 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERTIFAI: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models
May 20, 2019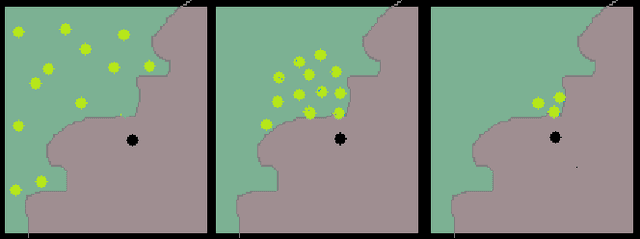

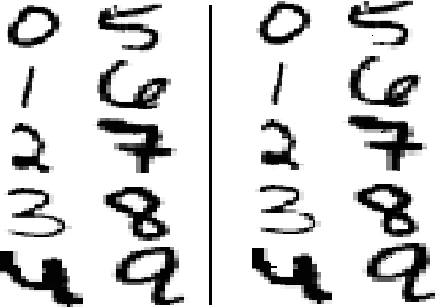
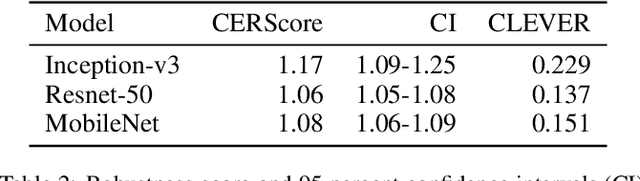
As artificial intelligence plays an increasingly important role in our society, there are ethical and moral obligations for both businesses and researchers to ensure that their machine learning models are designed, deployed, and maintained responsibly. These models need to be rigorously audited for fairness, robustness, transparency, and interpretability. A variety of methods have been developed that focus on these issues in isolation, however, managing these methods in conjunction with model development can be cumbersome and timeconsuming. In this paper, we introduce a unified and model-agnostic approach to address these issues: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models (CERTIFAI). Unlike previous methods in this domain, CERTIFAI is a general tool that can be applied to any black-box model and any type of input data. Given a model and an input instance, CERTIFAI uses a custom genetic algorithm to generate counterfactuals: instances close to the input that change the prediction of the model. We demonstrate how these counterfactuals can be used to examine issues of robustness, interpretability, transparency, and fairness. Additionally, we introduce CERScore, the first black-box model robustness score that performs comparably to methods that have access to model internals.
Explaining Deep Classification of Time-Series Data with Learned Prototypes
Apr 18, 2019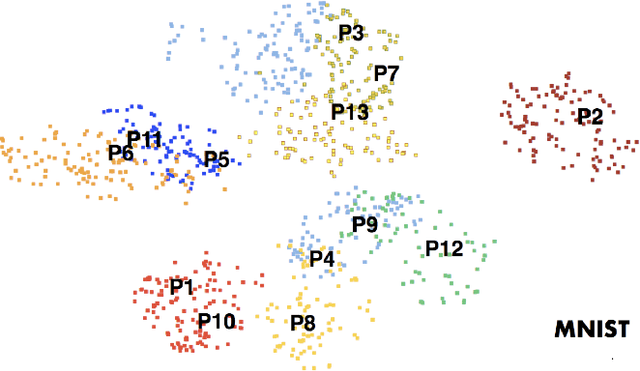

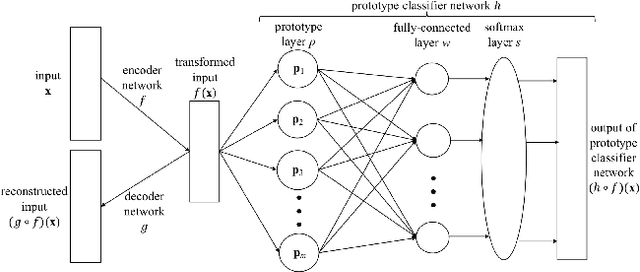
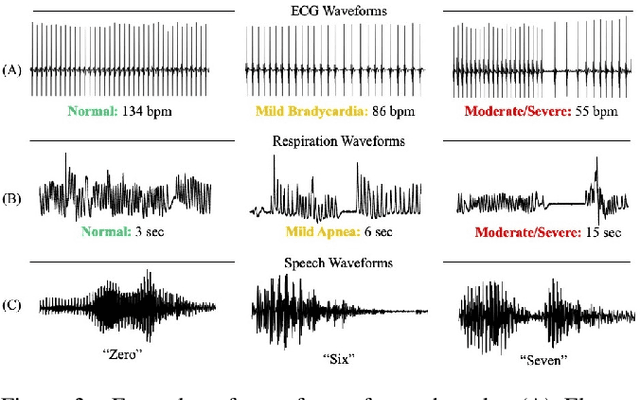
The emergence of deep learning networks raises a need for algorithms to explain their decisions so that users and domain experts can be confident using algorithmic recommendations for high-risk decisions. In this paper we leverage the information-rich latent space induced by such models to learn data representations or prototypes within such networks to elucidate their internal decision-making process. We introduce a novel application of case-based reasoning using prototypes to