 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardize: Aligning Language Models with Expert-Defined Standards for Content Generation
Feb 19, 2024



Domain experts across engineering, healthcare, and education follow strict standards for producing quality content such as technical manuals, medication instructions, and children's reading materials. However, current works in controllable text generation have yet to explore using these standards as references for control. Towards this end, we introduce Standardize, a retrieval-style in-context learning-based framework to guide large language models to align with expert-defined standards. Focusing on English language standards in the education domain as a use case, we consider the Common European Framework of Reference for Languages (CEFR) and Common Core Standards (CCS) for the task of open-ended content generation. Our findings show that models can gain 40% to 100% increase in precise accuracy for Llama2 and GPT-4, respectively, demonstrating that the use of knowledge artifacts extracted from standards and integrating them in the generation process can effectively guide models to produce better standard-aligned content.
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023



We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
BasahaCorpus: An Expanded Linguistic Resource for Readability Assessment in Central Philippine Languages
Oct 17, 2023Current research on automatic readability assessment (ARA) has focused on improving the performance of models in high-resource languages such as English. In this work, we introduce and release BasahaCorpus as part of an initiative aimed at expanding available corpora and baseline models for readability assessment in lower resource languages in the Philippines. We compiled a corpus of short fictional narratives written in Hiligaynon, Minasbate, Karay-a, and Rinconada -- languages belonging to the Central Philippine family tree subgroup -- to train ARA models using surface-level, syllable-pattern, and n-gram overlap features. We also propose a new hierarchical cross-lingual modeling approach that takes advantage of a language's placement in the family tree to increase the amount of available training data. Our study yields encouraging results that support previous work showcasing the efficacy of cross-lingual models in low-resource settings, as well as similarities in highly informative linguistic features for mutually intelligible languages.
CebuaNER: A New Baseline Cebuano Named Entity Recognition Model
Oct 01, 2023Despite being one of the most linguistically diverse groups of countries, computational linguistics and language processing research in Southeast Asia has struggled to match the level of countries from the Global North. Thus, initiatives such as open-sourcing corpora and the development of baseline models for basic language processing tasks are important stepping stones to encourage the growth of research efforts in the field. To answer this call, we introduce CebuaNER, a new baseline model for named entity recognition (NER) in the Cebuano language. Cebuano is the second most-used native language in the Philippines, with over 20 million speakers. To build the model, we collected and annotated over 4,000 news articles, the largest of any work in the language, retrieved from online local Cebuano platforms to train algorithms such as Conditional Random Field and Bidirectional LSTM. Our findings show promising results as a new baseline model, achieving over 70% performance on precision, recall, and F1 across all entity tags, as well as potential efficacy in a crosslingual setup with Tagalog.
Flesch or Fumble? Evaluating Readability Standard Alignment of Instruction-Tuned Language Models
Sep 11, 2023Readability metrics and standards such as Flesch Kincaid Grade Level (FKGL) and the Common European Framework of Reference for Languages (CEFR) exist to guide teachers and educators to properly assess the complexity of educational materials before administering them for classroom use. In this study, we select a diverse set of open and closed-source instruction-tuned language models and investigate their performances in writing story completions and simplifying narratives$-$tasks that teachers perform$-$using standard-guided prompts controlling text readability. Our extensive findings provide empirical proof of how globally recognized models like ChatGPT may be considered less effective and may require more refined prompts for these generative tasks compared to other open-sourced models such as BLOOMZ and FlanT5$-$which have shown promising results.
Automatic Readability Assessment for Closely Related Languages
May 25, 2023In recent years, the main focus of research on automatic readability assessment (ARA) has shifted towards using expensive deep learning-based methods with the primary goal of increasing models' accuracy. This, however, is rarely applicable for low-resource languages where traditional handcrafted features are still widely used due to the lack of existing NLP tools to extract deeper linguistic representations. In this work, we take a step back from the technical component and focus on how linguistic aspects such as mutual intelligibility or degree of language relatedness can improve ARA in a low-resource setting. We collect short stories written in three languages in the Philippines-Tagalog, Bikol, and Cebuano-to train readability assessment models and explore the interaction of data and features in various cross-lingual setups. Our results show that the inclusion of CrossNGO, a novel specialized feature exploiting n-gram overlap applied to languages with high mutual intelligibility, significantly improves the performance of ARA models compared to the use of off-the-shelf large multilingual language models alone. Consequently, when both linguistic representations are combined, we achieve state-of-the-art results for Tagalog and Cebuano, and baseline scores for ARA in Bikol.
