 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder the Microscope: Interpreting Readability Assessment Models for Filipino
Oct 01, 2021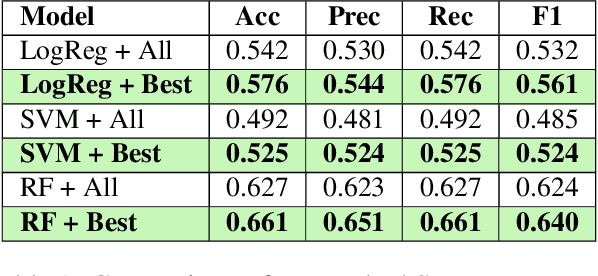
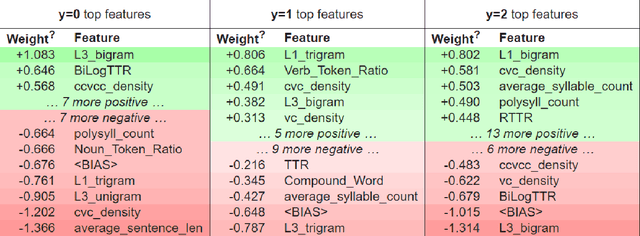
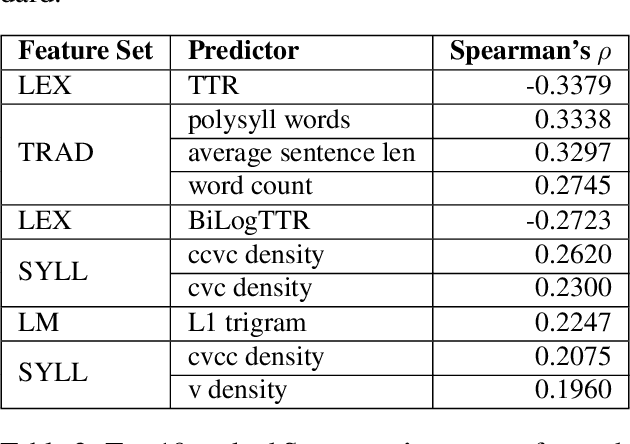
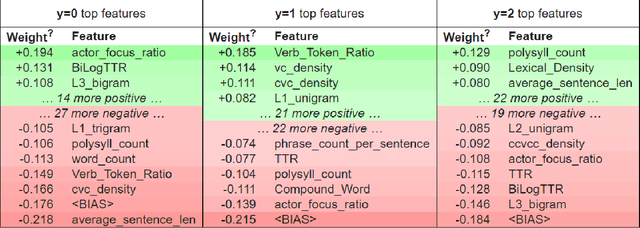
Readability assessment is the process of identifying the level of ease or difficulty of a certain piece of text for its intended audience. Approaches have evolved from the use of arithmetic formulas to more complex pattern-recognizing models trained using machine learning algorithms. While using these approaches provide competitive results, limited work is done on analyzing how linguistic variables affect model inference quantitatively. In this work, we dissect machine learning-based readability assessment models in Filipino by performing global and local model interpretation to understand the contributions of varying linguistic features and discuss its implications in the context of the Filipino language. Results show that using a model trained with top features from global interpretation obtained higher performance than the ones using features selected by Spearman correlation. Likewise, we also empirically observed local feature weight boundaries for discriminating reading difficulty at an extremely fine-grained level and their corresponding effects if values are perturbed.
Diverse Linguistic Features for Assessing Reading Difficulty of Educational Filipino Texts
Jul 31, 2021
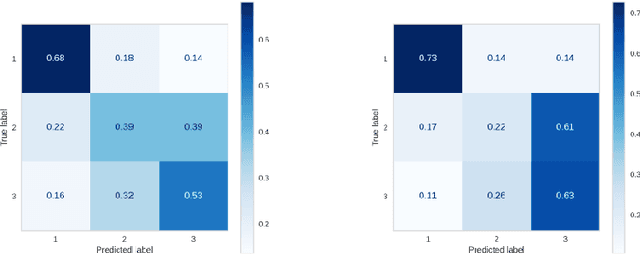
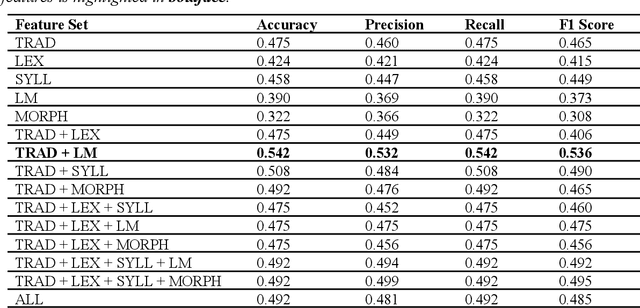
In order to ensure quality and effective learning, fluency, and comprehension, the proper identification of the difficulty levels of reading materials should be observed. In this paper, we describe the development of automatic machine learning-based readability assessment models for educational Filipino texts using the most diverse set of linguistic features for the language. Results show that using a Random Forest model obtained a high performance of 62.7% in terms of accuracy, and 66.1% when using the optimal combination of feature sets consisting of traditional and syllable pattern-based predictors.
