 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Integrity when Unlearning with T2I Diffusion Models
Nov 04, 2024


The rapid advancement of text-to-image Diffusion Models has led to their widespread public accessibility. However these models, trained on large internet datasets, can sometimes generate undesirable outputs. To mitigate this, approximate Machine Unlearning algorithms have been proposed to modify model weights to reduce the generation of specific types of images, characterized by samples from a ``forget distribution'', while preserving the model's ability to generate other images, characterized by samples from a ``retain distribution''. While these methods aim to minimize the influence of training data in the forget distribution without extensive additional computation, we point out that they can compromise the model's integrity by inadvertently affecting generation for images in the retain distribution. Recognizing the limitations of FID and CLIPScore in capturing these effects, we introduce a novel retention metric that directly assesses the perceptual difference between outputs generated by the original and the unlearned models. We then propose unlearning algorithms that demonstrate superior effectiveness in preserving model integrity compared to existing baselines. Given their straightforward implementation, these algorithms serve as valuable benchmarks for future advancements in approximate Machine Unlearning for Diffusion Models.
Simpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion
Oct 25, 2024



Latent diffusion models have become the popular choice for scaling up diffusion models for high resolution image synthesis. Compared to pixel-space models that are trained end-to-end, latent models are perceived to be more efficient and to produce higher image quality at high resolution. Here we challenge these notions, and show that pixel-space models can in fact be very competitive to latent approaches both in quality and efficiency, achieving 1.5 FID on ImageNet512 and new SOTA results on ImageNet128 and ImageNet256. We present a simple recipe for scaling end-to-end pixel-space diffusion models to high resolutions. 1: Use the sigmoid loss (Kingma & Gao, 2023) with our prescribed hyper-parameters. 2: Use our simplified memory-efficient architecture with fewer skip-connections. 3: Scale the model to favor processing the image at high resolution with fewer parameters, rather than using more parameters but at a lower resolution. When combining these three steps with recently proposed tricks like guidance intervals, we obtain a family of pixel-space diffusion models we call Simple Diffusion v2 (SiD2).
Multistep Distillation of Diffusion Models via Moment Matching
Jun 06, 2024We present a new method for making diffusion models faster to sample. The method distills many-step diffusion models into few-step models by matching conditional expectations of the clean data given noisy data along the sampling trajectory. Our approach extends recently proposed one-step methods to the multi-step case, and provides a new perspective by interpreting these approaches in terms of moment matching. By using up to 8 sampling steps, we obtain distilled models that outperform not only their one-step versions but also their original many-step teacher models, obtaining new state-of-the-art results on the Imagenet dataset. We also show promising results on a large text-to-image model where we achieve fast generation of high resolution images directly in image space, without needing autoencoders or upsamplers.
Multistep Consistency Models
Mar 11, 2024



Diffusion models are relatively easy to train but require many steps to generate samples. Consistency models are far more difficult to train, but generate samples in a single step. In this paper we propose Multistep Consistency Models: A unification between Consistency Models (Song et al., 2023) and TRACT (Berthelot et al., 2023) that can interpolate between a consistency model and a diffusion model: a trade-off between sampling speed and sampling quality. Specifically, a 1-step consistency model is a conventional consistency model whereas we show that a $\infty$-step consistency model is a diffusion model. Multistep Consistency Models work really well in practice. By increasing the sample budget from a single step to 2-8 steps, we can train models more easily that generate higher quality samples, while retaining much of the sampling speed benefits. Notable results are 1.4 FID on Imagenet 64 in 8 step and 2.1 FID on Imagenet128 in 8 steps with consistency distillation. We also show that our method scales to a text-to-image diffusion model, generating samples that are very close to the quality of the original model.
Rolling Diffusion Models
Feb 12, 2024



