 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
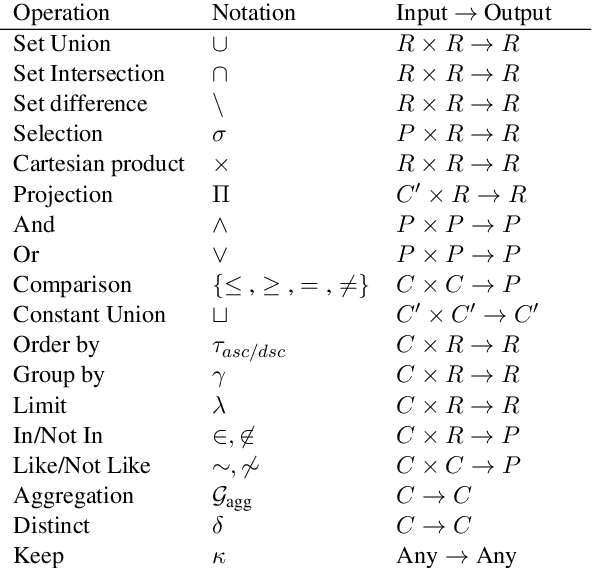
Add to EdgeValue-aware Approximate Attention
Mar 17, 2021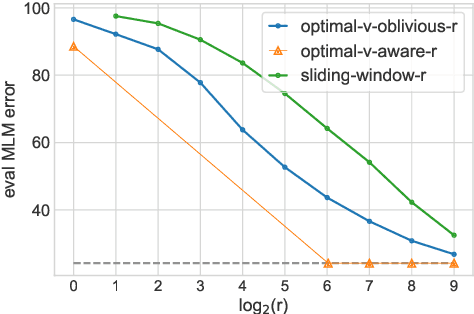

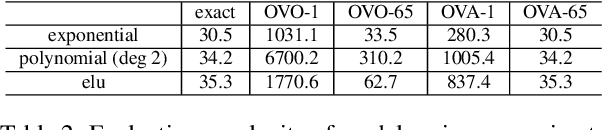
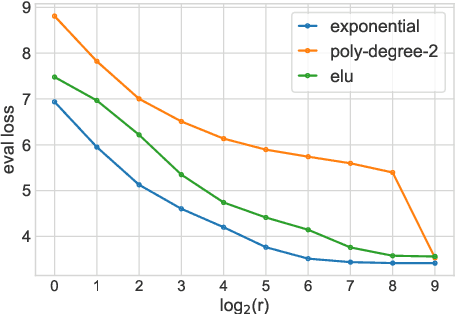
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. However, all approximations thus far have ignored the contribution of the $\textit{value vectors}$ to the quality of approximation. In this work, we argue that research efforts should be directed towards approximating the true output of the attention sub-layer, which includes the value vectors. We propose a value-aware objective, and show theoretically and empirically that an optimal approximation of a value-aware objective substantially outperforms an optimal approximation that ignores values, in the context of language modeling. Moreover, we show that the choice of kernel function for computing attention similarity can substantially affect the quality of sparse approximations, where kernel functions that are less skewed are more affected by the value vectors.
BERTese: Learning to Speak to BERT
Mar 11, 2021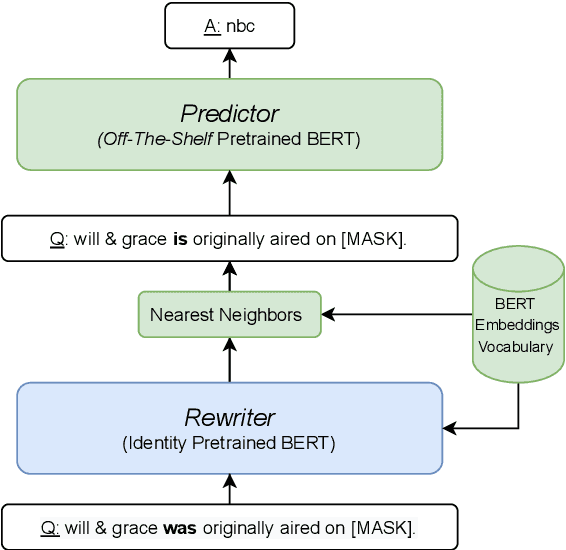



