 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Translationese: why are Neural Classifiers Better and what do they Learn?
Oct 24, 2022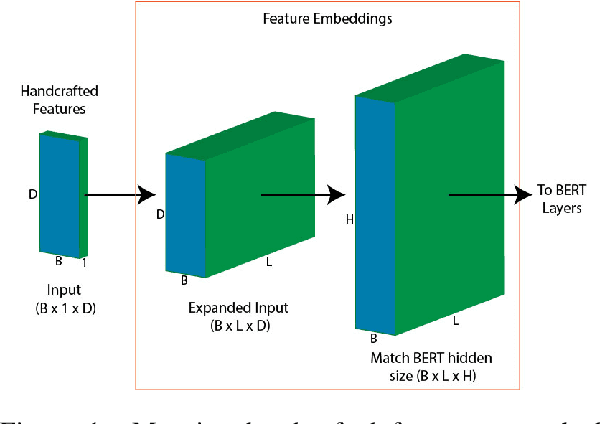


Recent work has shown that neural feature- and representation-learning, e.g. BERT, achieves superior performance over traditional manual feature engineering based approaches, with e.g. SVMs, in translationese classification tasks. Previous research did not show $(i)$ whether the difference is because of the features, the classifiers or both, and $(ii)$ what the neural classifiers actually learn. To address $(i)$, we carefully design experiments that swap features between BERT- and SVM-based classifiers. We show that an SVM fed with BERT representations performs at the level of the best BERT classifiers, while BERT learning and using handcrafted features performs at the level of an SVM using handcrafted features. This shows that the performance differences are due to the features. To address $(ii)$ we use integrated gradients and find that $(a)$ there is indication that information captured by hand-crafted features is only a subset of what BERT learns, and $(b)$ part of BERT's top performance results are due to BERT learning topic differences and spurious correlations with translationese.
Exploiting Social Media Content for Self-Supervised Style Transfer
May 18, 2022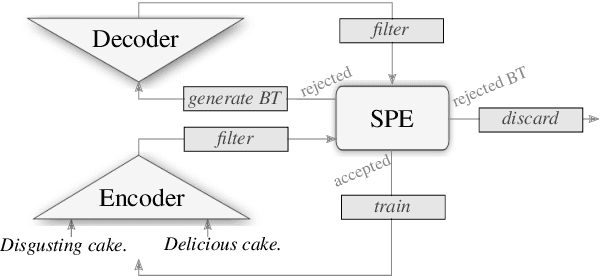
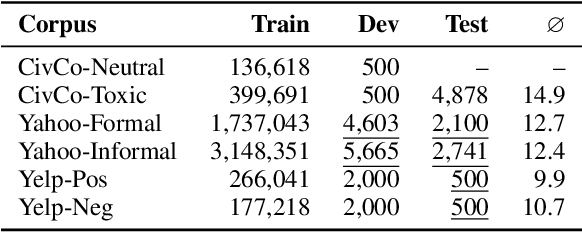
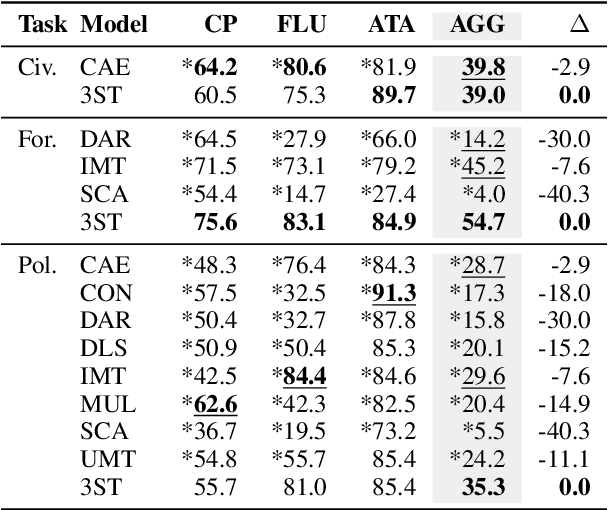
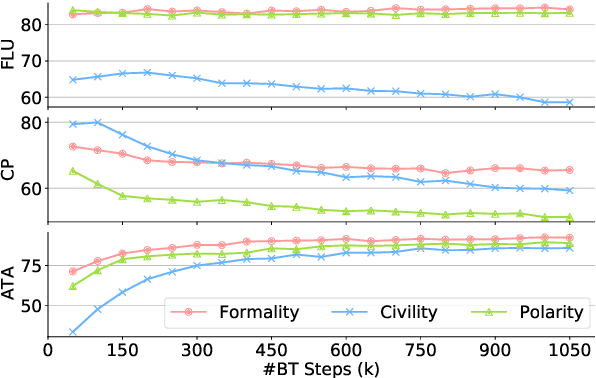
Recent research on style transfer takes inspiration from unsupervised neural machine translation (UNMT), learning from large amounts of non-parallel data by exploiting cycle consistency loss, back-translation, and denoising autoencoders. By contrast, the use of self-supervised NMT (SSNMT), which leverages (near) parallel instances hidden in non-parallel data