Uniform Complexity for Text Generation
Apr 11, 2022
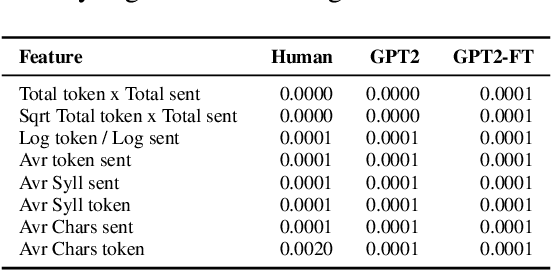
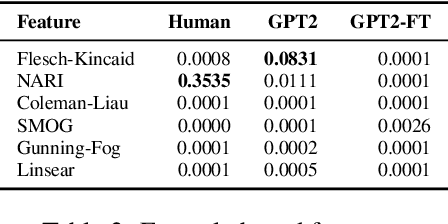
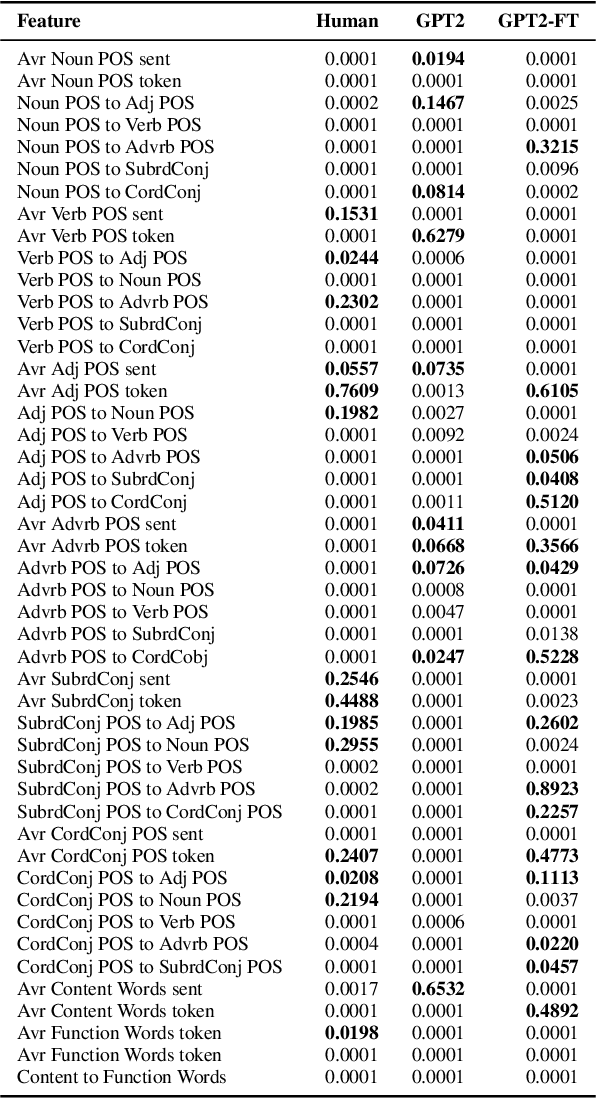
Powerful language models such as GPT-2 have shown promising results in tasks such as narrative generation which can be useful in an educational setup. These models, however, should be consistent with the linguistic properties of triggers used. For example, if the reading level of an input text prompt is appropriate for low-leveled learners (ex. A2 in the CEFR), then the generated continuation should also assume this particular level. Thus, we propose the task of uniform complexity for text generation which serves as a call to make existing language generators uniformly complex with respect to prompts used. Our study surveyed over 160 linguistic properties for evaluating text complexity and found out that both humans and GPT-2 models struggle in preserving the complexity of prompts in a narrative generation setting.
