 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Score: Evaluating Generative Models and Individual Generated Images based on Complexity and Vulnerability
Dec 17, 2023With the advancement of generative models, the assessment of generated images becomes more and more important. Previous methods measure distances between features of reference and generated images from trained vision models. In this paper, we conduct an extensive investigation into the relationship between the representation space and input space around generated images. We first propose two measures related to the presence of unnatural elements within images: complexity, which indicates how non-linear the representation space is, and vulnerability, which is related to how easily the extracted feature changes by adversarial input changes. Based on these, we introduce a new metric to evaluating image-generative models called anomaly score (AS). Moreover, we propose AS-i (anomaly score for individual images) that can effectively evaluate generated images individually. Experimental results demonstrate the validity of the proposed approach.
ViPLO: Vision Transformer based Pose-Conditioned Self-Loop Graph for Human-Object Interaction Detection
Apr 17, 2023



Human-Object Interaction (HOI) detection, which localizes and infers relationships between human and objects, plays an important role in scene understanding. Although two-stage HOI detectors have advantages of high efficiency in training and inference, they suffer from lower performance than one-stage methods due to the old backbone networks and the lack of considerations for the HOI perception process of humans in the interaction classifiers. In this paper, we propose Vision Transformer based Pose-Conditioned Self-Loop Graph (ViPLO) to resolve these problems. First, we propose a novel feature extraction method suitable for the Vision Transformer backbone, called masking with overlapped area (MOA) module. The MOA module utilizes the overlapped area between each patch and the given region in the attention function, which addresses the quantization problem when using the Vision Transformer backbone. In addition, we design a graph with a pose-conditioned self-loop structure, which updates the human node encoding with local features of human joints. This allows the classifier to focus on specific human joints to effectively identify the type of interaction, which is motivated by the human perception process for HOI. As a result, ViPLO achieves the state-of-the-art results on two public benchmarks, especially obtaining a +2.07 mAP performance gain on the HICO-DET dataset. The source codes are available at https://github.com/Jeeseung-Park/ViPLO.
Similarity of Neural Architectures Based on Input Gradient Transferability
Oct 20, 2022
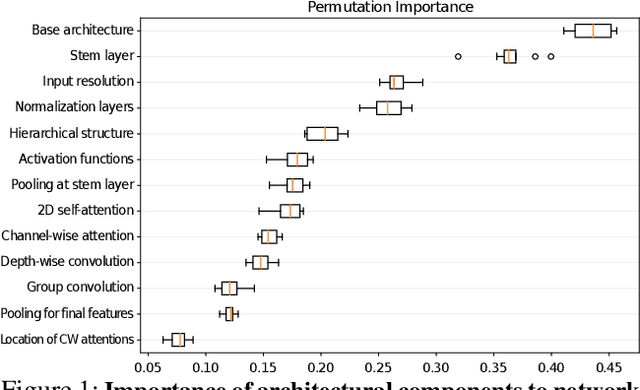
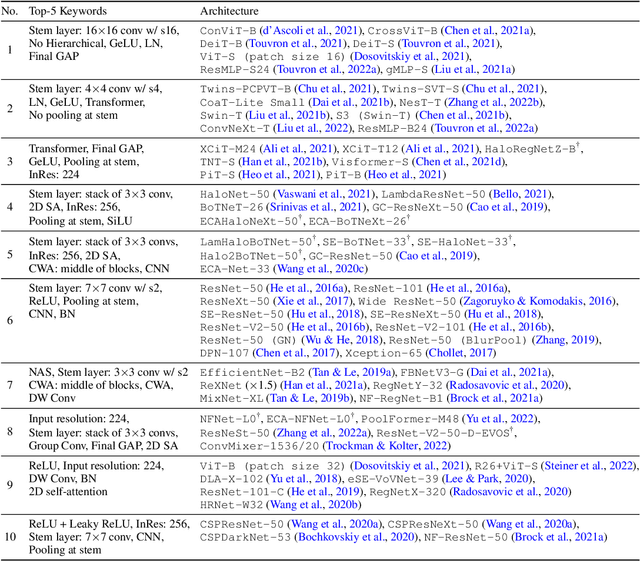
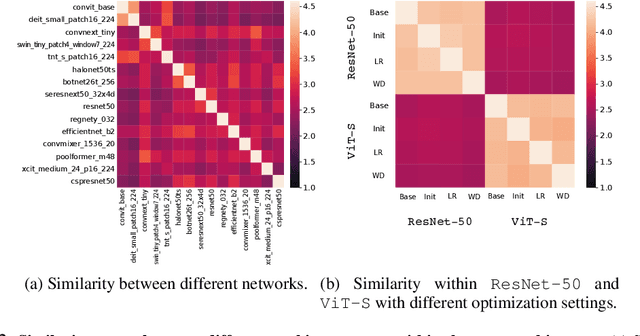