understand the decisions leading to the classification of time-series data, specifically investigating electrocardiogram (ECG) waveforms for classification of bradycardia, a slowing of heart rate, in infants. We improve upon existing models by explicitly optimizing for increased prototype diversity which in turn improves model accuracy by learning regions of the latent space that highlight features for distinguishing classes. We evaluate the hyperparameter space of our model to show robustness in diversity prototype generation and additionally, explore the resultant latent space of a deep classification network on ECG waveforms via an interactive tool to visualize the learned prototypical waveforms therein. We show that the prototypes are capable of learning real-world features - in our case-study ECG morphology related to bradycardia - as well as features within sub-classes. Our novel work leverages learned prototypical framework on two dimensional time-series data to produce explainable insights during classification tasks.
Interpreting Black Box Predictions using Fisher Kernels
Oct 23, 2018

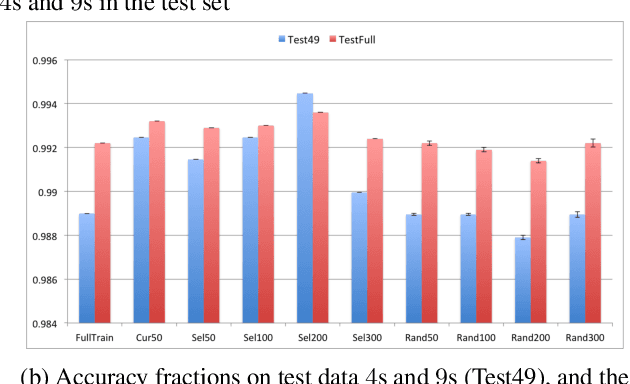
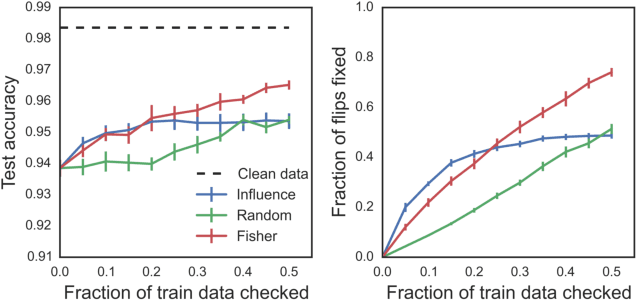
Research in both machine learning and psychology suggests that salient examples can help humans to interpret learning models. To this end, we take a novel look at black box interpretation of test predictions in terms of training examples. Our goal is to ask `which training examples are most responsible for a given set of predictions'? To answer this question, we make use of Fisher kernels as the defining feature embedding of each data point, combined with Sequential Bayesian Quadrature (SBQ) for efficient selection of examples. In contrast to prior work, our method is able to seamlessly handle any sized subset of test predictions in a principled way. We theoretically analyze our approach, providing novel convergence bounds for SBQ over discrete candidate atoms. Our approach recovers the application of influence functions for interpretability as a special case yielding novel insights from this connection. We also present applications of the proposed approach to three use cases: cleaning training data, fixing mislabeled examples and data summarization.