Large pre-trained language models have been shown to encode large amounts of world and commonsense knowledge in their parameters, leading to substantial interest in methods for extracting that knowledge. In past work, knowledge was extracted by taking manually-authored queries and gathering paraphrases for them using a separate pipeline. In this work, we propose a method for automatically rewriting queries into "BERTese", a paraphrase query that is directly optimized towards better knowledge extraction. To encourage meaningful rewrites, we add auxiliary loss functions that encourage the query to correspond to actual language tokens. We empirically show our approach outperforms competing baselines, obviating the need for complex pipelines. Moreover, BERTese provides some insight into the type of language that helps language models perform knowledge extraction.
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
Jan 06, 2021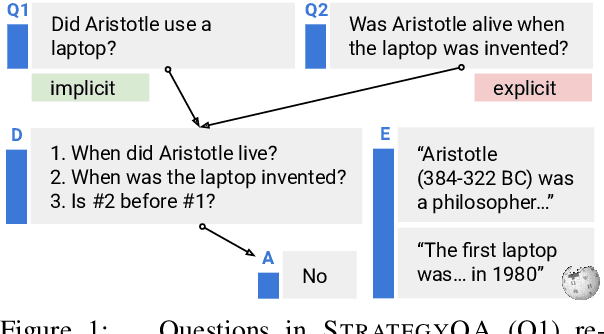

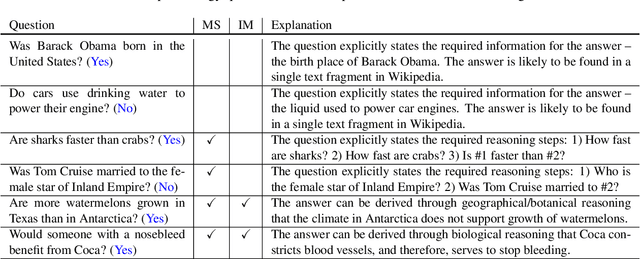

A key limitation in current datasets for multi-hop reasoning is that the required steps for answering the question are mentioned in it explicitly. In this work, we introduce StrategyQA, a question answering (QA) benchmark where the required reasoning steps are implicit in the question, and should be inferred using a strategy. A fundamental challenge in this setup is how to elicit such creative questions from crowdsourcing workers, while covering a broad range of potential strategies. We propose a data collection procedure that combines term-based priming to inspire annotators, careful control over the annotator population, and adversarial filtering for eliminating reasoning shortcuts. Moreover, we annotate each question with (1) a decomposition into reasoning steps for answering it, and (2) Wikipedia paragraphs that contain the answers to each step. Overall, StrategyQA includes 2,780 examples, each consisting of a strategy question, its decomposition, and evidence paragraphs. Analysis shows that questions in StrategyQA are short, topic-diverse, and cover a wide range of strategies. Empirically, we show that humans perform well (87%) on this task, while our best baseline reaches an accuracy of $\sim$66%.
Few-Shot Question Answering by Pretraining Span Selection
Jan 02, 2021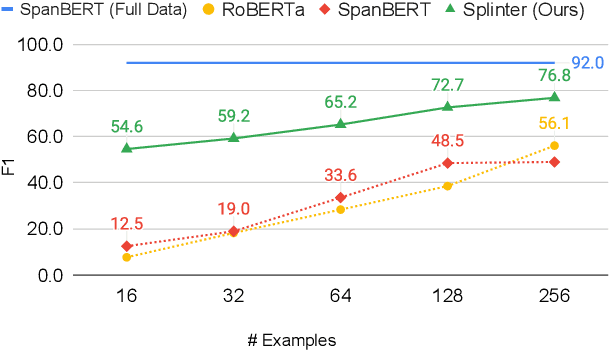
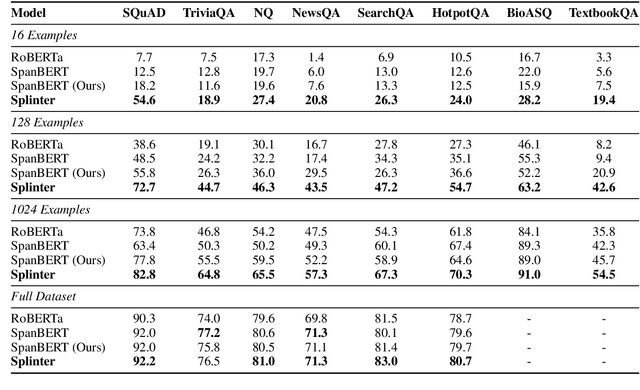