A Baseline Readability Model for Cebuano
Apr 06, 2022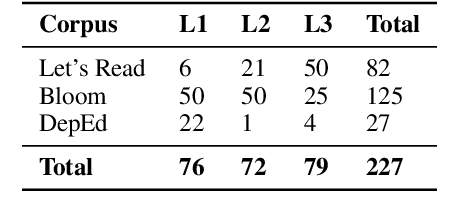
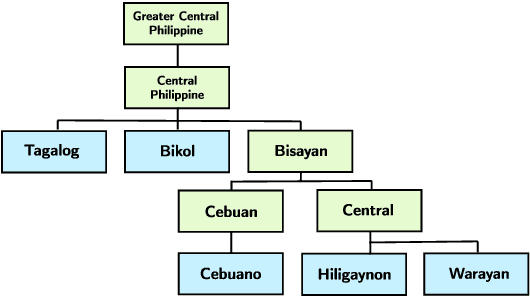
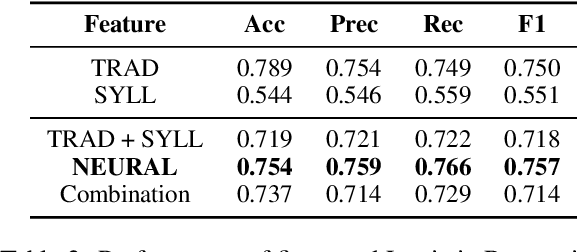
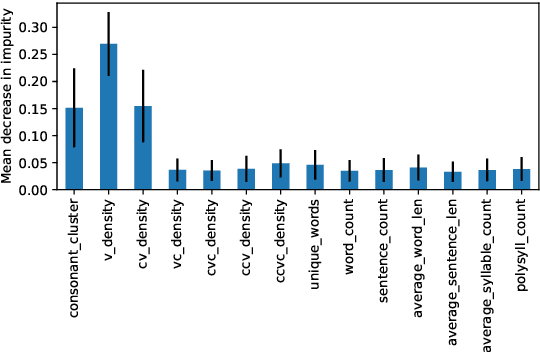
In this study, we developed the first baseline readability model for the Cebuano language. Cebuano is the second most-used native language in the Philippines with about 27.5 million speakers. As the baseline, we extracted traditional or surface-based features, syllable patterns based from Cebuano's documented orthography, and neural embeddings from the multilingual BERT model. Results show that the use of the first two handcrafted linguistic features obtained the best performance trained on an optimized Random Forest model with approximately 87% across all metrics. The feature sets and algorithm used also is similar to previous results in readability assessment for the Filipino language showing potential of crosslingual application. To encourage more work for readability assessment in Philippine languages such as Cebuano, we open-sourced both code and data.
NU HLT at CMCL 2022 Shared Task: Multilingual and Crosslingual Prediction of Human Reading Behavior in Universal Language Space
Feb 27, 2022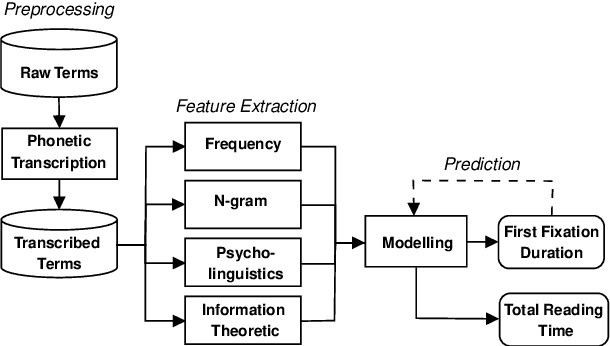
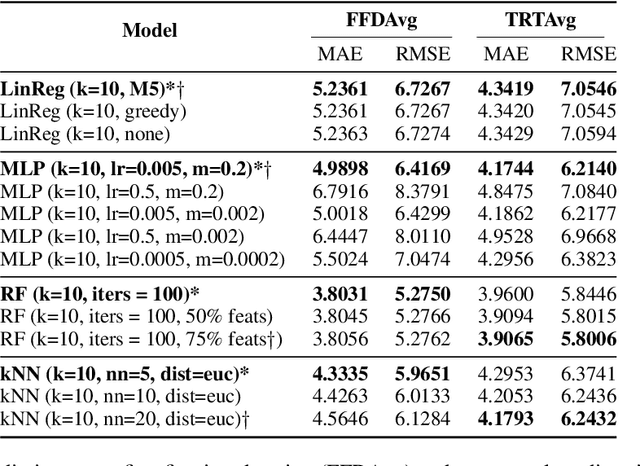
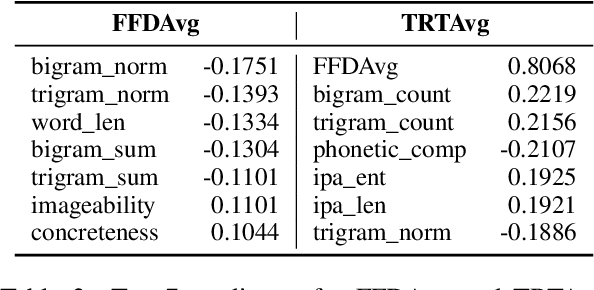
In this paper, we present a unified model that works for both multilingual and crosslingual prediction of reading times of words in various languages. The secret behind the success of this model is in the preprocessing step where all words are transformed to their universal language representation via the International Phonetic Alphabet (IPA). To the best of our knowledge, this is the first study to favorable exploit this phonological property of language for the two tasks. Various feature types were extracted covering basic frequencies, n-grams, information theoretic, and psycholinguistically-motivated predictors for model training. A finetuned Random Forest model obtained best performance for both tasks with 3.8031 and 3.9065 MAE scores for mean first fixation duration (FFDAvg) and mean total reading time (TRTAvg) respectively.