PIVETed-Granite: Computational Phenotypes through Constrained Tensor Factorization
Aug 08, 2018

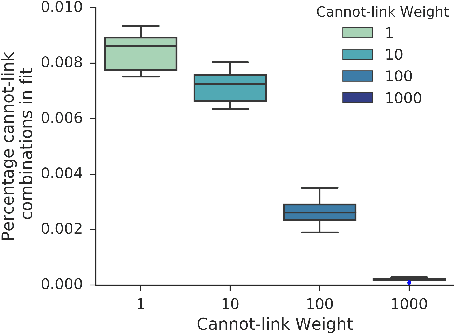

It has been recently shown that sparse, nonnegative tensor factorization of multi-modal electronic health record data is a promising approach to high-throughput computational phenotyping. However, such approaches typically do not leverage available domain knowledge while extracting the phenotypes; hence, some of the suggested phenotypes may not map well to clinical concepts or may be very similar to other suggested phenotypes. To address these issues, we present a novel, automatic approach called PIVETed-Granite that mines existing biomedical literature (PubMed) to obtain cannot-link constraints that are then used as side-information during a tensor-factorization based computational phenotyping process. The resulting improvements are clearly observed in experiments using a large dataset from VUMC to identify phenotypes for hypertensive patients.
xGEMs: Generating Examplars to Explain Black-Box Models
Jun 22, 2018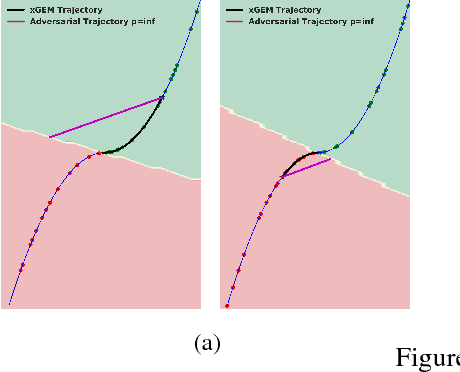
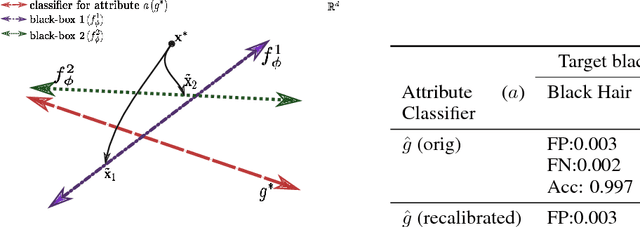

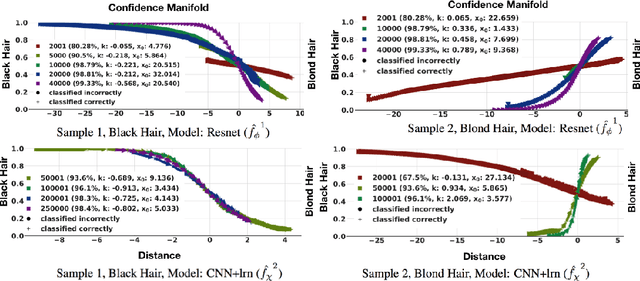
This work proposes xGEMs or manifold guided exemplars, a framework to understand black-box classifier behavior by exploring the landscape of the underlying data manifold as data points cross decision boundaries. To do so, we train an unsupervised implicit generative model -- treated as a proxy to the data manifold. We summarize black-box model behavior quantitatively by perturbing data samples along the manifold. We demonstrate xGEMs' ability to detect and quantify bias in model learning and also for understanding the changes in model behavior as training progresses.