more efficiently than UNMT, has not yet been explored for style transfer. In this paper we present a novel Self-Supervised Style Transfer (3ST) model, which augments SSNMT with UNMT methods in order to identify and efficiently exploit supervisory signals in non-parallel social media posts. We compare 3ST with state-of-the-art (SOTA) style transfer models across civil rephrasing, formality and polarity tasks. We show that 3ST is able to balance the three major objectives (fluency, content preservation, attribute transfer accuracy) the best, outperforming SOTA models on averaged performance across their tested tasks in automatic and human evaluation.
Towards Debiasing Translation Artifacts
May 16, 2022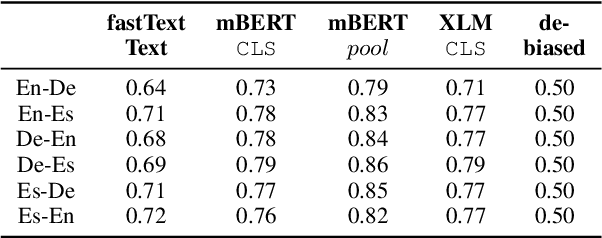
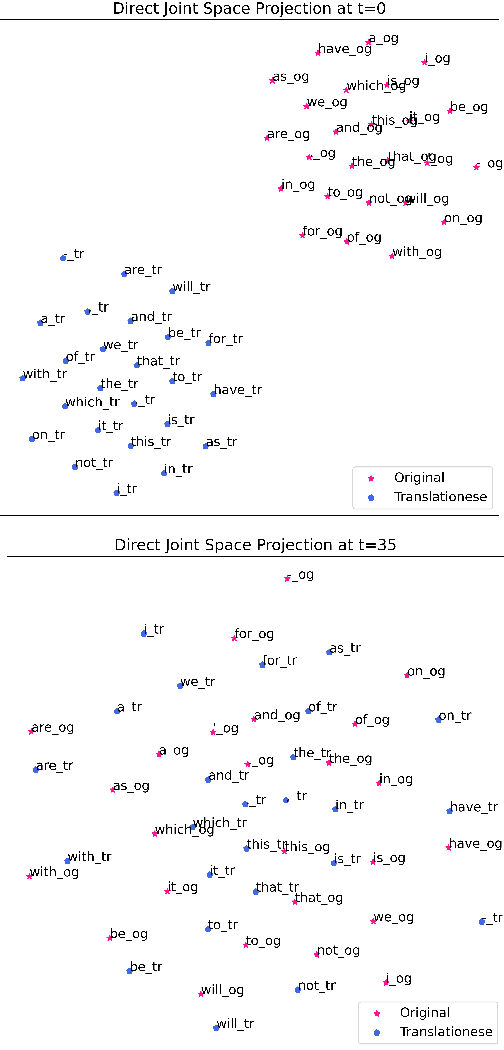
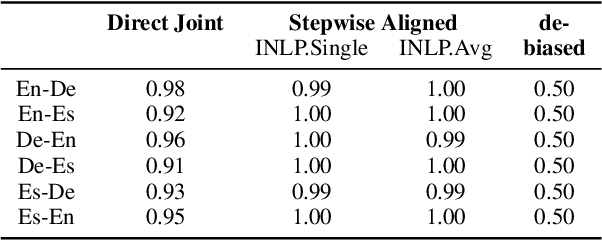
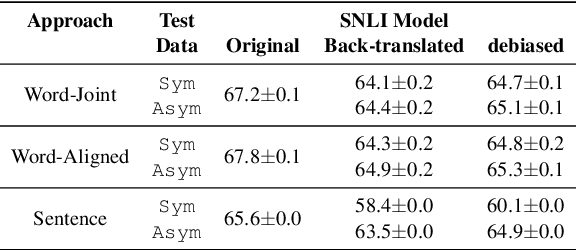
Cross-lingual natural language processing relies on translation, either by humans or machines, at different levels, from translating training data to translating test sets. However, compared to original texts in the same language, translations possess distinct qualities referred to as translationese. Previous research has shown that these translation artifacts influence the performance of a variety of cross-lingual tasks. In this work, we propose a novel approach to reducing translationese by extending an established bias-removal technique. We use the Iterative Null-space Projection (INLP) algorithm, and show by measuring classification accuracy before and after debiasing, that translationese is reduced at both sentence and word level. We evaluate the utility of debiasing translationese on a natural language inference (NLI) task, and show that by reducing this bias, NLI accuracy improves. To the best of our knowledge, this is the first study to debias translationese as represented in latent embedding space.
Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification
Sep 15, 2021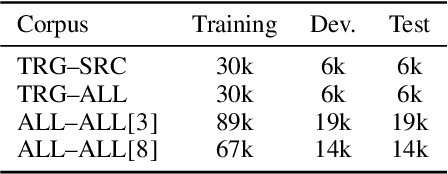
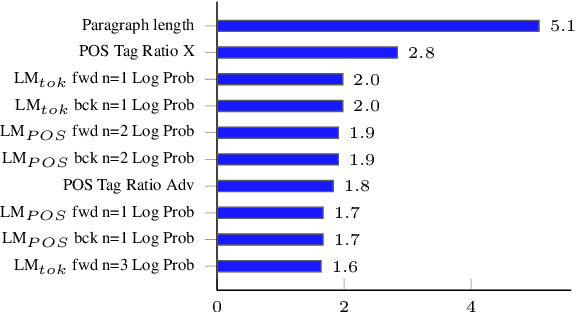
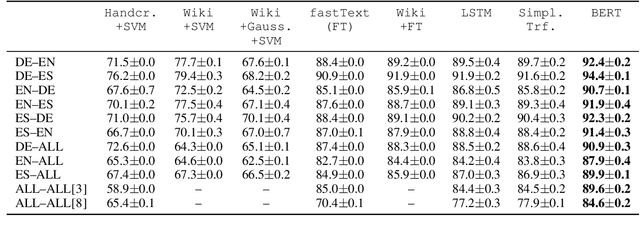
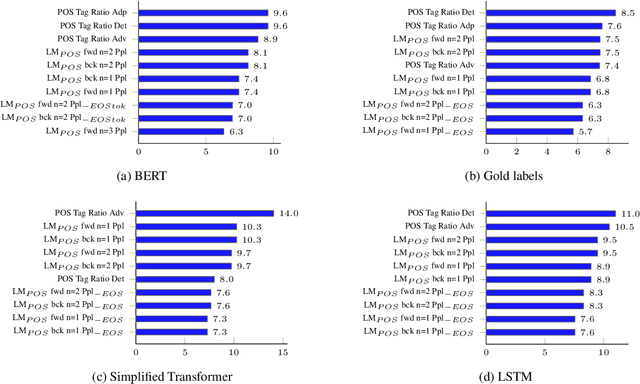
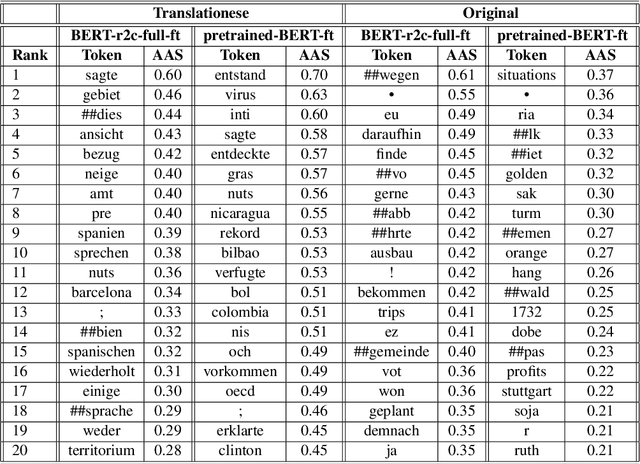
Traditional hand-crafted linguistically-informed features have often been used for distinguishing between translated and original non-translated texts. By contrast, to date, neural architectures without manual feature engineering have been less explored for this task. In this work, we (i) compare the traditional feature-engineering-based approach to the feature-learning-based one and (ii) analyse the neural architectures in order to investigate how well the hand-crafted features explain the variance in the neural models' predictions. We use pre-trained neural word embeddings, as well as several end-to-end neural architectures in both monolingual and multilingual settings and compare them to feature-engineering-based SVM classifiers. We show that (i) neural architectures outperform other approaches by more than 20 accuracy points, with the BERT-based model performing the best in both the monolingual and multilingual settings; (ii) while many individual hand-crafted translationese features correlate with neural model predictions, feature importance analysis shows that the most important features for neural and classical architectures differ; and (iii) our multilingual experiments provide empirical evidence for translationese universals across languages.
