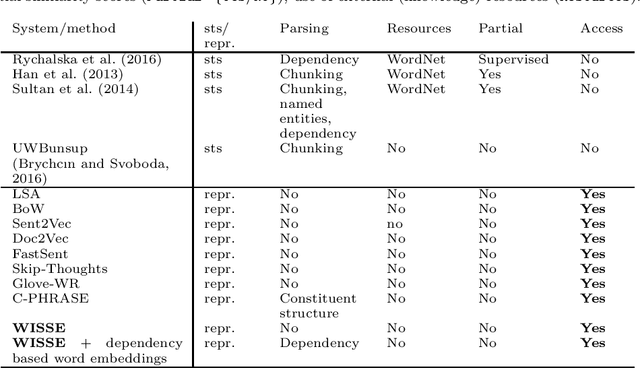
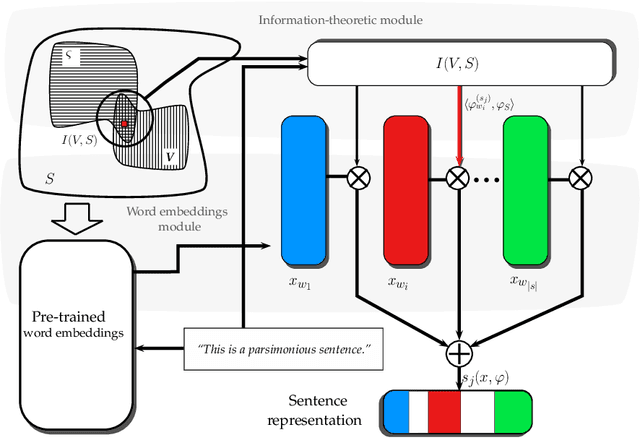
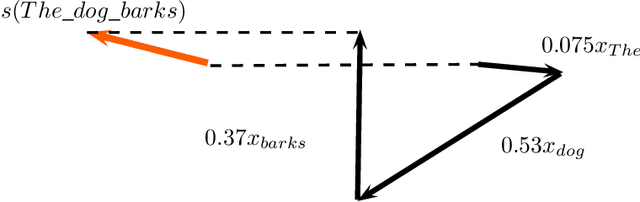
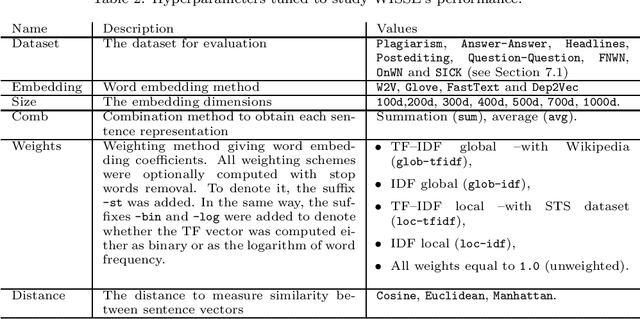
Sentence representation at the semantic level is a challenging task for Natural Language Processing and Artificial Intelligence. Despite the advances in word embeddings (i.e. word vector representations), capturing sentence meaning is an open question due to complexities of semantic interactions among words. In this paper, we present an embedding method, which is aimed at learning unsupervised sentence representations from unlabeled text. We propose an unsupervised method that models a sentence as a weighted series of word embeddings. The weights of the word embeddings are fitted by using Shannon's word entropies provided by the Term Frequency--Inverse Document Frequency (TF--IDF) transform. The hyperparameters of the model can be selected according to the properties of data (e.g. sentence length and textual gender). Hyperparameter selection involves word embedding methods and dimensionalities, as well as weighting schemata. Our method offers advantages over existing methods: identifiable modules, short-term training, online inference of (unseen) sentence representations, as well as independence from domain, external knowledge and language resources. Results showed that our model outperformed the state of the art in well-known Semantic Textual Similarity (STS) benchmarks. Moreover, our model reached state-of-the-art performance when compared to supervised and knowledge-based STS systems.