Measurement-wise Occlusion in Multi-object Tracking
May 21, 2018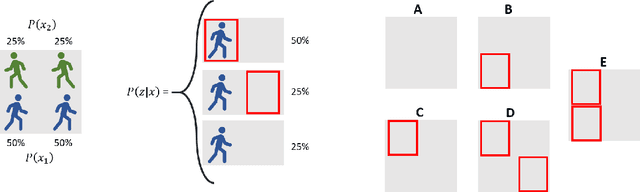
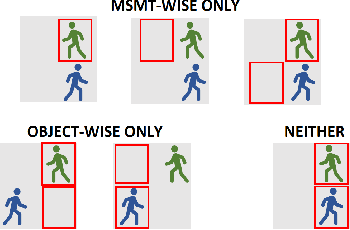
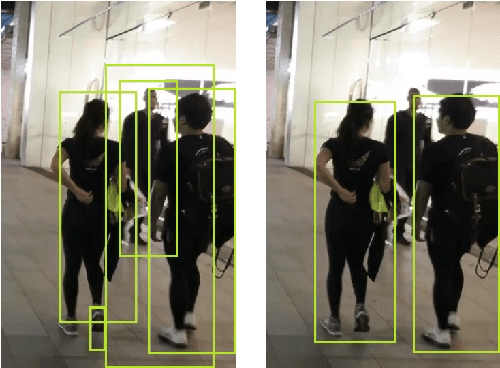

Handling object interaction is a fundamental challenge in practical multi-object tracking, even for simple interactive effects such as one object temporarily occluding another. We formalize the problem of occlusion in tracking with two different abstractions. In object-wise occlusion, objects that are occluded by other objects do not generate measurements. In measurement-wise occlusion, a previously unstudied approach, all objects may generate measurements but some measurements may be occluded by others. While the relative validity of each abstraction depends on the situation and sensor, measurement-wise occlusion fits into probabilistic multi-object tracking algorithms with much looser assumptions on object interaction. Its value is demonstrated by showing that it naturally derives a popular approximation for lidar tracking, and by an example of visual tracking in image space.
Boosting Variational Inference: an Optimization Perspective
Mar 07, 2018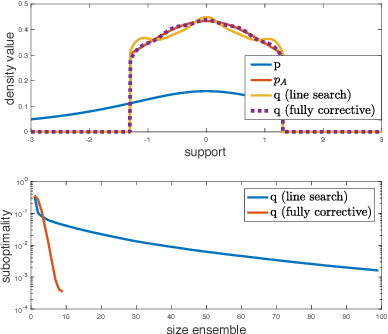
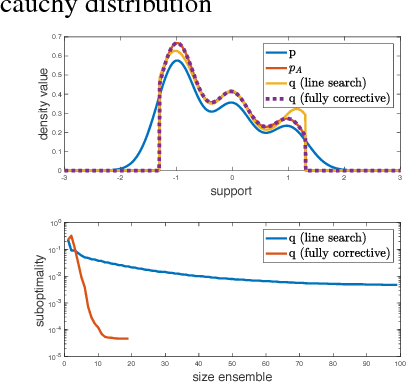
Variational inference is a popular technique to approximate a possibly intractable Bayesian posterior with a more tractable one. Recently, boosting variational inference has been proposed as a new paradigm to approximate the posterior by a mixture of densities by greedily adding components to the mixture. However, as is the case with many other variational inference algorithms, its theoretical properties have not been studied. In the present work, we study the convergence properties of this approach from a modern optimization viewpoint by establishing connections to the classic Frank-Wolfe algorithm. Our analyses yields novel theoretical insights regarding the sufficient conditions for convergence, explicit rates, and algorithmic simplifications. Since a lot of focus in previous works for variational inference has been on tractability, our work is especially important as a much needed attempt to bridge the gap between probabilistic models and their corresponding theoretical properties.
