 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Large Language Models as Multilingual Crowdworkers: Synthesizing Open-Domain Dialogues in Several Languages With No Examples in Targets and No Machine Translation
Mar 05, 2025



The prevailing paradigm in the domain of Open-Domain Dialogue agents predominantly focuses on the English language, encompassing both models and datasets. Furthermore, the financial and temporal investments required for crowdsourcing such datasets for finetuning are substantial, particularly when multiple languages are involved. Fortunately, advancements in Large Language Models (LLMs) have unveiled a plethora of possibilities across diverse tasks. Specifically, instruction-tuning has enabled LLMs to execute tasks based on natural language instructions, occasionally surpassing the performance of human crowdworkers. Additionally, these models possess the capability to function in various languages within a single thread. Consequently, to generate new samples in different languages, we propose leveraging these capabilities to replicate the data collection process. We introduce a pipeline for generating Open-Domain Dialogue data in multiple Target Languages using LLMs, with demonstrations provided in a unique Source Language. By eschewing explicit Machine Translation in this approach, we enhance the adherence to language-specific nuances. We apply this methodology to the PersonaChat dataset. To enhance the openness of generated dialogues and mimic real life scenarii, we added the notion of speech events corresponding to the type of conversation the speakers are involved in and also that of common ground which represents the premises of a conversation.
FlowAct: A Proactive Multimodal Human-robot Interaction System with Continuous Flow of Perception and Modular Action Sub-systems
Aug 28, 2024The evolution of autonomous systems in the context of human-robot interaction systems necessitates a synergy between the continuous perception of the environment and the potential actions to navigate or interact within it. We present Flowact, a proactive multimodal human-robot interaction architecture, working as an asynchronous endless loop of robot sensors into actuators and organized by two controllers, the Environment State Tracking (EST) and the Action Planner. The EST continuously collects and publishes a representation of the operative environment, ensuring a steady flow of perceptual data. This persistent perceptual flow is pivotal for our advanced Action Planner which orchestrates a collection of modular action subsystems, such as movement and speaking modules, governing their initiation or cessation based on the evolving environmental narrative. The EST employs a fusion of diverse sensory modalities to build a rich, real-time representation of the environment that is distributed to the Action Planner. This planner uses a decision-making framework to dynamically coordinate action modules, allowing them to respond proactively and coherently to changes in the environment. Through a series of real-world experiments, we exhibit the efficacy of the system in maintaining a continuous perception-action loop, substantially enhancing the responsiveness and adaptability of autonomous pro-active agents. The modular architecture of the action subsystems facilitates easy extensibility and adaptability to a broad spectrum of tasks and scenarios.
Language Portability Strategies for Open-domain Dialogue with Pre-trained Language Models from High to Low Resource Languages
Jul 01, 2024In this paper we propose a study of linguistic portability strategies of large pre-trained language models (PLMs) used for open-domain dialogue systems in a high-resource language for this task. In particular the target low-resource language (L_T) will be simulated with French, as it lacks of task-specific resources and allows our human evaluation, when the source language (L_S) is English. For obvious reasons, recent works using such models for open-domain dialogue are mostly developed in English. Yet building specific PLMs for each possible target language supposes collecting new datasets and is costly. For this reason, trying to leverage all existing resources (PLMs and data) in both L_S and L_T , we wish to assess the performance achievable in L_T with different approaches. The first two approaches evaluate the usage of Neural Machine Translation (NMT) at different levels: TrainOnTarget where a L_S dataset is translated before fine-tuning in L_T and TestOnSource where a L_S model is coupled with NMT modules during inference. Then, the advent of BLOOM [2], the world first open-access multilingual large PLM, allow researchers to develop new approaches aiming to leverage not only the model's full accessibility but also its multilingualism and translation abilities. In this context the task is learned in L_S first and adapted to L_T using the MAD-X Adapter architecture [16]. In the two sets of experiments models are evaluated in spoken dialogue conditions with human and the strategies can be compared in terms of perceived interaction quality.