In this paper, we aim to design a quantitative similarity function between two neural architectures. Specifically, we define a model similarity using input gradient transferability. We generate adversarial samples of two networks and measure the average accuracy of the networks on adversarial samples of each other. If two networks are highly correlated, then the attack transferability will be high, resulting in high similarity. Using the similarity score, we investigate two topics: (1) Which network component contributes to the model diversity? (2) How does model diversity affect practical scenarios? We answer the first question by providing feature importance analysis and clustering analysis. The second question is validated by two different scenarios: model ensemble and knowledge distillation. Our findings show that model diversity takes a key role when interacting with different neural architectures. For example, we found that more diversity leads to better ensemble performance. We also observe that the relationship between teacher and student networks and distillation performance depends on the choice of the base architecture of the teacher and student networks. We expect our analysis tool helps a high-level understanding of differences between various neural architectures as well as practical guidance when using multiple architectures.
Curved Representation Space of Vision Transformers
Oct 11, 2022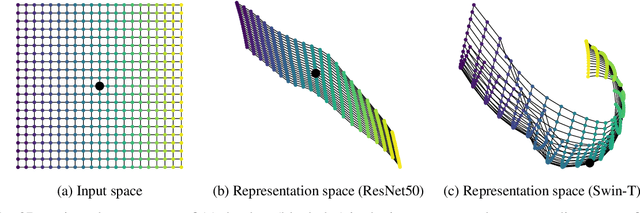
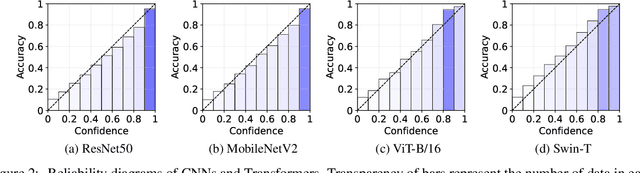
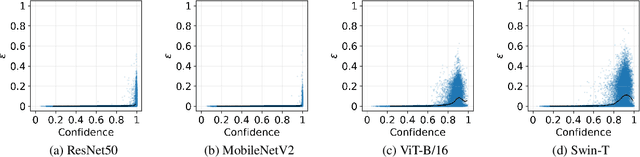
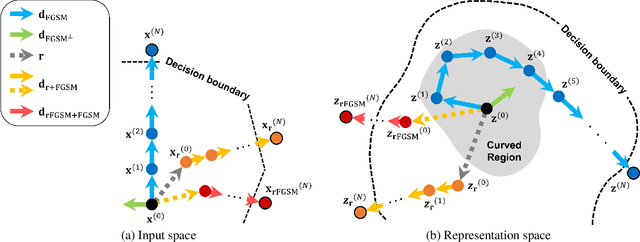
Neural networks with self-attention (a.k.a. Transformers) like ViT and Swin have emerged as a better alternative to traditional convolutional neural networks (CNNs) for computer vision tasks. However, our understanding of how the new architecture works is still limited. In this paper, we focus on the phenomenon that Transformers show higher robustness against corruptions than CNNs, while not being overconfident (in fact, we find Transformers are actually underconfident). This is contrary to the intuition that robustness increases with confidence. We resolve this contradiction by investigating how the output of the penultimate layer moves in the representation space as the input data moves within a small area. In particular, we show the following. (1) While CNNs exhibit fairly linear relationship between the input and output movements, Transformers show nonlinear relationship for some data. For those data, the output of Transformers moves in a curved trajectory as the input moves linearly. (2) When a data is located in a curved region, it is hard to move it out of the decision region since the output moves along a curved trajectory instead of a straight line to the decision boundary, resulting in high robustness of Transformers. (3) If a data is slightly modified to jump out of the curved region, the movements afterwards become linear and the output goes to the decision boundary directly. Thus, Transformers can be attacked easily after a small random jump and the perturbation in the final attacked data remains imperceptible, i.e., there does exist a decision boundary near the data. This also explains the underconfident prediction of Transformers. (4) The curved regions in the representation space start to form at an early training stage and grow throughout the training course. Some data are trapped in the regions, obstructing Transformers from reducing the training loss.