Integrating Unsupervised Data Generation into Self-Supervised Neural Machine Translation for Low-Resource Languages
Jul 19, 2021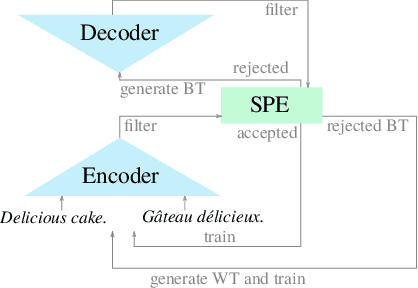
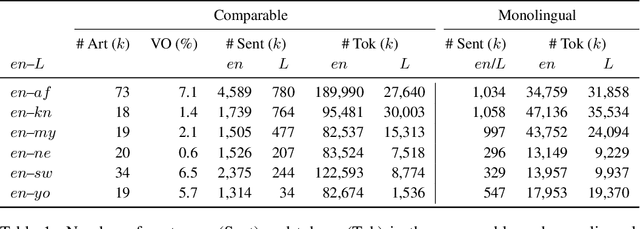
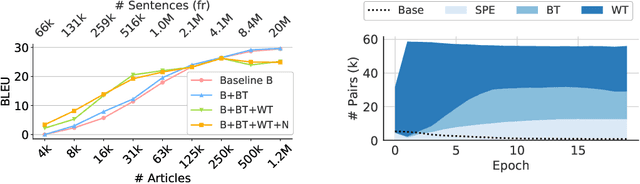

For most language combinations, parallel data is either scarce or simply unavailable. To address this, unsupervised machine translation (UMT) exploits large amounts of monolingual data by using synthetic data generation techniques such as back-translation and noising, while self-supervised NMT (SSNMT) identifies parallel sentences in smaller comparable data and trains on them. To date, the inclusion of UMT data generation techniques in SSNMT has not been investigated. We show that including UMT techniques into SSNMT significantly outperforms SSNMT and UMT on all tested language pairs, with improvements of up to +4.3 BLEU, +50.8 BLEU, +51.5 over SSNMT, statistical UMT and hybrid UMT, respectively, on Afrikaans to English. We further show that the combination of multilingual denoising autoencoding, SSNMT with backtranslation and bilingual finetuning enables us to learn machine translation even for distant language pairs for which only small amounts of monolingual data are available, e.g. yielding BLEU scores of 11.6 (English to Swahili).