Nonparametric Bayesian Sparse Graph Linear Dynamical Systems
Feb 21, 2018
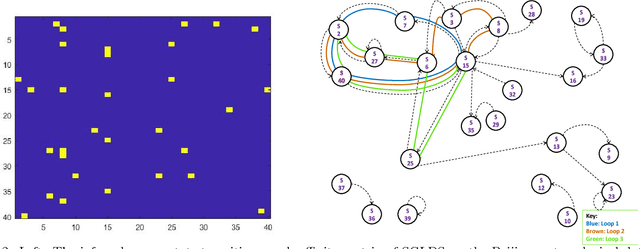
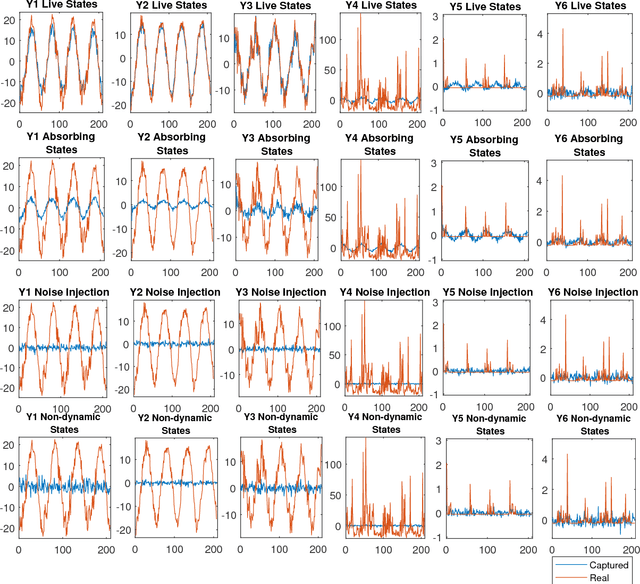
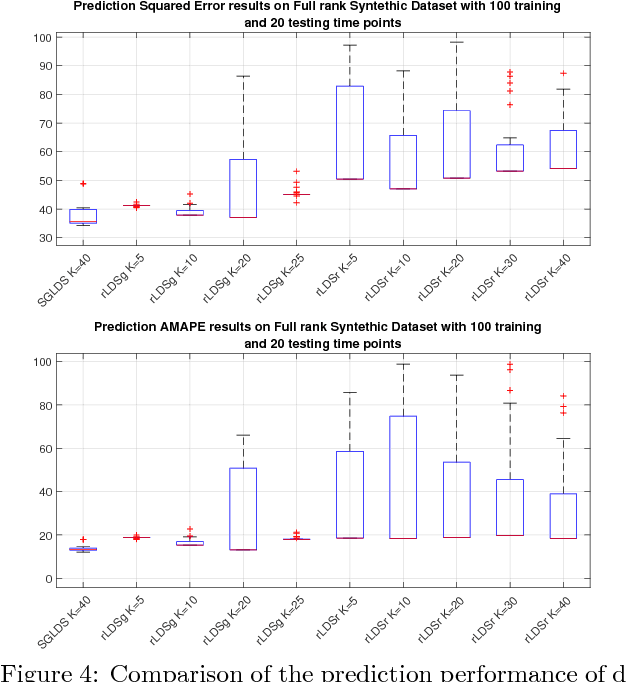
A nonparametric Bayesian sparse graph linear dynamical system (SGLDS) is proposed to model sequentially observed multivariate data. SGLDS uses the Bernoulli-Poisson link together with a gamma process to generate an infinite dimensional sparse random graph to model state transitions. Depending on the sparsity pattern of the corresponding row and column of the graph affinity matrix, a latent state of SGLDS can be categorized as either a non-dynamic state or a dynamic one. A normal-gamma construction is used to shrink the energy captured by the non-dynamic states, while the dynamic states can be further categorized into live, absorbing, or noise-injection states, which capture different types of dynamical components of the underlying time series. The state-of-the-art performance of SGLDS is demonstrated with experiments on both synthetic and real data.