Modeling, Quantifying, and Predicting Subjectivity of Image Aesthetics
Aug 20, 2022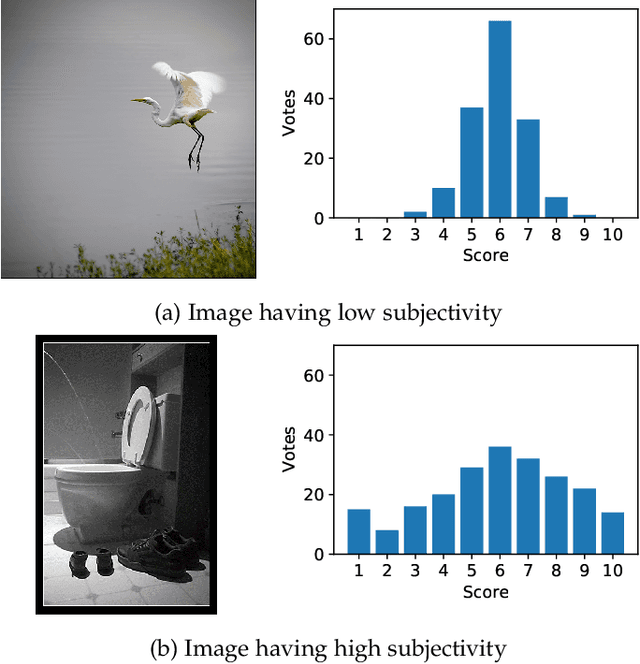
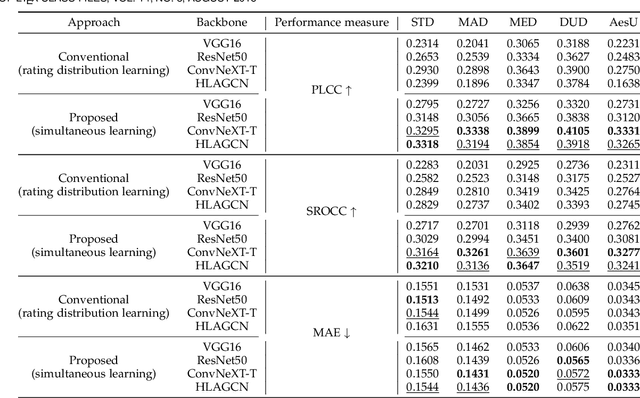
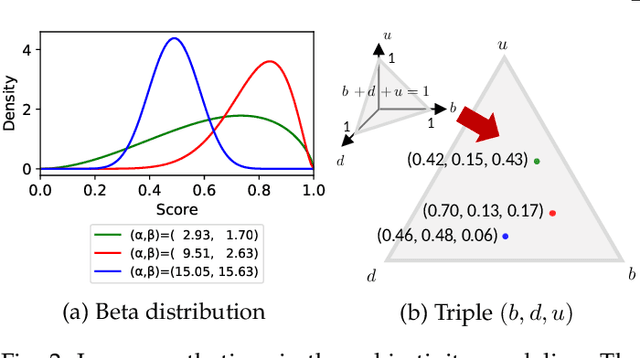
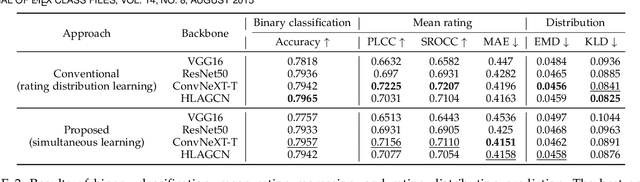
Assessing image aesthetics is a challenging computer vision task. One reason is that aesthetic preference is highly subjective and may vary significantly among people for certain images. Thus, it is important to properly model and quantify such \textit{subjectivity}, but there has not been much effort to resolve this issue. In this paper, we propose a novel unified probabilistic framework that can model and quantify subjective aesthetic preference based on the subjective logic. In this framework, the rating distribution is modeled as a beta distribution, from which the probabilities of being definitely pleasing, being definitely unpleasing, and being uncertain can be obtained. We use the probability of being uncertain to define an intuitive metric of subjectivity. Furthermore, we present a method to learn deep neural networks for prediction of image aesthetics, which is shown to be effective in improving the performance of subjectivity prediction via experiments. We also present an application scenario where the framework is beneficial for aesthetics-based image recommendation.