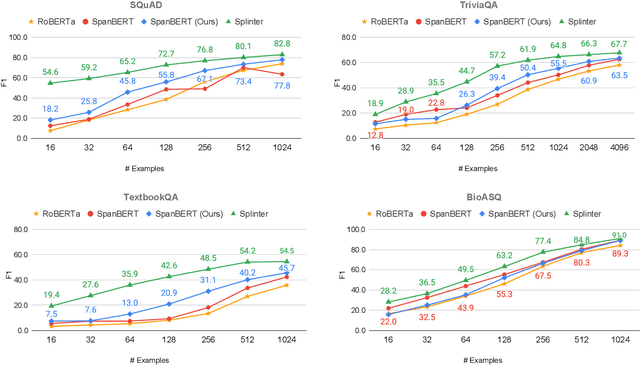
In a number of question answering (QA) benchmarks, pretrained models have reached human parity through fine-tuning on an order of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred training examples are available. We show that standard span selection models perform poorly, highlighting the fact that current pretraining objective are far removed from question answering. To address this, we propose a new pretraining scheme that is more suitable for extractive question answering. Given a passage with multiple sets of recurring spans, we mask in each set all recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select the answer span. The resulting model obtains surprisingly good results on multiple benchmarks, e.g., 72.7 F1 with only 128 examples on SQuAD, while maintaining competitive (and sometimes better) performance in the high-resource setting. Our findings indicate that careful design of pretraining schemes and model architecture can have a dramatic effect on performance in the few-shot settings.
Transformer Feed-Forward Layers Are Key-Value Memories
Dec 29, 2020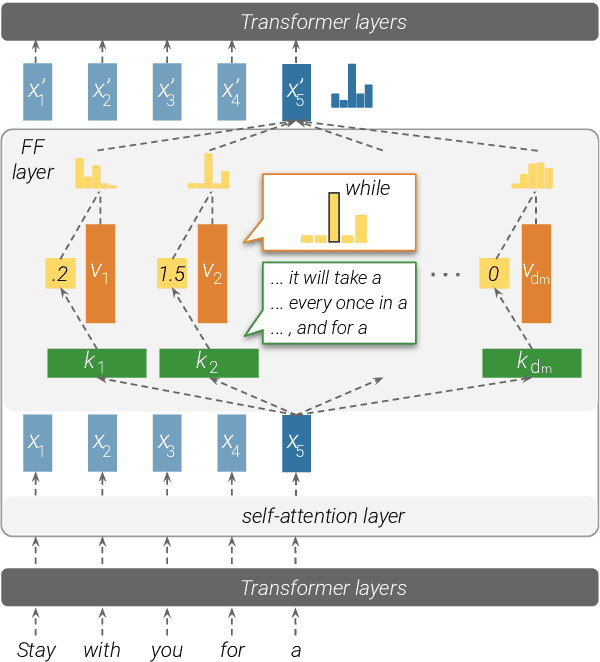