Linguistically inspired morphological inflection with a sequence to sequence model
Sep 04, 2020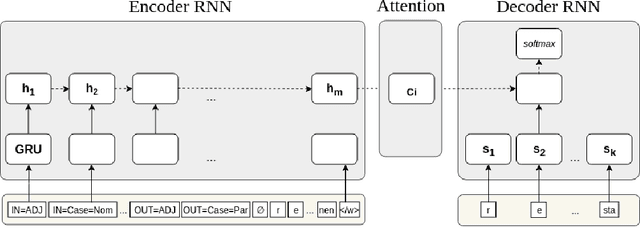
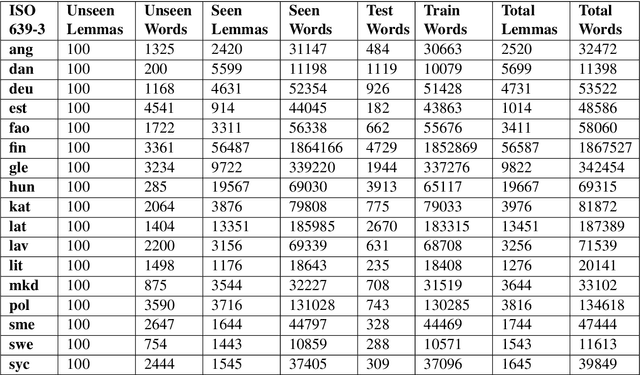
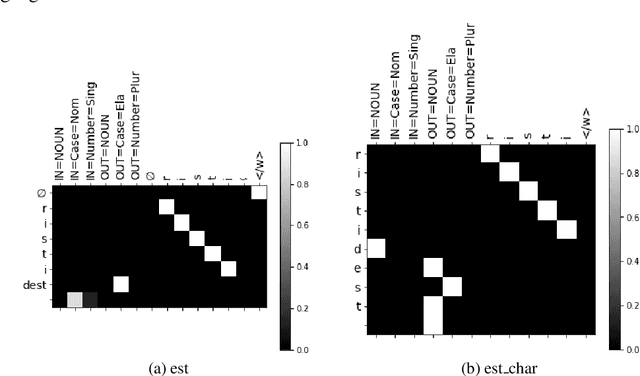
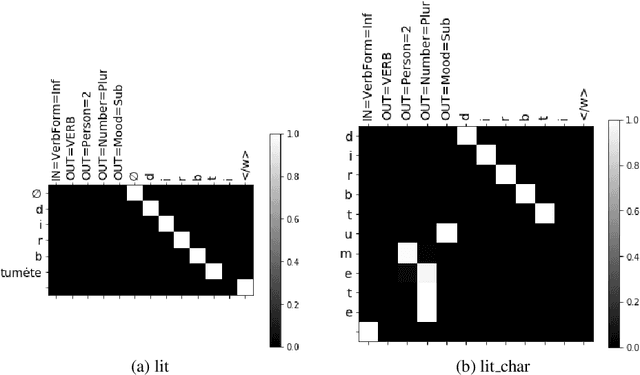
Inflection is an essential part of every human language's morphology, yet little effort has been made to unify linguistic theory and computational methods in recent years. Methods of string manipulation are used to infer inflectional changes; our research question is whether a neural network would be capable of learning inflectional morphemes for inflection production in a similar way to a human in early stages of language acquisition. We are using an inflectional corpus (Metheniti and Neumann, 2020) and a single layer seq2seq model to test this hypothesis, in which the inflectional affixes are learned and predicted as a block and the word stem is modelled as a character sequence to account for infixation. Our character-morpheme-based model creates inflection by predicting the stem character-to-character and the inflectional affixes as character blocks. We conducted three experiments on creating an inflected form of a word given the lemma and a set of input and target features, comparing our architecture to a mainstream character-based model with the same hyperparameters, training and test sets. Overall for 17 languages, we noticed small improvements on inflecting known lemmas (+0.68%) but steadily better performance of our model in predicting inflected forms of unknown words (+3.7%) and small improvements on predicting in a low-resource scenario (+1.09%)
Transformer with Depth-Wise LSTM
Jul 13, 2020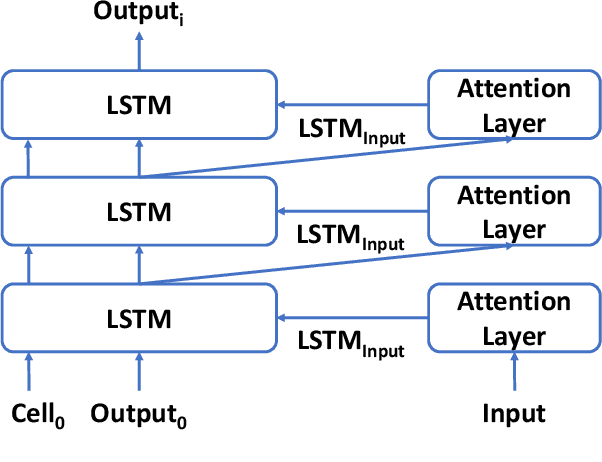
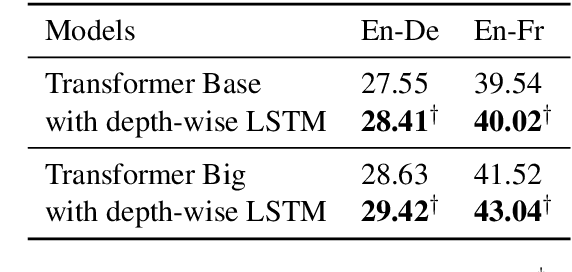