Analyzing Adversarial Robustness of Vision Transformers against Spatial and Spectral Attacks
Aug 20, 2022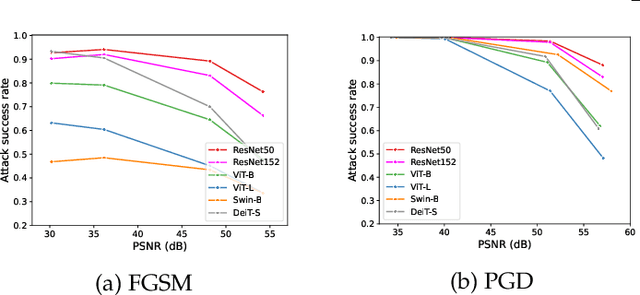
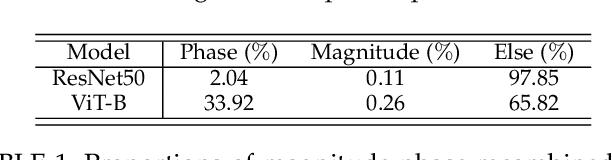
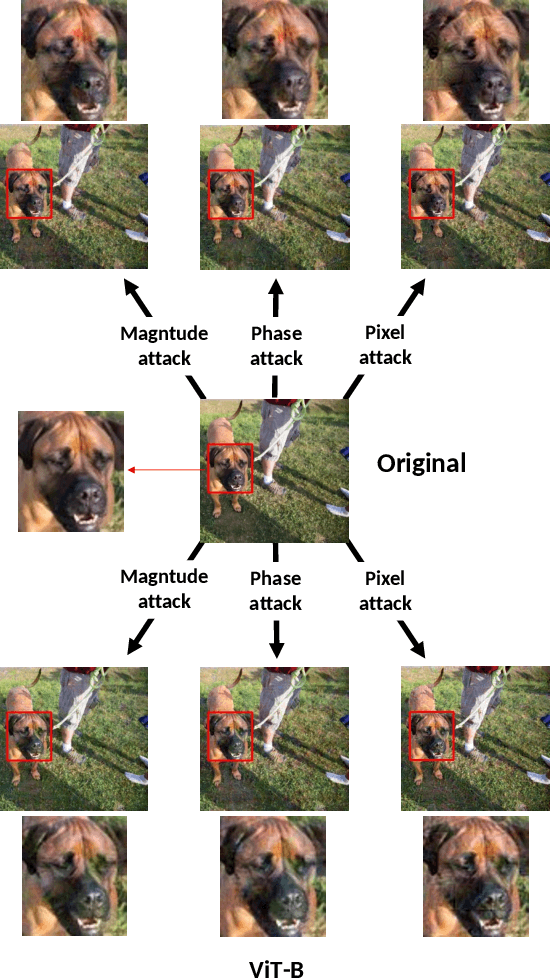
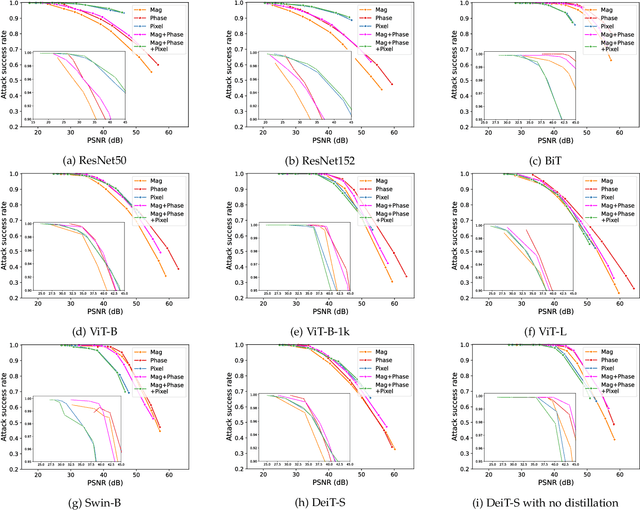
Vision Transformers have emerged as a powerful architecture that can outperform convolutional neural networks (CNNs) in image classification tasks. Several attempts have been made to understand robustness of Transformers against adversarial attacks, but existing studies draw inconsistent results, i.e., some conclude that Transformers are more robust than CNNs, while some others find that they have similar degrees of robustness. In this paper, we address two issues unexplored in the existing studies examining adversarial robustness of Transformers. First, we argue that the image quality should be simultaneously considered in evaluating adversarial robustness. We find that the superiority of one architecture to another in terms of robustness can change depending on the attack strength expressed by the quality of the attacked images. Second, by noting that Transformers and CNNs rely on different types of information in images, we formulate an attack framework, called Fourier attack, as a tool for implementing flexible attacks, where an image can be attacked in the spectral domain as well as in the spatial domain. This attack perturbs the magnitude and phase information of particular frequency components selectively. Through extensive experiments, we find that Transformers tend to rely more on phase information and low frequency information than CNNs, and thus sometimes they are even more vulnerable under frequency-selective attacks. It is our hope that this work provides new perspectives in understanding the properties and adversarial robustness of Transformers.
