 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAEM: a Deep Generative Model for Heterogeneous Mixed Type Data
Jun 21, 2020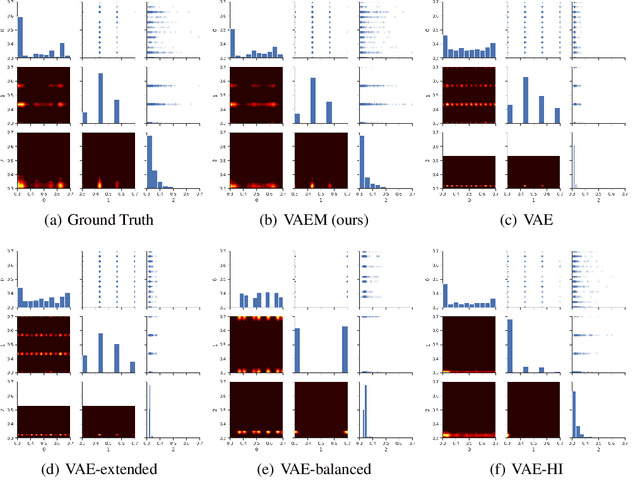

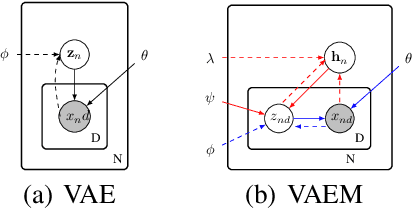
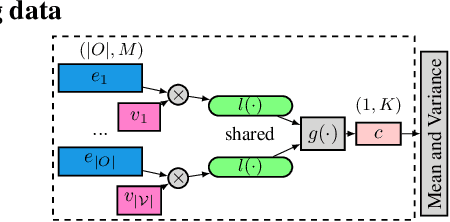
Deep generative models often perform poorly in real-world applications due to the heterogeneity of natural data sets. Heterogeneity arises from data containing different types of features (categorical, ordinal, continuous, etc.) and features of the same type having different marginal distributions. We propose an extension of variational autoencoders (VAEs) called VAEM to handle such heterogeneous data. VAEM is a deep generative model that is trained in a two stage manner such that the first stage provides a more uniform representation of the data to the second stage, thereby sidestepping the problems caused by heterogeneous data. We provide extensions of VAEM to handle partially observed data, and demonstrate its performance in data generation, missing data prediction and sequential feature selection tasks. Our results show that VAEM broadens the range of real-world applications where deep generative models can be successfully deployed.
Sample-Efficient Optimization in the Latent Space of Deep Generative Models via Weighted Retraining
Jun 16, 2020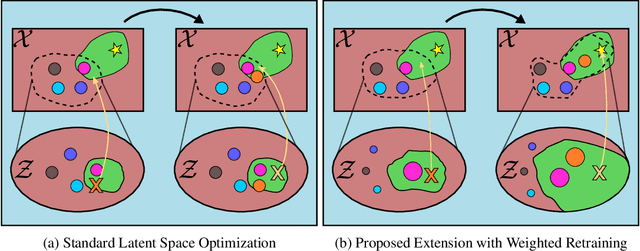
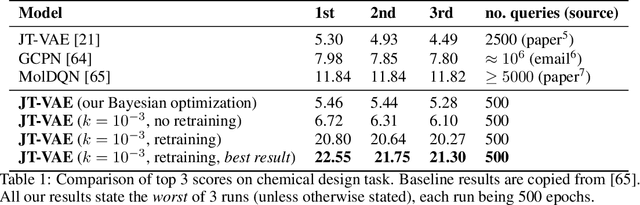


Many important problems in science and engineering, such as drug design, involve optimizing an expensive black-box objective function over a complex, high-dimensional, and structured input space. Although machine learning techniques have shown promise in solving such problems, existing approaches substantially lack sample efficiency. We introduce an improved method for efficient black-box optimization, which performs the optimization in the low-dimensional, continuous latent manifold learned by a deep generative model. In contrast to previous approaches, we actively steer the generative model to maintain a latent manifold that is highly useful for efficiently optimizing the objective. We achieve this by periodically retraining the generative model on the data points queried along the optimization trajectory, as well as weighting those data points according to their objective function value. This weighted retraining can be easily implemented on top of existing methods, and is empirically shown to significantly improve their efficiency and performance on synthetic and real-world optimization problems.