Automatic Text Summarization Approaches to Speed up Topic Model Learning Process
Mar 20, 2017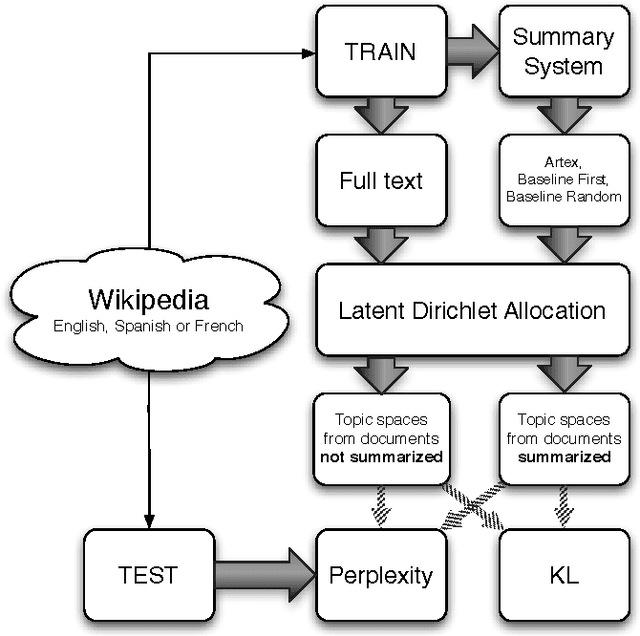
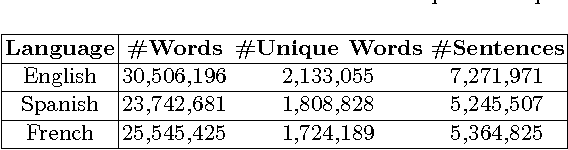
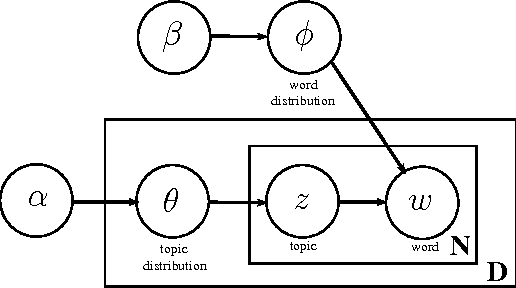
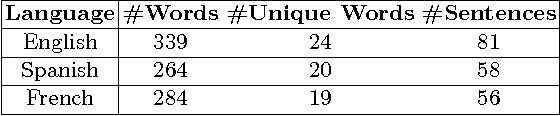
The number of documents available into Internet moves each day up. For this reason, processing this amount of information effectively and expressibly becomes a major concern for companies and scientists. Methods that represent a textual document by a topic representation are widely used in Information Retrieval (IR) to process big data such as Wikipedia articles. One of the main difficulty in using topic model on huge data collection is related to the material resources (CPU time and memory) required for model estimate. To deal with this issue, we propose to build topic spaces from summarized documents. In this paper, we present a study of topic space representation in the context of big data. The topic space representation behavior is analyzed on different languages. Experiments show that topic spaces estimated from text summaries are as relevant as those estimated from the complete documents. The real advantage of such an approach is the processing time gain: we showed that the processing time can be drastically reduced using summarized documents (more than 60\% in general). This study finally points out the differences between thematic representations of documents depending on the targeted languages such as English or latin languages.
* 16 pages, 4 tables, 8 figures
Métodos de Otimização Combinatória Aplicados ao Problema de Compressão MultiFrases
Mar 19, 2017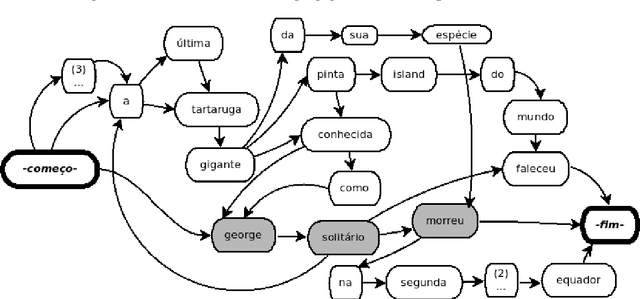
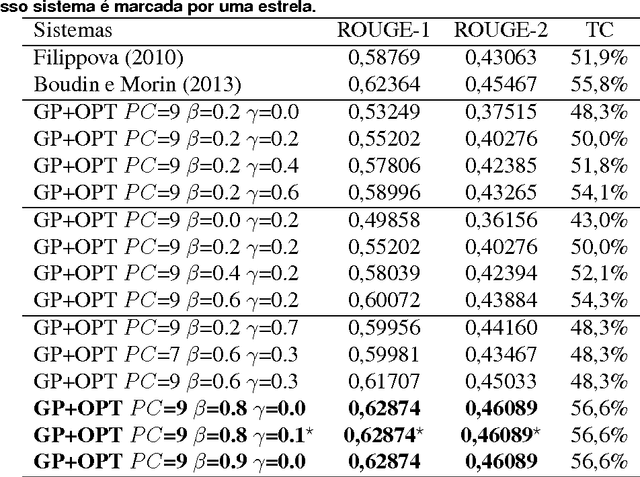


The Internet has led to a dramatic increase in the amount of available information. In this context, reading and understanding this flow of information have become costly tasks. In the last years, to assist people to understand textual data, various Natural Language Processing (NLP) applications based on Combinatorial Optimization have been devised. However, for Multi-Sentences Compression (MSC), method which reduces the sentence length without removing core information, the insertion of optimization methods requires further study to improve the performance of MSC. This article describes a method for MSC using Combinatorial Optimization and Graph Theory to generate more informative sentences while maintaining their grammaticality. An experiment led on a corpus of 40 clusters of sentences shows that our system has achieved a very good quality and is better than the state-of-the-art.