Demystifying Randomly Initialized Networks for Evaluating Generative Models
Aug 19, 2022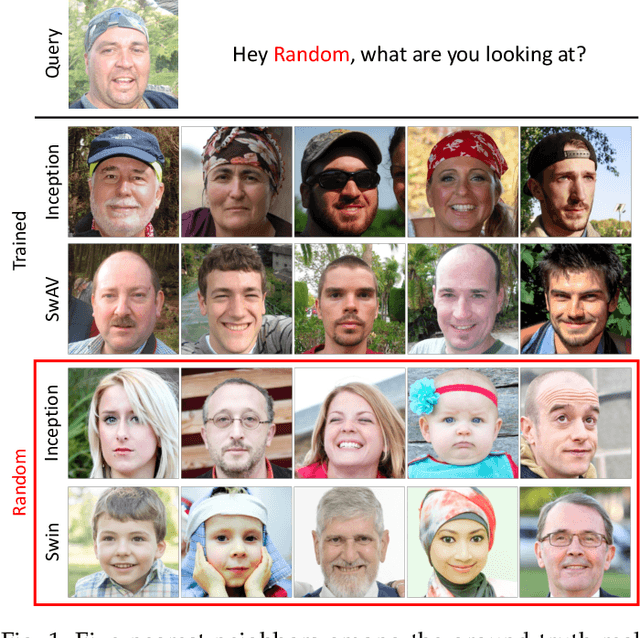
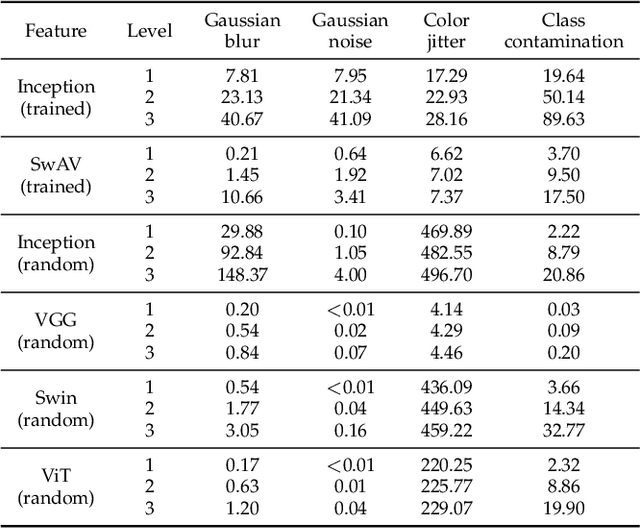

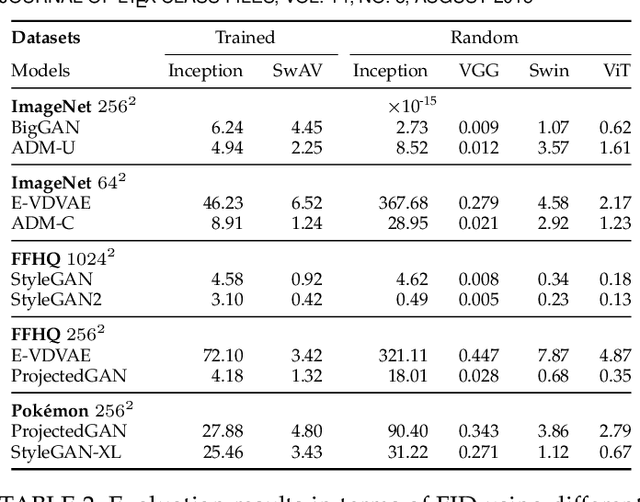
Evaluation of generative models is mostly based on the comparison between the estimated distribution and the ground truth distribution in a certain feature space. To embed samples into informative features, previous works often use convolutional neural networks optimized for classification, which is criticized by recent studies. Therefore, various feature spaces have been explored to discover alternatives. Among them, a surprising approach is to use a randomly initialized neural network for feature embedding. However, the fundamental basis to employ the random features has not been sufficiently justified. In this paper, we rigorously investigate the feature space of models with random weights in comparison to that of trained models. Furthermore, we provide an empirical evidence to choose networks for random features to obtain consistent and reliable results. Our results indicate that the features from random networks can evaluate generative models well similarly to those from trained networks, and furthermore, the two types of features can be used together in a complementary way.