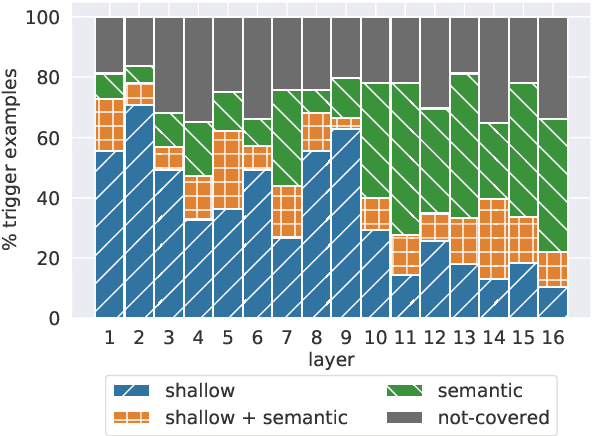

Feed-forward layers constitute two-thirds of a transformer model's parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys' input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model's layers via residual connections to produce the final output distribution.
SmBoP: Semi-autoregressive Bottom-up Semantic Parsing
Oct 23, 2020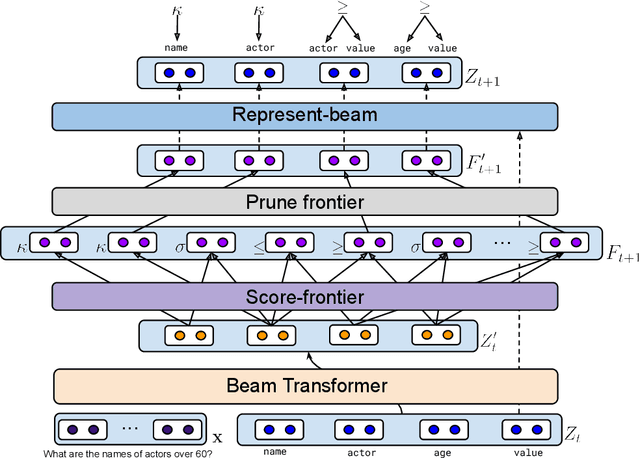
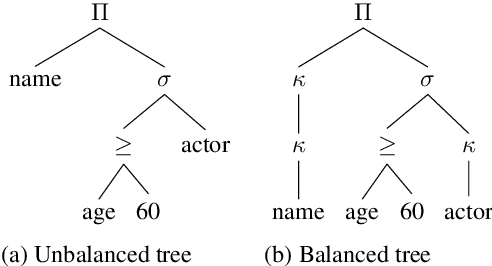

The de-facto standard decoding method for semantic parsing in recent years has been to autoregressively decode the abstract syntax tree of the target program using a top-down depth-first traversal. In this work, we propose an alternative approach: a Semi-autoregressive Bottom-up Parser (SmBoP) that constructs at decoding step $t$ the top-$K$ sub-trees of height $\leq t$. Our parser enjoys several benefits compared to top-down autoregressive parsing. First, since sub-trees in each decoding step are generated in parallel, the theoretical runtime is logarithmic rather than linear. Second, our bottom-up approach learns representations with meaningful semantic sub-programs at each step, rather than semantically vague partial trees. Last, SmBoP includes Transformer-based layers that contextualize sub-trees with one another, allowing us, unlike traditional beam-search, to score trees conditioned on other trees that have been previously explored. We apply SmBoP on Spider, a challenging zero-shot semantic parsing benchmark, and show that SmBoP is competitive with top-down autoregressive parsing. On the test set, SmBoP obtains an EM score of $60.5\%$, similar to the best published score for a model that does not use database content, which is at $60.6\%$.
Improving Compositional Generalization in Semantic Parsing
Oct 12, 2020
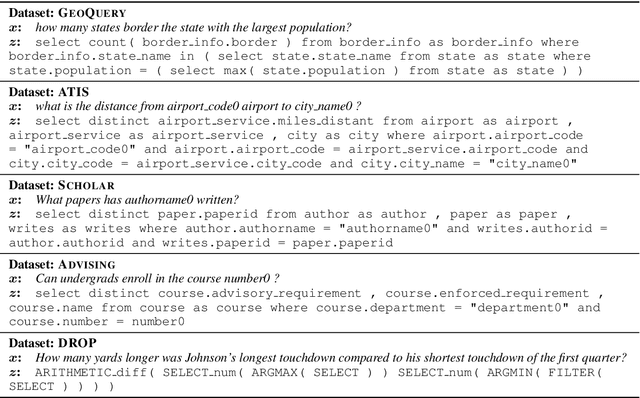

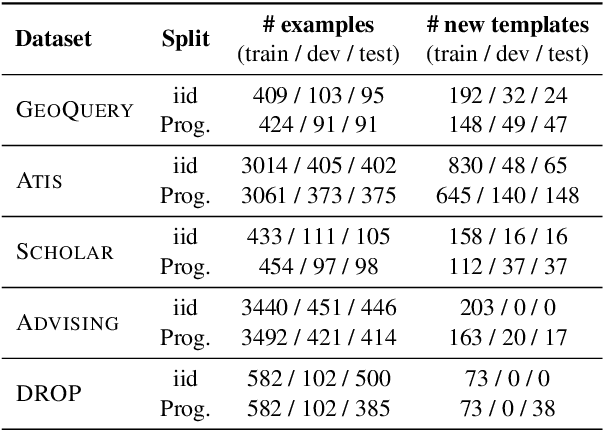
Generalization of models to out-of-distribution (OOD) data has captured tremendous attention recently. Specifically, compositional generalization, i.e., whether a model generalizes to new structures built of components observed during training, has sparked substantial interest. In this work, we investigate compositional generalization in semantic parsing, a natural test-bed for compositional generalization, as output programs are constructed from sub-components. We analyze a wide variety of models and propose multiple extensions to the attention module of the semantic parser, aiming to improve compositional generalization. We find that the following factors improve compositional generalization: (a) using contextual representations, such as ELMo and BERT, (b) informing the decoder what input tokens have previously been attended to, (c) training the decoder attention to agree with pre-computed token alignments, and (d) downsampling examples corresponding to frequent program templates. While we substantially reduce the gap between in-distribution and OOD generalization, performance on OOD compositions is still substantially lower.
Learning Object Detection from Captions via Textual Scene Attributes
Sep 30, 2020