Relaxed Oracles for Semi-Supervised Clustering
Nov 20, 2017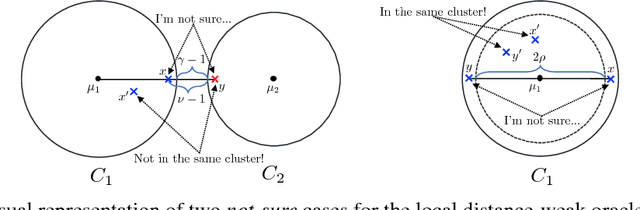
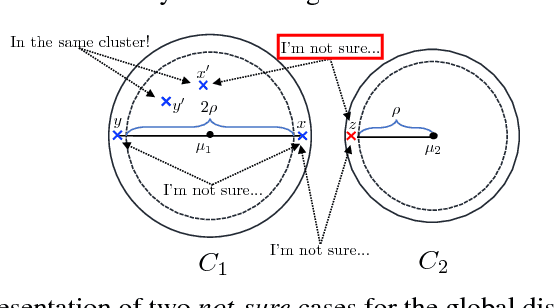
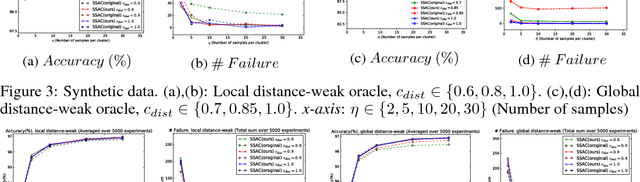
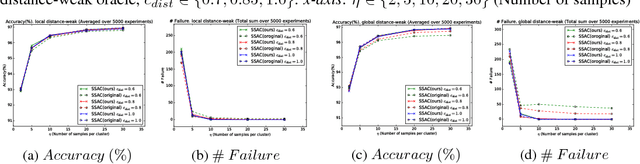
Pairwise "same-cluster" queries are one of the most widely used forms of supervision in semi-supervised clustering. However, it is impractical to ask human oracles to answer every query correctly. In this paper, we study the influence of allowing "not-sure" answers from a weak oracle and propose an effective algorithm to handle such uncertainties in query responses. Two realistic weak oracle models are considered where ambiguity in answering depends on the distance between two points. We show that a small query complexity is adequate for effective clustering with high probability by providing better pairs to the weak oracle. Experimental results on synthetic and real data show the effectiveness of our approach in overcoming supervision uncertainties and yielding high quality clusters.
Semi-Supervised Active Clustering with Weak Oracles
Sep 11, 2017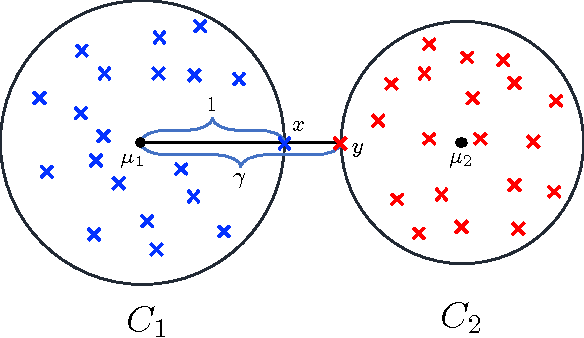

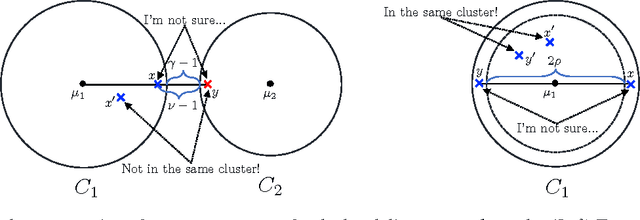

Semi-supervised active clustering (SSAC) utilizes the knowledge of a domain expert to cluster data points by interactively making pairwise "same-cluster" queries. However, it is impractical to ask human oracles to answer every pairwise query. In this paper, we study the influence of allowing "not-sure" answers from a weak oracle and propose algorithms to efficiently handle uncertainties. Different types of model assumptions are analyzed to cover realistic scenarios of oracle abstraction. In the first model, random-weak oracle, an oracle randomly abstains with a certain probability. We also proposed two distance-weak oracle models which simulate the case of getting confused based on the distance between two points in a pairwise query. For each weak oracle model, we show that a small query complexity is adequate for the effective $k$ means clustering with high probability. Sufficient conditions for the guarantee include a $\gamma$-margin property of the data, and an existence of a point close to each cluster center. Furthermore, we provide a sample complexity with a reduced effect of the cluster's margin and only a logarithmic dependency on the data dimension. Our results allow significantly less number of same-cluster queries if the margin of the clusters is tight, i.e. $\gamma \approx 1$. Experimental results on synthetic data show the effective performance of our approach in overcoming uncertainties.