Temporal Shuffling for Defending Deep Action Recognition Models against Adversarial Attacks
Dec 15, 2021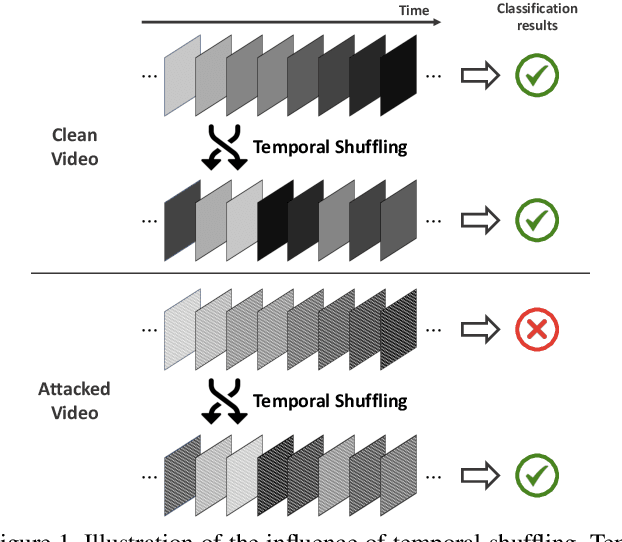
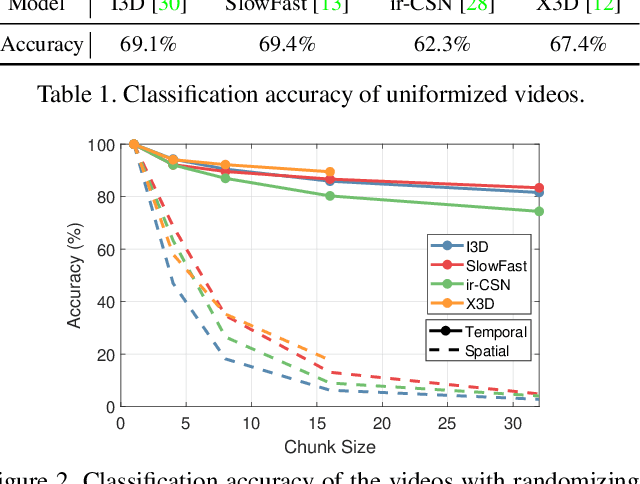
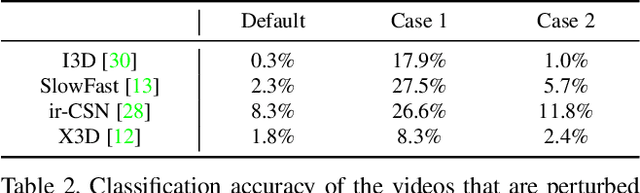

Recently, video-based action recognition methods using convolutional neural networks (CNNs) achieve remarkable recognition performance. However, there is still lack of understanding about the generalization mechanism of action recognition models. In this paper, we suggest that action recognition models rely on the motion information less than expected, and thus they are robust to randomization of frame orders. Based on this observation, we develop a novel defense method using temporal shuffling of input videos against adversarial attacks for action recognition models. Another observation enabling our defense method is that adversarial perturbations on videos are sensitive to temporal destruction. To the best of our knowledge, this is the first attempt to design a defense method specific to video-based action recognition models.