Extending Automatic Discourse Segmentation for Texts in Spanish to Catalan
Mar 11, 2017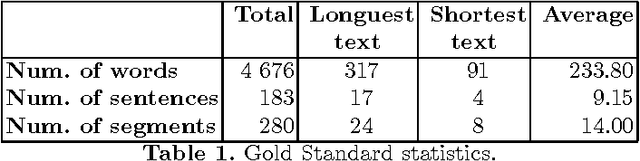

At present, automatic discourse analysis is a relevant research topic in the field of NLP. However, discourse is one of the phenomena most difficult to process. Although discourse parsers have been already developed for several languages, this tool does not exist for Catalan. In order to implement this kind of parser, the first step is to develop a discourse segmenter. In this article we present the first discourse segmenter for texts in Catalan. This segmenter is based on Rhetorical Structure Theory (RST) for Spanish, and uses lexical and syntactic information to translate rules valid for Spanish into rules for Catalan. We have evaluated the system by using a gold standard corpus including manually segmented texts and results are promising.
A German Corpus for Text Similarity Detection Tasks
Mar 11, 2017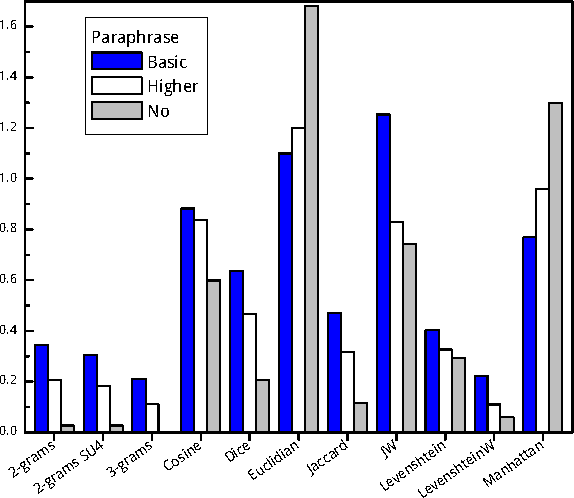
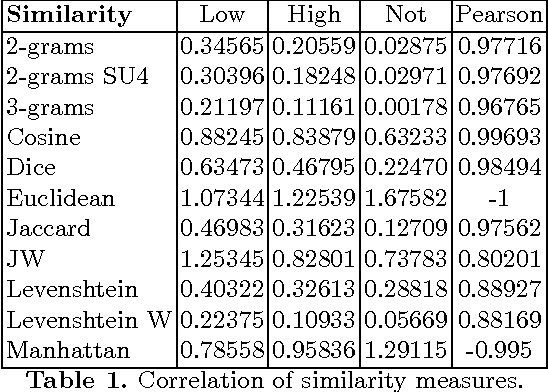
Text similarity detection aims at measuring the degree of similarity between a pair of texts. Corpora available for text similarity detection are designed to evaluate the algorithms to assess the paraphrase level among documents. In this paper we present a textual German corpus for similarity detection. The purpose of this corpus is to automatically assess the similarity between a pair of texts and to evaluate different similarity measures, both for whole documents or for individual sentences. Therefore we have calculated several simple measures on our corpus based on a library of similarity functions.
* 1 figure; 13 pages
Algorithmes de classification et d'optimisation: participation du LIA/ADOC á DEFT'14
Feb 21, 2017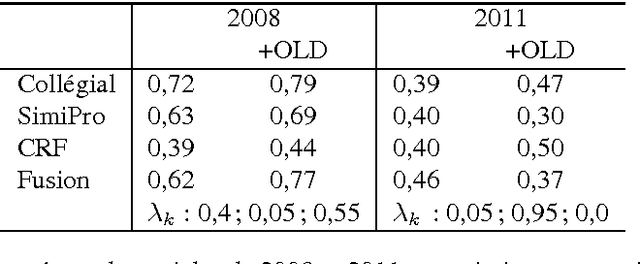

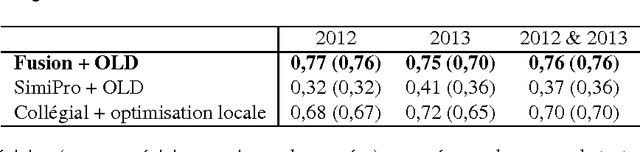
This year, the DEFT campaign (D\'efi Fouilles de Textes) incorporates a task which aims at identifying the session in which articles of previous TALN conferences were presented. We describe the three statistical systems developed at LIA/ADOC for this task. A fusion of these systems enables us to obtain interesting results (micro-precision score of 0.76 measured on the test corpus)