A Simple Post-Processing Technique for Improving Readability Assessment of Texts using Word Mover's Distance
Mar 12, 2021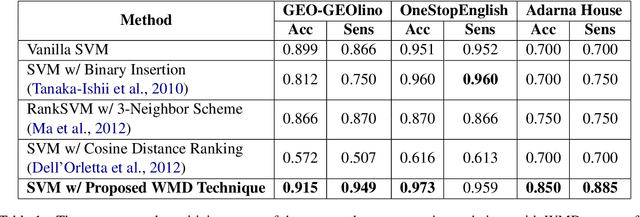
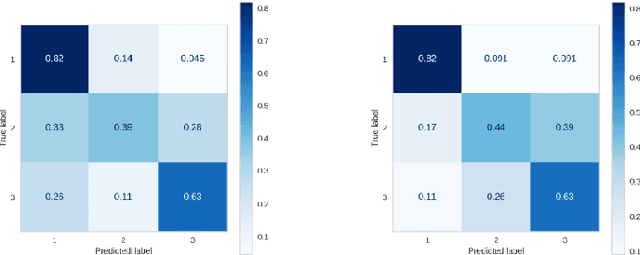
Assessing the proper difficulty levels of reading materials or texts in general is the first step towards effective comprehension and learning. In this study, we improve the conventional methodology of automatic readability assessment by incorporating the Word Mover's Distance (WMD) of ranked texts as an additional post-processing technique to further ground the difficulty level given by a model. Results of our experiments on three multilingual datasets in Filipino, German, and English show that the post-processing technique outperforms previous vanilla and ranking-based models using SVM.
Application of Lexical Features Towards Improvement of Filipino Readability Identification of Children's Literature
Jan 22, 2021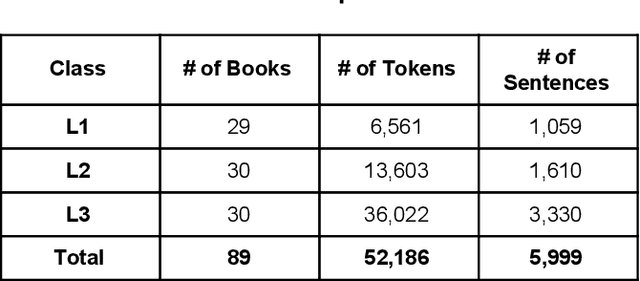
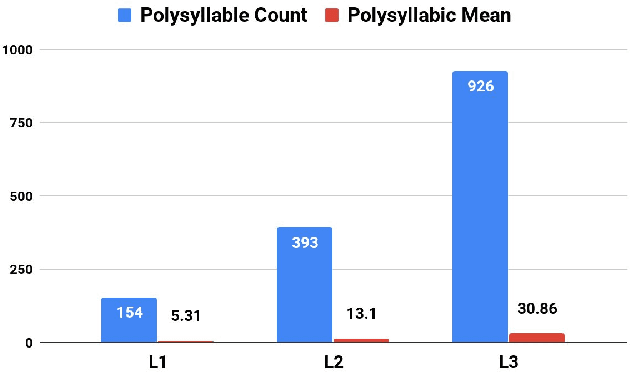
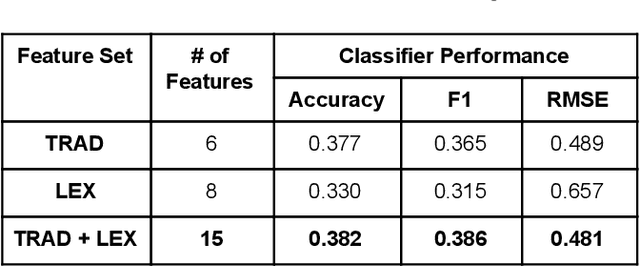
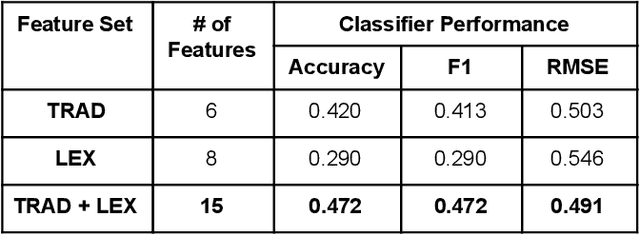
Proper identification of grade levels of children's reading materials is an important step towards effective learning. Recent studies in readability assessment for the English domain applied modern approaches in natural language processing (NLP) such as machine learning (ML) techniques to automate the process. There is also a need to extract the correct linguistic features when modeling readability formulas. In the context of the Filipino language, limited work has been done [1, 2], especially in considering the language's lexical complexity as main features. In this paper, we explore the use of lexical features towards improving the development of readability identification of children's books written in Filipino. Results show that combining lexical features (LEX) consisting of type-token ratio, lexical density, lexical variation, foreign word count with traditional features (TRAD) used by previous works such as sentence length, average syllable length, polysyllabic words, word, sentence, and phrase counts increased the performance of readability models by almost a 5% margin (from 42% to 47.2%). Further analysis and ranking of the most important features were shown to identify which features contribute the most in terms of reading complexity.