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Jun 26, 2024



Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
A dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Jun 17, 2024Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
Semantic enrichment towards efficient speech representations
Jul 03, 2023Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
Findings from Experiments of On-line Joint Reinforcement Learning of Semantic Parser and Dialogue Manager with real Users
Oct 25, 2021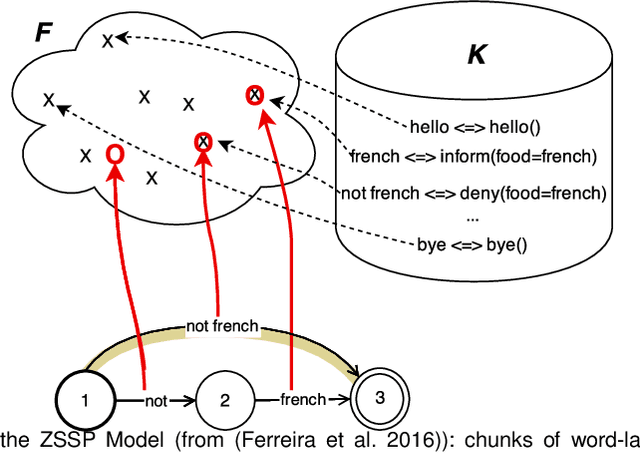
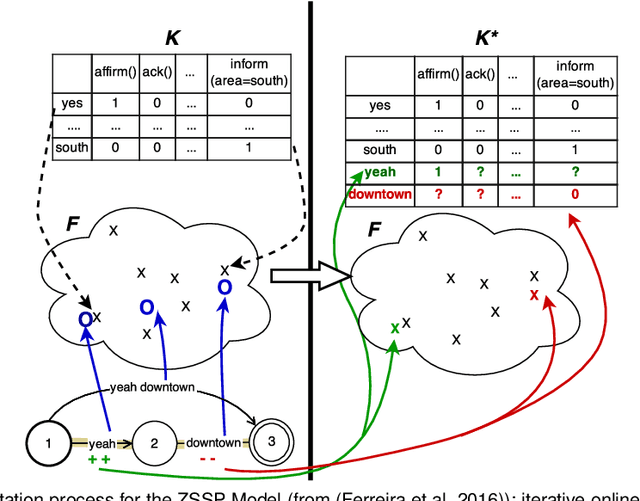

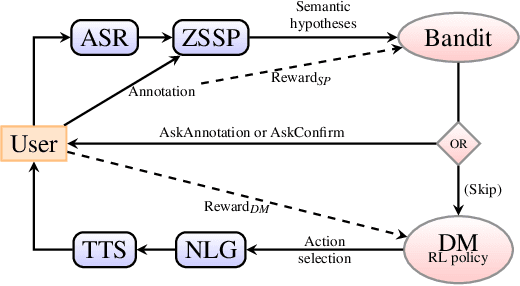
Design of dialogue systems has witnessed many advances lately, yet acquiring huge set of data remains an hindrance to their fast development for a new task or language. Besides, training interactive systems with batch data is not satisfactory. On-line learning is pursued in this paper as a convenient way to alleviate these difficulties. After the system modules are initiated, a single process handles data collection, annotation and use in training algorithms. A new challenge is to control the cost of the on-line learning borne by the user. Our work focuses on learning the semantic parsing and dialogue management modules (speech recognition and synthesis offer ready-for-use solutions). In this context we investigate several variants of simultaneous learning which are tested in user trials. In our experiments, with varying merits, they can all achieve good performance with only a few hundreds of training dialogues and overstep a handcrafted system. The analysis of these experiments gives us some insights, discussed in the paper, into the difficulty for the system's trainers to establish a coherent and constant behavioural strategy to enable a fast and good-quality training phase.
Where are we in semantic concept extraction for Spoken Language Understanding?
Jun 24, 2021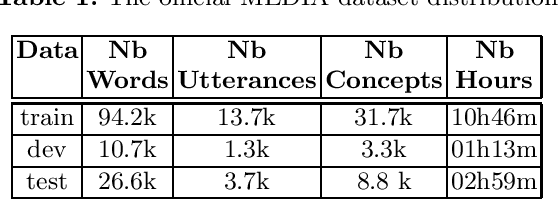


Spoken language understanding (SLU) topic has seen a lot of progress these last three years, with the emergence of end-to-end neural approaches. Spoken language understanding refers to natural language processing tasks related to semantic extraction from speech signal, like named entity recognition from speech or slot filling task in a context of human-machine dialogue. Classically, SLU tasks were processed through a cascade approach that consists in applying, firstly, an automatic speech recognition process, followed by a natural language processing module applied to the automatic transcriptions. These three last years, end-to-end neural approaches, based on deep neural networks, have been proposed in order to directly extract the semantics from speech signal, by using a single neural model. More recent works on self-supervised training with unlabeled data open new perspectives in term of performance for automatic speech recognition and natural language processing. In this paper, we present a brief overview of the recent advances on the French MEDIA benchmark dataset for SLU, with or without the use of additional data. We also present our last results that significantly outperform the current state-of-the-art with a Concept Error Rate (CER) of 11.2%, instead of 13.6% for the last state-of-the-art system presented this year.