Under the Microscope: Interpreting Readability Assessment Models for Filipino
Oct 01, 2021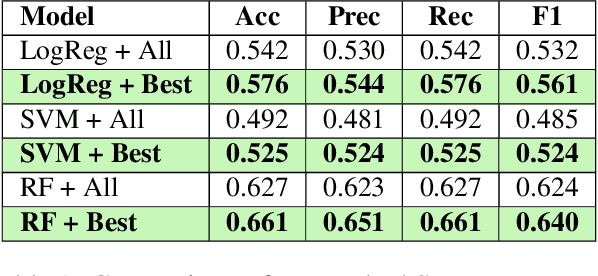
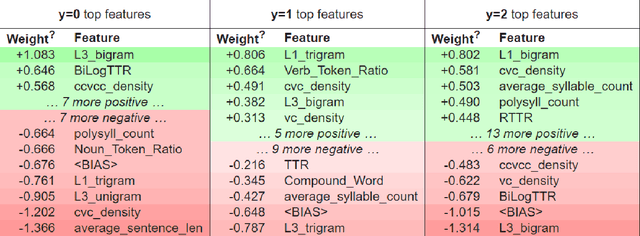
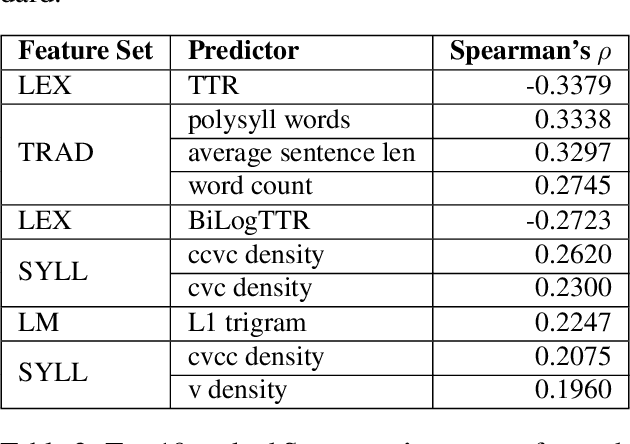
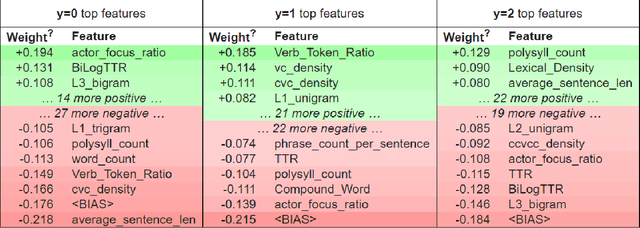
Readability assessment is the process of identifying the level of ease or difficulty of a certain piece of text for its intended audience. Approaches have evolved from the use of arithmetic formulas to more complex pattern-recognizing models trained using machine learning algorithms. While using these approaches provide competitive results, limited work is done on analyzing how linguistic variables affect model inference quantitatively. In this work, we dissect machine learning-based readability assessment models in Filipino by performing global and local model interpretation to understand the contributions of varying linguistic features and discuss its implications in the context of the Filipino language. Results show that using a model trained with top features from global interpretation obtained higher performance than the ones using features selected by Spearman correlation. Likewise, we also empirically observed local feature weight boundaries for discriminating reading difficulty at an extremely fine-grained level and their corresponding effects if values are perturbed.