Diffusion models have recently been increasingly applied to temporal data such as video, fluid mechanics simulations, or climate data. These methods generally treat subsequent frames equally regarding the amount of noise in the diffusion process. This paper explores Rolling Diffusion: a new approach that uses a sliding window denoising process. It ensures that the diffusion process progressively corrupts through time by assigning more noise to frames that appear later in a sequence, reflecting greater uncertainty about the future as the generation process unfolds. Empirically, we show that when the temporal dynamics are complex, Rolling Diffusion is superior to standard diffusion. In particular, this result is demonstrated in a video prediction task using the Kinetics-600 video dataset and in a chaotic fluid dynamics forecasting experiment.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023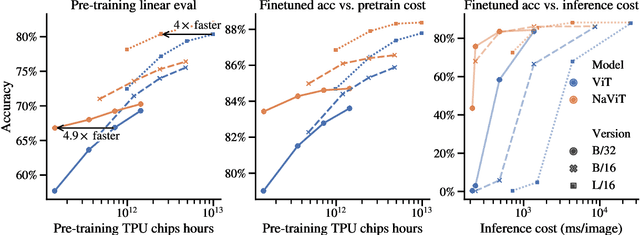
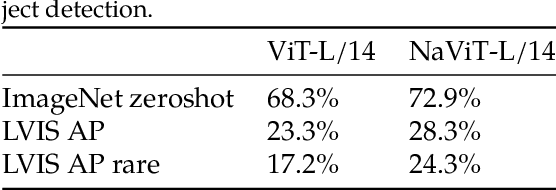
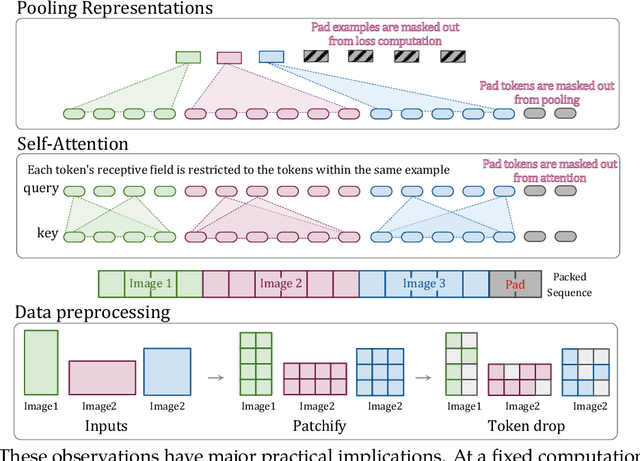
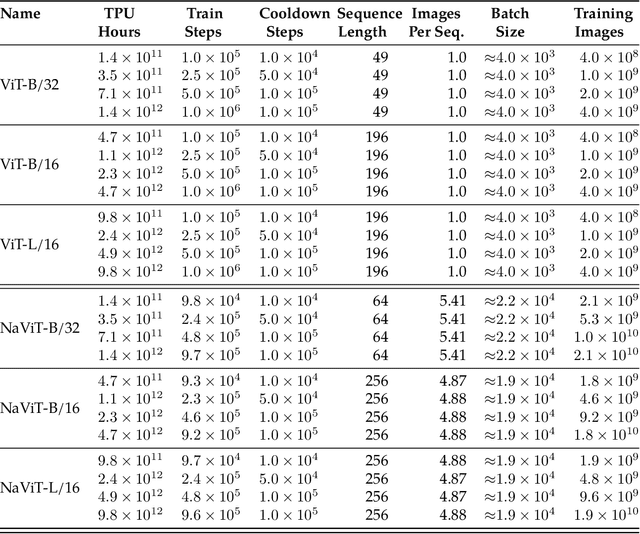
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
Robustmix: Improving Robustness by Regularizing the Frequency Bias of Deep Nets
Apr 06, 2023Deep networks have achieved impressive results on a range of well-curated benchmark datasets. Surprisingly, their performance remains sensitive to perturbations that have little effect on human performance. In this work, we propose a novel extension of Mixup called Robustmix that regularizes networks to classify based on lower-frequency spatial features. We show that this type of regularization improves robustness on a range of benchmarks such as Imagenet-C and Stylized Imagenet. It adds little computational overhead and, furthermore, does not require a priori knowledge of a large set of image transformations. We find that this approach further complements recent advances in model architecture and data augmentation, attaining a state-of-the-art mCE of 44.8 with an EfficientNet-B8 model and RandAugment, which is a reduction of 16 mCE compared to the baseline.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
simple diffusion: End-to-end diffusion for high resolution images
Jan 26, 2023



Currently, applying diffusion models in pixel space of high resolution images is difficult. Instead, existing approaches focus on diffusion in lower dimensional spaces (latent diffusion), or have multiple super-resolution levels of generation referred to as cascades. The downside is that these approaches add additional complexity to the diffusion framework. This paper aims to improve denoising diffusion for high resolution images while keeping the model as simple as possible. The paper is centered around the research question: How can one train a standard denoising diffusion models on high resolution images, and still obtain performance comparable to these alternate approaches? The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2) It is sufficient to scale only a particular part of the architecture, 3) dropout should be added at specific locations in the architecture, and 4) downsampling is an effective strategy to avoid high resolution feature maps. Combining these simple yet effective techniques, we achieve state-of-the-art on image generation among diffusion models without sampling modifiers on ImageNet.
Efficiently Scaling Transformer Inference
Nov 09, 2022



We study the problem of efficient generative inference for Transformer models, in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Better understanding of the engineering tradeoffs for inference for large Transformer-based models is important as use cases of these models are growing rapidly throughout application areas. We develop a simple analytical model for inference efficiency to select the best multi-dimensional partitioning techniques optimized for TPU v4 slices based on the application requirements. We combine these with a suite of low-level optimizations to achieve a new Pareto frontier on the latency and model FLOPS utilization (MFU) tradeoffs on 500B+ parameter models that outperforms the FasterTransformer suite of benchmarks. We further show that with appropriate partitioning, the lower memory requirements of multiquery attention (i.e. multiple query heads share single key/value head) enables scaling up to 32x larger context lengths. Finally, we achieve a low-batch-size latency of 29ms per token during generation (using int8 weight quantization) and a 76% MFU during large-batch-size processing of input tokens, while supporting a long 2048-token context length on the PaLM 540B parameter model.