Depth Uncertainty in Neural Networks
Jun 15, 2020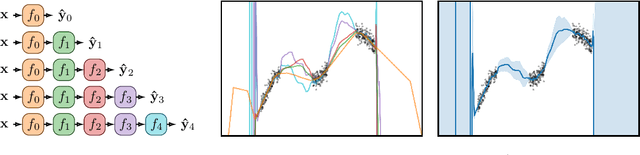

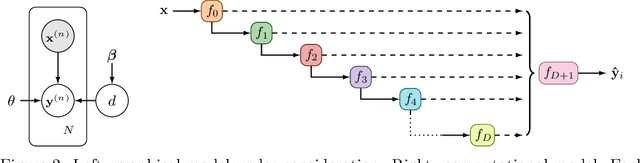

Existing methods for estimating uncertainty in deep learning tend to require multiple forward passes, making them unsuitable for applications where computational resources are limited. To solve this, we perform probabilistic reasoning over the depth of neural networks. Different depths correspond to subnetworks which share weights and whose predictions are combined via marginalisation, yielding model uncertainty. By exploiting the sequential structure of feed-forward networks, we are able to both evaluate our training objective and make predictions with a single forward pass. We validate our approach on real-world regression and image classification tasks. Our approach provides uncertainty calibration, robustness to dataset shift, and accuracies competitive with more computationally expensive baselines.
Getting a CLUE: A Method for Explaining Uncertainty Estimates
Jun 11, 2020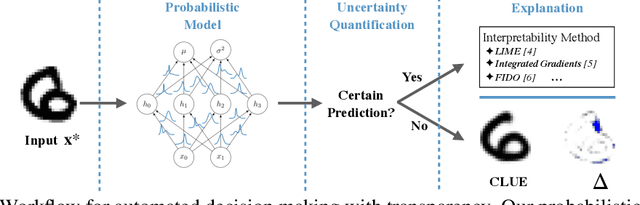


Both uncertainty estimation and interpretability are important factors for trustworthy machine learning systems. However, there is little work at the intersection of these two areas. We address this gap by proposing a novel method for interpreting uncertainty estimates from differentiable probabilistic models, like Bayesian Neural Networks (BNNs). Our method, Counterfactual Latent Uncertainty Explanations (CLUE), indicates how to change an input, while keeping it on the data manifold, such that a BNN becomes more confident about the input's prediction. We validate CLUE through 1) a novel framework for evaluating counterfactual explanations of uncertainty, 2) a series of ablation experiments, and 3) a user study. Our experiments show that CLUE outperforms baselines and enables practitioners to better understand which input patterns are responsible for predictive uncertainty.
Excursion Search for Constrained Bayesian Optimization under a Limited Budget of Failures
May 15, 2020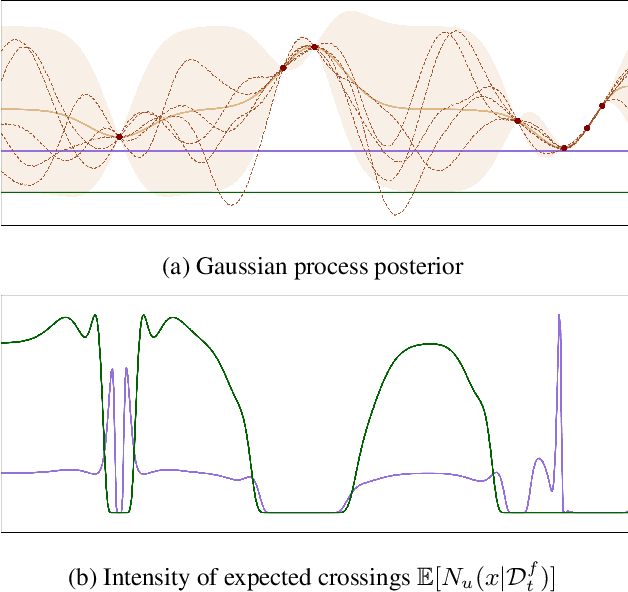
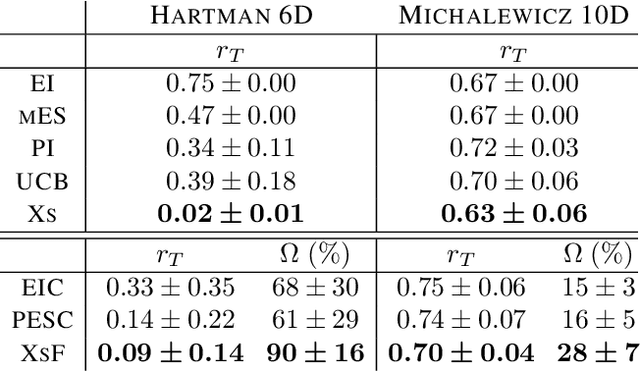
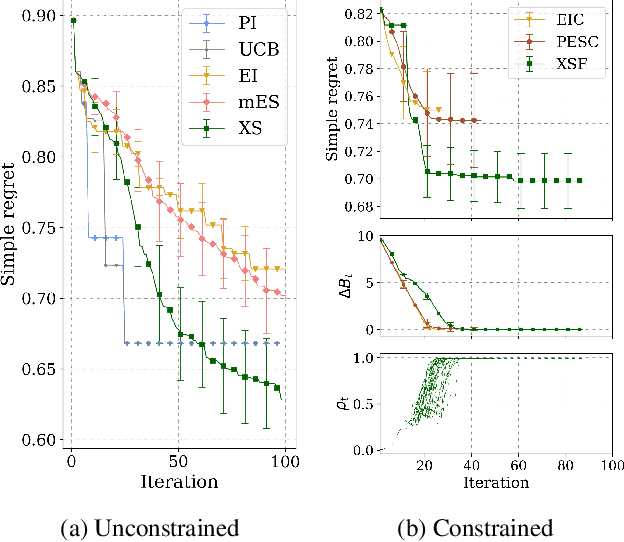
