 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVHighlights: Towards Extremely Long Sport Video Highlight Detection
Jun 05, 2026While highlight detection for long-form videos is of great practical importance, most existing methods remain limited to short-form content, largely due to the absence of a suitable benchmark. To bridge this gap, we introduce SVHighlights, to the best of our knowledge, the first benchmark for highlight detection in extremely long sports videos, each exceeding one hour in duration, across multiple sports categories. SVHighlights is constructed from pairs of full-length sports videos and their corresponding official highlight videos using a dataset generation pipeline, enabling scalable label generation without conventional per-clip saliency annotation. The benchmark comprises 320 videos with an average duration of 2.00 hours and a total of 640.18 hours, substantially exceeding previous datasets. Existing methods also face fundamental challenges on long videos: models trained on short clips fail to generalize to hour-long content, and their clip-level scoring lacks the broader context needed to identify highlights. To address this and provide a strong baseline, we present TF-SELECTOR, a training-free segment-based approach that divides each video into context-aware segments by merging adjacent shots sharing the same semantic content, and predicts segment-level saliency scores using a large language model with multimodal inputs including visual captions, transcripts, and audio volume. Experiments demonstrate that TF-SELECTOR achieves superior performance across most metrics compared to Video Temporal Grounding (VTG)-tuned baselines, with improvements of +3.12 in HIT@1, +4.06 in HIT@K, and +2.95 in IoU. These results establish SVHighlights as a challenging testbed for long-form highlight detection and demonstrate that a simple segment-based strategy can effectively scale to hour-long videos.
Generating Realistic Images from In-the-wild Sounds
Sep 05, 2023



Representing wild sounds as images is an important but challenging task due to the lack of paired datasets between sound and images and the significant differences in the characteristics of these two modalities. Previous studies have focused on generating images from sound in limited categories or music. In this paper, we propose a novel approach to generate images from in-the-wild sounds. First, we convert sound into text using audio captioning. Second, we propose audio attention and sentence attention to represent the rich characteristics of sound and visualize the sound. Lastly, we propose a direct sound optimization with CLIPscore and AudioCLIP and generate images with a diffusion-based model. In experiments, it shows that our model is able to generate high quality images from wild sounds and outperforms baselines in both quantitative and qualitative evaluations on wild audio datasets.
Technical Report for CVPR 2022 LOVEU AQTC Challenge
Jun 29, 2022

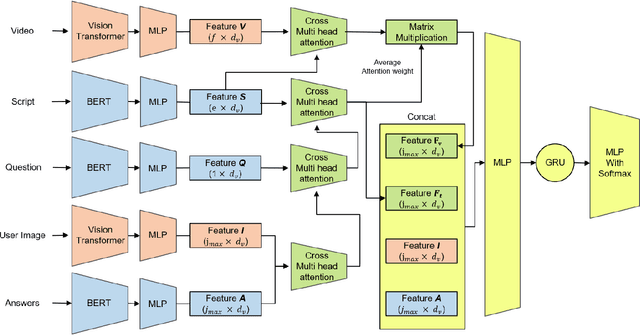
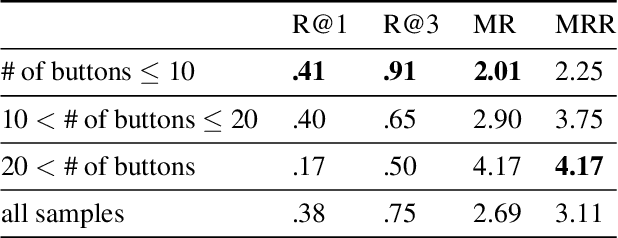
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.