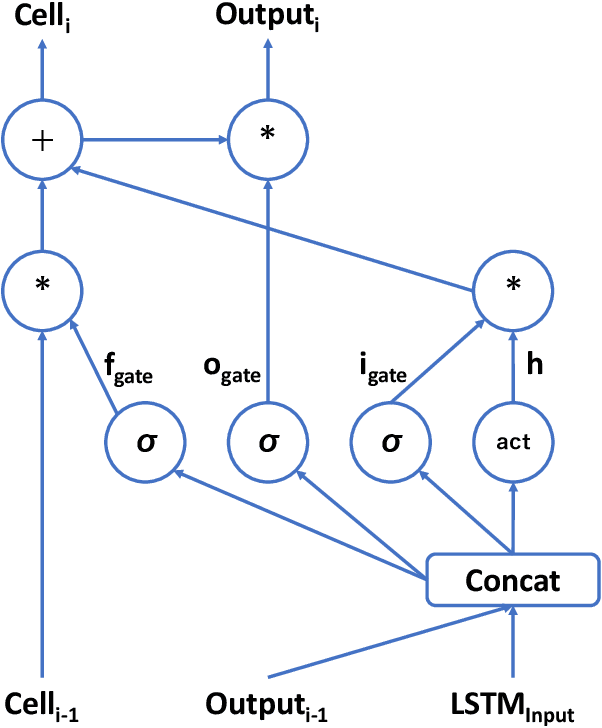

Increasing the depth of models allows neural models to model complicated functions but may also lead to optimization issues. The Transformer translation model employs the residual connection to ensure its convergence. In this paper, we suggest that the residual connection has its drawbacks, and propose to train Transformers with the depth-wise LSTM which regards outputs of layers as steps in time series instead of residual connections, under the motivation that the vanishing gradient problem suffered by deep networks is the same as recurrent networks applied to long sequences, while LSTM (Hochreiter and Schmidhuber, 1997) has been proven of good capability in capturing long-distance relationship, and its design may alleviate some drawbacks of residual connections while ensuring the convergence. We integrate the computation of multi-head attention networks and feed-forward networks with the depth-wise LSTM for the Transformer, which shows how to utilize the depth-wise LSTM like the residual connection. Our experiment with the 6-layer Transformer shows that our approach can bring about significant BLEU improvements in both WMT 14 English-German and English-French tasks, and our deep Transformer experiment demonstrates the effectiveness of the depth-wise LSTM on the convergence of deep Transformers. Additionally, we propose to measure the impacts of the layer's non-linearity on the performance by distilling the analyzing layer of the trained model into a linear transformation and observing the performance degradation with the replacement. Our analysis results support the more efficient use of per-layer non-linearity with depth-wise LSTM than with residual connections.
