 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORTIS: Text-Only Adaptation of Spoken Language Models for Task-Oriented Voice Agents
Jun 19, 2026Task-oriented voice agents need to map spoken user requests to structured outputs such as semantic frames, executable actions, and function calls. A common approach is to cascade ASR with a text-based LLM, but transcription errors can propagate to downstream structured output generation, especially under noisy conditions. Spoken language models (SLMs) offer a direct speech-based alternative, yet adapting them to new tasks typically requires paired speech-target annotations. Motivated by this gap, we present CORTIS, a text-only adaptation framework for task-oriented voice agents. CORTIS fine-tunes SLMs using text-form task supervision, enabling speech-based structured output generation at inference time without task-specific speech-target annotations during adaptation. We evaluate CORTIS on two Qwen2.5-Omni backbones and three task-oriented speech datasets, including an in-house product dataset, and compare it with matched ASR-LLM cascades trained with the same text-form task supervision. Results show that CORTIS performs competitively with matched cascades and offers clearer advantages under acoustic degradation, particularly in preserving high-level task semantics. These findings suggest that text-only fine-tuning of SLMs can serve as a practical adaptation strategy for voice agents when paired speech-target data are costly to collect.
Mine-JEPA: In-Domain Self-Supervised Learning for Mine-Like Object Classification in Side-Scan Sonar
Apr 01, 2026Side-scan sonar (SSS) mine classification is a challenging maritime vision problem characterized by extreme data scarcity and a large domain gap from natural images. While self-supervised learning (SSL) and general-purpose vision foundation models have shown strong performance in general vision and several specialized domains, their use in SSS remains largely unexplored. We present Mine-JEPA, the first in-domain SSL pipeline for SSS mine classification, using SIGReg, a regularization-based SSL loss, to pretrain on only 1,170 unlabeled sonar images. In the binary mine vs. non-mine setting, Mine-JEPA achieves an F1 score of 0.935, outperforming fine-tuned DINOv3 (0.922), a foundation model pretrained on 1.7B images. For 3-class mine-like object classification, Mine-JEPA reaches 0.820 with synthetic data augmentation, again outperforming fine-tuned DINOv3 (0.810). We further observe that applying in-domain SSL to foundation models degrades performance by 10--13 percentage points, suggesting that stronger pretrained models do not always benefit from additional domain adaptation. In addition, Mine-JEPA with a compact ViT-Tiny backbone achieves competitive performance while using 4x fewer parameters than DINOv3. These results suggest that carefully designed in-domain self-supervised learning is a viable alternative to much larger foundation models in data-scarce maritime sonar imagery.
ZeSTA: Zero-Shot TTS Augmentation with Domain-Conditioned Training for Data-Efficient Personalized Speech Synthesis
Mar 04, 2026We investigate the use of zero-shot text-to-speech (ZS-TTS) as a data augmentation source for low-resource personalized speech synthesis. While synthetic augmentation can provide linguistically rich and phonetically diverse speech, naively mixing large amounts of synthetic speech with limited real recordings often leads to speaker similarity degradation during fine-tuning. To address this issue, we propose ZeSTA, a simple domain-conditioned training framework that distinguishes real and synthetic speech via a lightweight domain embedding, combined with real-data oversampling to stabilize adaptation under extremely limited target data, without modifying the base architecture. Experiments on LibriTTS and an in-house dataset with two ZS-TTS sources demonstrate that our approach improves speaker similarity over naive synthetic augmentation while preserving intelligibility and perceptual quality.
Exploring Fine-Tuning of Large Audio Language Models for Spoken Language Understanding under Limited Speech data
Sep 18, 2025Large Audio Language Models (LALMs) have emerged as powerful tools for speech-related tasks but remain underexplored for fine-tuning, especially with limited speech data. To bridge this gap, we systematically examine how different fine-tuning schemes including text-only, direct mixing, and curriculum learning affect spoken language understanding (SLU), focusing on scenarios where text-label pairs are abundant while paired speech-label data are limited. Results show that LALMs already achieve competitive performance with text-only fine-tuning, highlighting their strong generalization ability. Adding even small amounts of speech data (2-5%) yields substantial further gains, with curriculum learning particularly effective under scarce data. In cross-lingual SLU, combining source-language speech data with target-language text and minimal target-language speech data enables effective adaptation. Overall, this study provides practical insights into the LALM fine-tuning under realistic data constraints.
Generating Realistic Images from In-the-wild Sounds
Sep 05, 2023



Representing wild sounds as images is an important but challenging task due to the lack of paired datasets between sound and images and the significant differences in the characteristics of these two modalities. Previous studies have focused on generating images from sound in limited categories or music. In this paper, we propose a novel approach to generate images from in-the-wild sounds. First, we convert sound into text using audio captioning. Second, we propose audio attention and sentence attention to represent the rich characteristics of sound and visualize the sound. Lastly, we propose a direct sound optimization with CLIPscore and AudioCLIP and generate images with a diffusion-based model. In experiments, it shows that our model is able to generate high quality images from wild sounds and outperforms baselines in both quantitative and qualitative evaluations on wild audio datasets.
Technical Report for CVPR 2022 LOVEU AQTC Challenge
Jun 29, 2022

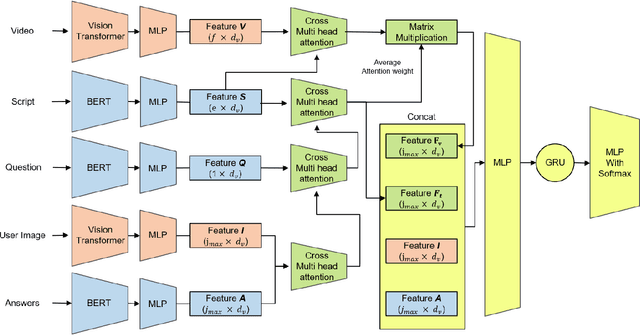
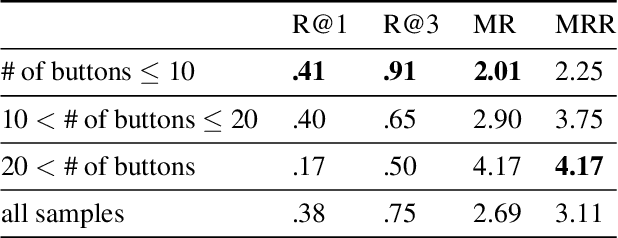
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.