Amicable Aid: Turning Adversarial Attack to Benefit Classification
Dec 09, 2021
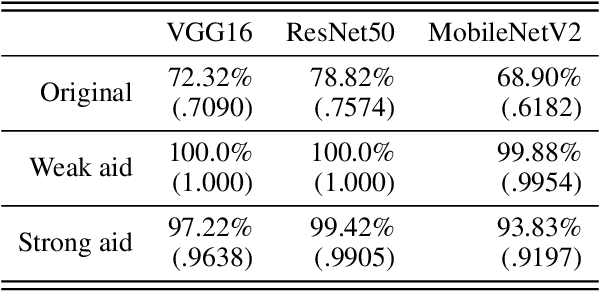
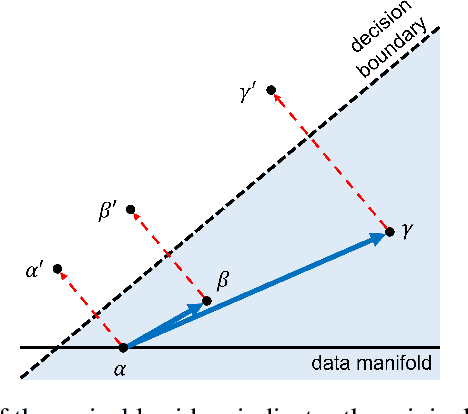
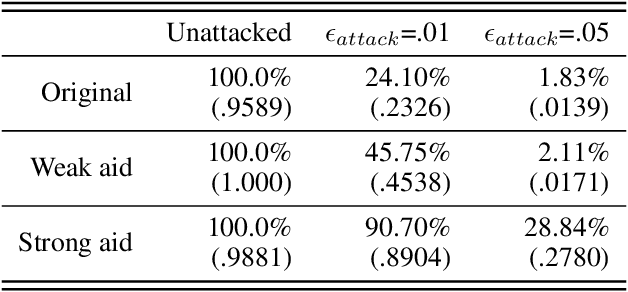
While adversarial attacks on deep image classification models pose serious security concerns in practice, this paper suggests a novel paradigm where the concept of adversarial attacks can benefit classification performance, which we call amicable aid. We show that by taking the opposite search direction of perturbation, an image can be converted to another yielding higher confidence by the classification model and even a wrongly classified image can be made to be correctly classified. Furthermore, with a large amount of perturbation, an image can be made unrecognizable by human eyes, while it is correctly recognized by the model. The mechanism of the amicable aid is explained in the viewpoint of the underlying natural image manifold. We also consider universal amicable perturbations, i.e., a fixed perturbation can be applied to multiple images to improve their classification results. While it is challenging to find such perturbations, we show that making the decision boundary as perpendicular to the image manifold as possible via training with modified data is effective to obtain a model for which universal amicable perturbations are more easily found. Finally, we discuss several application scenarios where the amicable aid can be useful, including secure image communication, privacy-preserving image communication, and protection against adversarial attacks.
Joint Global and Local Hierarchical Priors for Learned Image Compression
Dec 08, 2021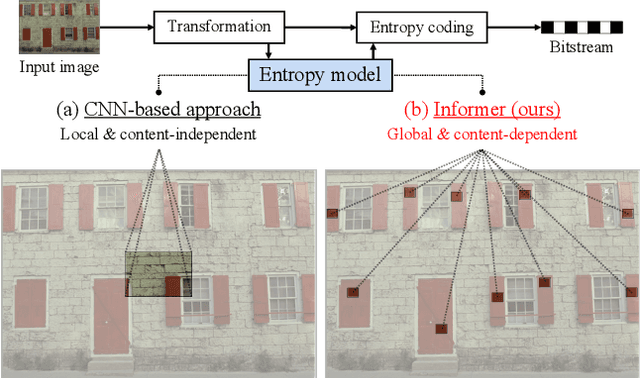


Recently, learned image compression methods have shown superior performance compared to the traditional hand-crafted image codecs including BPG. One of the fundamental research directions in learned image compression is to develop entropy models that accurately estimate the probability distribution of the quantized latent representation. Like other vision tasks, most of the recent learned entropy models are based on convolutional neural networks (CNNs). However, CNNs have a limitation in modeling dependencies between distant regions due to their nature of local connectivity, which can be a significant bottleneck in image compression where reducing spatial redundancy is a key point. To address this issue, we propose a novel entropy model called Information Transformer (Informer) that exploits both local and global information in a content-dependent manner using an attention mechanism. Our experiments demonstrate that Informer improves rate-distortion performance over the state-of-the-art methods on the Kodak and Tecnick datasets without the quadratic computational complexity problem.