A Data Efficient End-To-End Spoken Language Understanding Architecture
Feb 14, 2020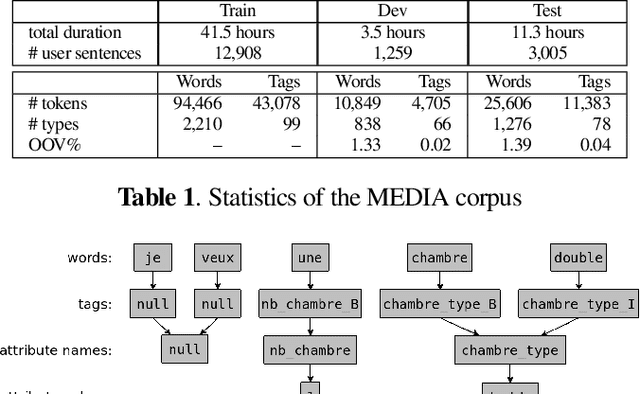
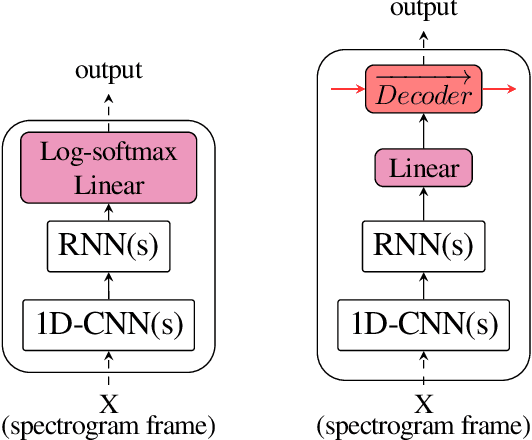
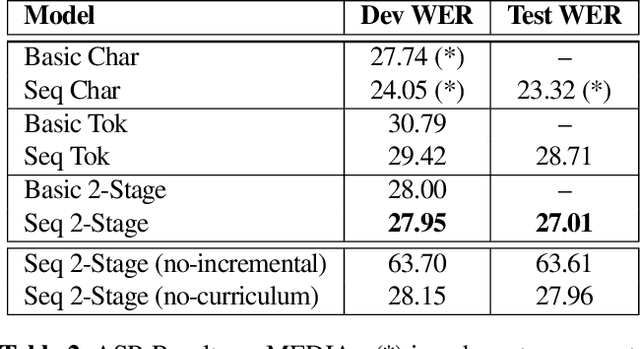
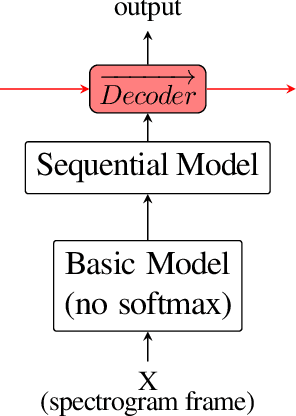
End-to-end architectures have been recently proposed for spoken language understanding (SLU) and semantic parsing. Based on a large amount of data, those models learn jointly acoustic and linguistic-sequential features. Such architectures give very good results in the context of domain, intent and slot detection, their application in a more complex semantic chunking and tagging task is less easy. For that, in many cases, models are combined with an external language model to enhance their performance. In this paper we introduce a data efficient system which is trained end-to-end, with no additional, pre-trained external module. One key feature of our approach is an incremental training procedure where acoustic, language and semantic models are trained sequentially one after the other. The proposed model has a reasonable size and achieves competitive results with respect to state-of-the-art while using a small training dataset. In particular, we reach 24.02% Concept Error Rate (CER) on MEDIA/test while training on MEDIA/train without any additional data.
Joint On-line Learning of a Zero-shot Spoken Semantic Parser and a Reinforcement Learning Dialogue Manager
Oct 01, 2018
Despite many recent advances for the design of dialogue systems, a true bottleneck remains the acquisition of data required to train its components. Unlike many other language processing applications, dialogue systems require interactions with users, therefore it is complex to develop them with pre-recorded data. Building on previous works, on-line learning is pursued here as a most convenient way to address the issue. Data collection, annotation and use in learning algorithms are performed in a single process. The main difficulties are then: to bootstrap an initial basic system, and to control the level of additional cost on the user side. Considering that well-performing solutions can be used directly off the shelf for speech recognition and synthesis, the study is focused on learning the spoken language understanding and dialogue management modules only. Several variants of joint learning are investigated and tested with user trials to confirm that the overall on-line learning can be obtained after only a few hundred training dialogues and can overstep an expert-based system.