When learning to ride a bike, a child falls down a number of times before achieving the first success. As falling down usually has only mild consequences, it can be seen as a tolerable failure in exchange for a faster learning process, as it provides rich information about an undesired behavior. In the context of Bayesian optimization under unknown constraints (BOC), typical strategies for safe learning explore conservatively and avoid failures by all means. On the other side of the spectrum, non conservative BOC algorithms that allow failing may fail an unbounded number of times before reaching the optimum. In this work, we propose a novel decision maker grounded in control theory that controls the amount of risk we allow in the search as a function of a given budget of failures. Empirical validation shows that our algorithm uses the failures budget more efficiently in a variety of optimization experiments, and generally achieves lower regret, than state-of-the-art methods. In addition, we propose an original algorithm for unconstrained Bayesian optimization inspired by the notion of excursion sets in stochastic processes, upon which the failures-aware algorithm is built.
Variational Depth Search in ResNets
Feb 27, 2020
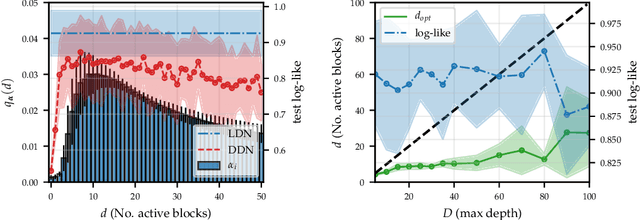
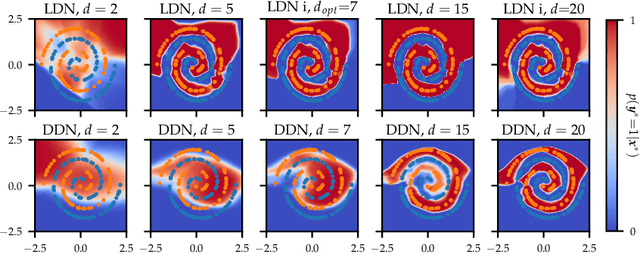
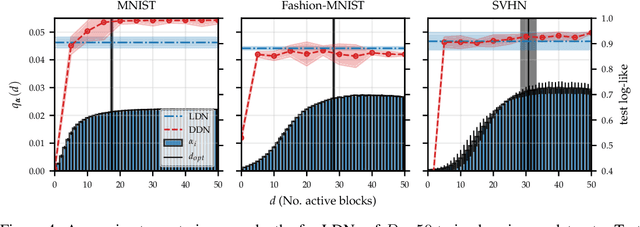
One-shot neural architecture search allows joint learning of weights and network architecture, reducing computational cost. We limit our search space to the depth of residual networks and formulate an analytically tractable variational objective that allows for obtaining an unbiased approximate posterior over depths in one-shot. We propose a heuristic to prune our networks based on this distribution. We compare our proposed method against manual search over network depths on the MNIST, Fashion-MNIST, SVHN datasets. We find that pruned networks do not incur a loss in predictive performance, obtaining accuracies competitive with unpruned networks. Marginalising over depth allows us to obtain better-calibrated test-time uncertainty estimates than regular networks, in a single forward pass.