Learning Source Phrase Representations for Neural Machine Translation
Jun 25, 2020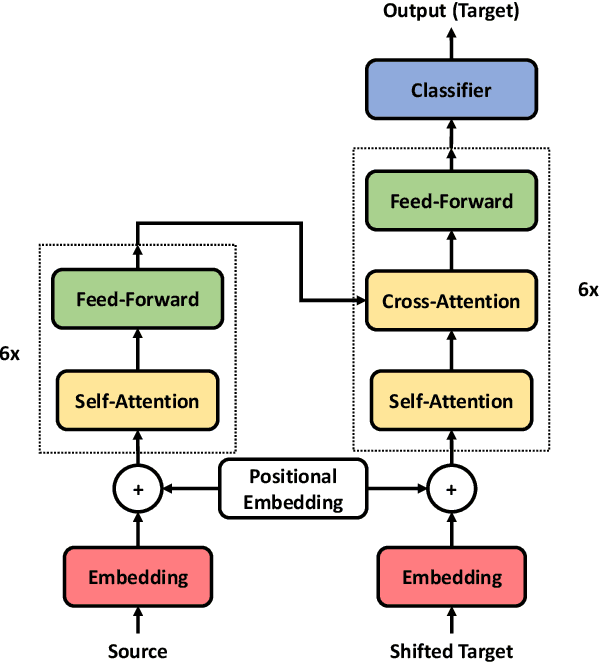
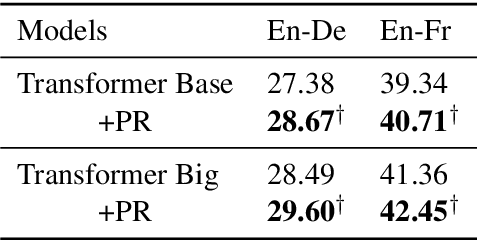
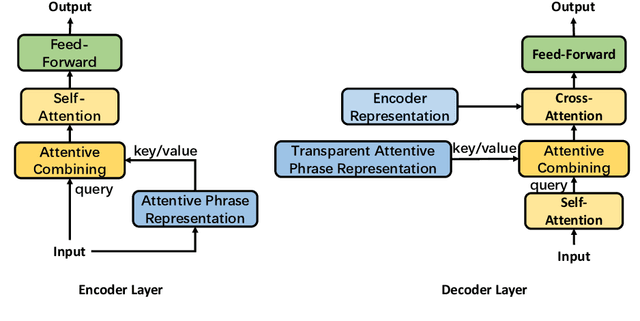
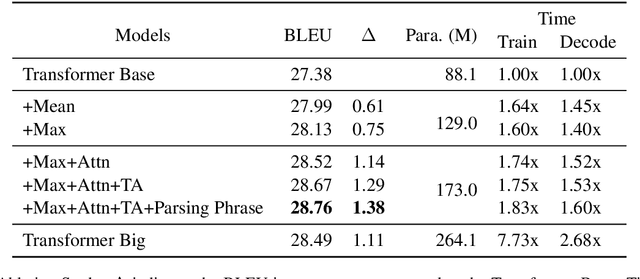
The Transformer translation model (Vaswani et al., 2017) based on a multi-head attention mechanism can be computed effectively in parallel and has significantly pushed forward the performance of Neural Machine Translation (NMT). Though intuitively the attentional network can connect distant words via shorter network paths than RNNs, empirical analysis demonstrates that it still has difficulty in fully capturing long-distance dependencies (Tang et al., 2018). Considering that modeling phrases instead of words has significantly improved the Statistical Machine Translation (SMT) approach through the use of larger translation blocks ("phrases") and its reordering ability, modeling NMT at phrase level is an intuitive proposal to help the model capture long-distance relationships. In this paper, we first propose an attentive phrase representation generation mechanism which is able to generate phrase representations from corresponding token representations. In addition, we incorporate the generated phrase representations into the Transformer translation model to enhance its ability to capture long-distance relationships. In our experiments, we obtain significant improvements on the WMT 14 English-German and English-French tasks on top of the strong Transformer baseline, which shows the effectiveness of our approach. Our approach helps Transformer Base models perform at the level of Transformer Big models, and even significantly better for long sentences, but with substantially fewer parameters and training steps. The fact that phrase representations help even in the big setting further supports our conjecture that they make a valuable contribution to long-distance relations.