Reinforcement Learning for Molecular Design Guided by Quantum Mechanics
Feb 18, 2020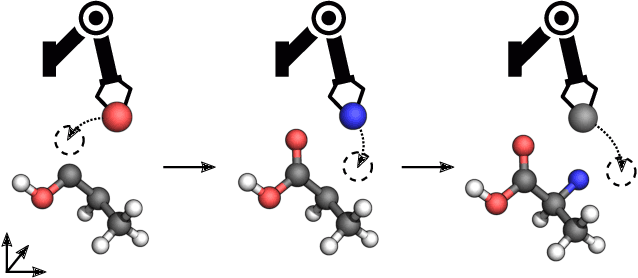

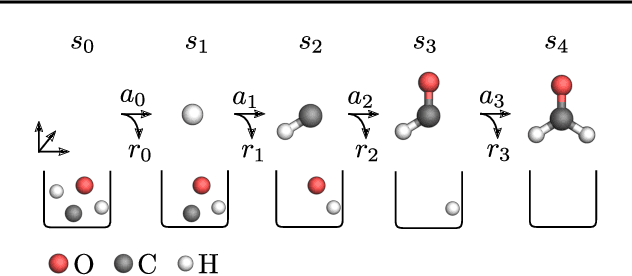
Automating molecular design using deep reinforcement learning (RL) holds the promise of accelerating the discovery of new chemical compounds. A limitation of existing approaches is that they work with molecular graphs and thus ignore the location of atoms in space, which restricts them to 1) generating single organic molecules and 2) heuristic reward functions. To address this, we present a novel RL formulation for molecular design in Cartesian coordinates, thereby extending the class of molecules that can be built. Our reward function is directly based on fundamental physical properties such as the energy, which we approximate via fast quantum-chemical methods. To enable progress towards de-novo molecular design, we introduce MolGym, an RL environment comprising several challenging molecular design tasks along with baselines. In our experiments, we show that our agent can efficiently learn to solve these tasks from scratch by working in a translation and rotation invariant state-action space.
Bayesian Variational Autoencoders for Unsupervised Out-of-Distribution Detection
Dec 11, 2019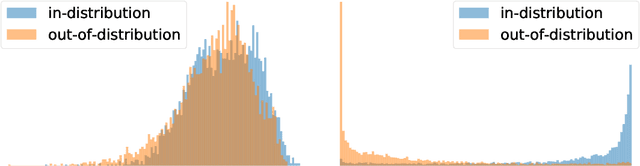
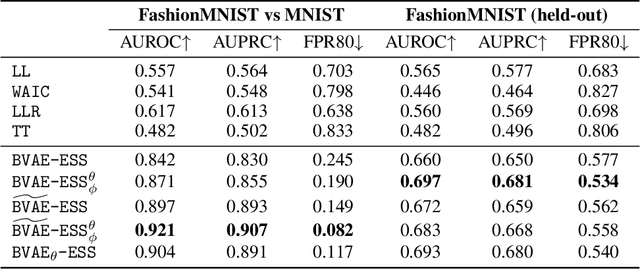
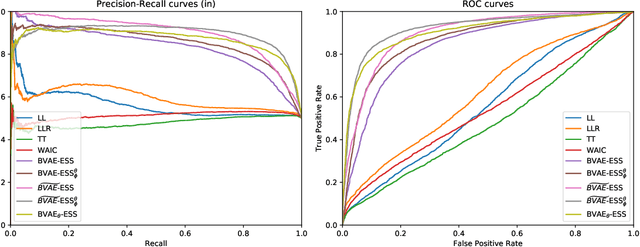
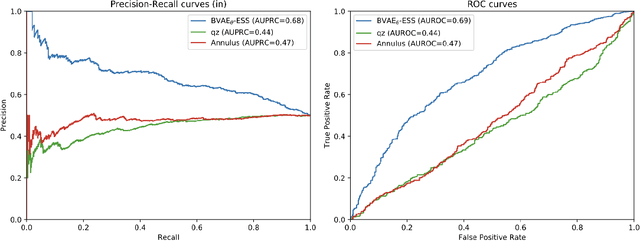
Despite their successes, deep neural networks still make unreliable predictions when faced with test data drawn from a distribution different to that of the training data, constituting a major problem for AI safety. While this motivated a recent surge in interest in developing methods to detect such out-of-distribution (OoD) inputs, a robust solution is still lacking. We propose a new probabilistic, unsupervised approach to this problem based on a Bayesian variational autoencoder model, which estimates a full posterior distribution over the decoder parameters using stochastic gradient Markov chain Monte Carlo, instead of fitting a point estimate. We describe how information-theoretic measures based on this posterior can then be used to detect OoD data both in input space as well as in the model's latent space. The effectiveness of our approach is empirically demonstrated.
A Generative Model for Molecular Distance Geometry
Oct 03, 2019

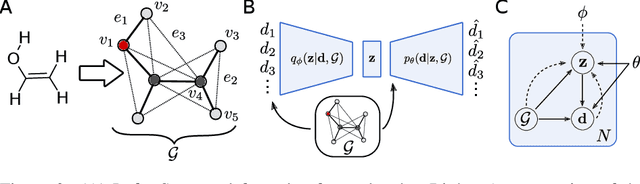
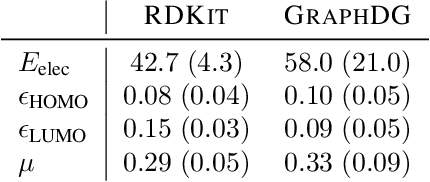
Computing equilibrium states for many-body systems, such as molecules, is a long-standing challenge. In the absence of methods for generating statistically independent samples, great computational effort is invested in simulating these systems using, for example, Markov chain Monte Carlo. We present a probabilistic model that generates such samples for molecules from their graph representations. Our model learns a low-dimensional manifold that preserves the geometry of local atomic neighborhoods through a principled learning representation that is based on Euclidean distance geometry. We create a new dataset for molecular conformation generation with which we show experimentally that our generative model achieves state-of-the-art accuracy. Finally, we show how to use our model as a proposal distribution in an importance sampling scheme to compute molecular properties.
Icebreaker: Element-wise Active Information Acquisition with Bayesian Deep Latent Gaussian Model
Aug 14, 2019
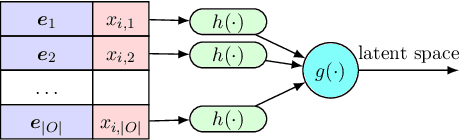
In this paper we introduce the ice-start problem, i.e., the challenge of deploying machine learning models when only little or no training data is initially available, and acquiring each feature element of data is associated with costs. This setting is representative for the real-world machine learning applications. For instance, in the health-care domain, when training an AI system for predicting patient metrics from lab tests, obtaining every single measurement comes with a high cost. Active learning, where only the label is associated with a cost does not apply to such problem, because performing all possible lab tests to acquire a new training datum would be costly, as well as unnecessary due to redundancy. We propose Icebreaker, a principled framework to approach the ice-start problem. Icebreaker uses a full Bayesian Deep Latent Gaussian Model (BELGAM) with a novel inference method. Our proposed method combines recent advances in amortized inference and stochastic gradient MCMC to enable fast and accurate posterior inference. By utilizing BELGAM's ability to fully quantify model uncertainty, we also propose two information acquisition functions for imputation and active prediction problems. We demonstrate that BELGAM performs significantly better than the previous VAE (Variational autoencoder) based models, when the data set size is small, using both machine learning benchmarks and real-world recommender systems and health-care applications. Moreover, based on BELGAM, Icebreaker further improves the performance and demonstrate the ability to use minimum amount of the training data to obtain the highest test time performance.