Dynamically Adjusting Transformer Batch Size by Monitoring Gradient Direction Change
May 05, 2020
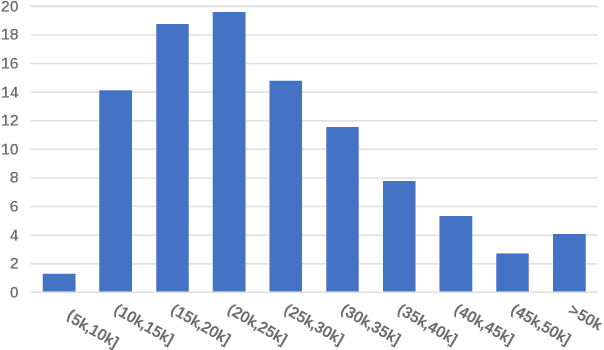
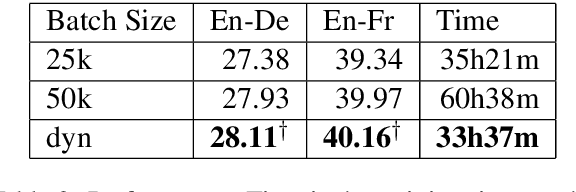
The choice of hyper-parameters affects the performance of neural models. While much previous research (Sutskever et al., 2013; Duchi et al., 2011; Kingma and Ba, 2015) focuses on accelerating convergence and reducing the effects of the learning rate, comparatively few papers concentrate on the effect of batch size. In this paper, we analyze how increasing batch size affects gradient direction, and propose to evaluate the stability of gradients with their angle change. Based on our observations, the angle change of gradient direction first tends to stabilize (i.e. gradually decrease) while accumulating mini-batches, and then starts to fluctuate. We propose to automatically and dynamically determine batch sizes by accumulating gradients of mini-batches and performing an optimization step at just the time when the direction of gradients starts to fluctuate. To improve the efficiency of our approach for large models, we propose a sampling approach to select gradients of parameters sensitive to the batch size. Our approach dynamically determines proper and efficient batch sizes during training. In our experiments on the WMT 14 English to German and English to French tasks, our approach improves the Transformer with a fixed 25k batch size by +0.73 and +0.82 BLEU respectively.
Self-Induced Curriculum Learning in Neural Machine Translation
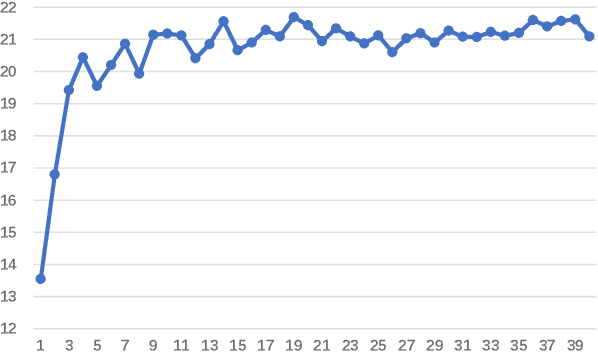
Apr 07, 2020
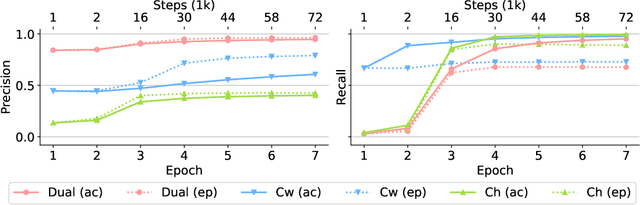
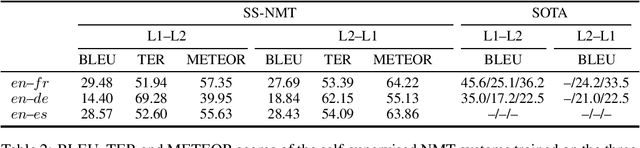
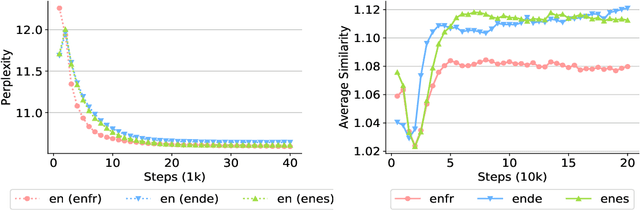
Self-supervised neural machine translation (SS-NMT) learns how to extract/select suitable training data from comparable -- rather than parallel -- corpora and how to translate, in a way that the two tasks support each other in a virtuous circle. SS-NMT has been shown to be competitive with state-of-the-art unsupervised NMT. In this study we provide an in-depth analysis of the sampling choices the SS-NMT model takes during training. We show that, without it having been told to do so, the model selects samples of increasing (i) complexity and (ii) task-relevance in combination with (iii) a denoising curriculum. We observe that the dynamics of the mutual-supervision of both system internal representation types is vital for the extraction and hence translation performance. We show that in terms of the human Gunning-Fog Readability index (GF), SS-NMT starts by extracting and learning from Wikipedia data suitable for high school (GF=10--11) and quickly moves towards content suitable for first year undergraduate students (GF=13).