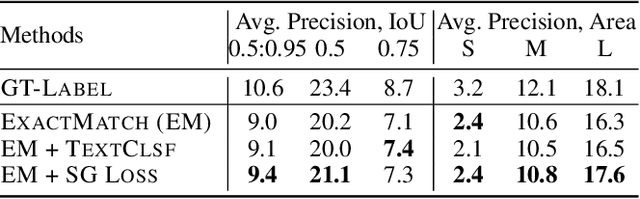
Object detection is a fundamental task in computer vision, requiring large annotated datasets that are difficult to collect, as annotators need to label objects and their bounding boxes. Thus, it is a significant challenge to use cheaper forms of supervision effectively. Recent work has begun to explore image captions as a source for weak supervision, but to date, in the context of object detection, captions have only been used to infer the categories of the objects in the image. In this work, we argue that captions contain much richer information about the image, including attributes of objects and their relations. Namely, the text represents a scene of the image, as described recently in the literature. We present a method that uses the attributes in this "textual scene graph" to train object detectors. We empirically demonstrate that the resulting model achieves state-of-the-art results on several challenging object detection datasets, outperforming recent approaches.
Scene Graph to Image Generation with Contextualized Object Layout Refinement
Sep 24, 2020

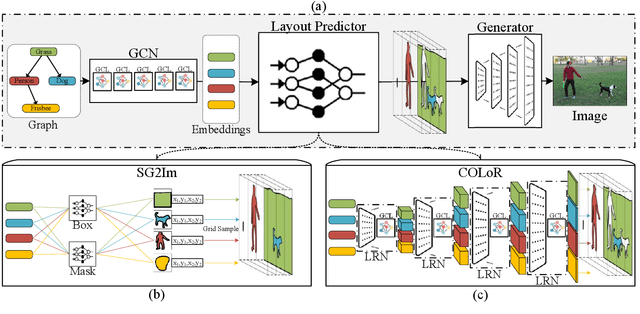
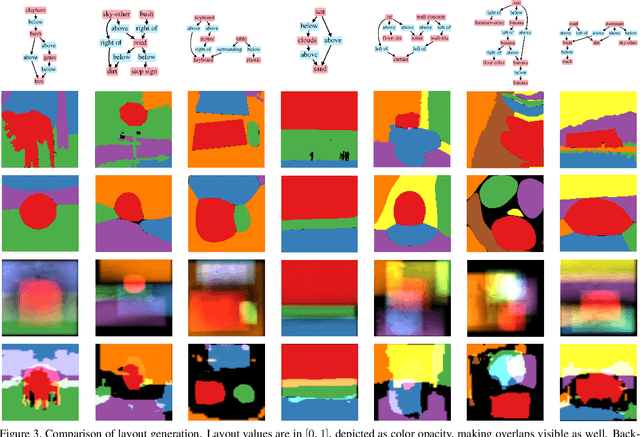
Generating high-quality images from scene graphs, that is, graphs that describe multiple entities in complex relations, is a challenging task that attracted substantial interest recently. Prior work trained such models by using supervised learning, where the goal is to produce the exact target image layout for each scene graph. It relied on predicting object locations and shapes independently and in parallel. However, scene graphs are underspecified, and thus the same scene graph often occurs with many target images in the training data. This leads to generated images with high inter-object overlap, empty areas, blurry objects, and overall compromised quality. In this work, we propose a method that alleviates these issues by generating all object layouts together and reducing the reliance on such supervision. Our model predicts layouts directly from embeddings (without predicting intermediate boxes) by gradually upsampling, refining and contextualizing object layouts. It is trained with a novel adversarial loss, that optimizes the interaction between object pairs. This improves coverage and removes overlaps, while maintaining sensible contours and respecting objects relations. We empirically show on the COCO-STUFF dataset that our proposed approach substantially improves the quality of generated layouts as well as the overall image quality. Our evaluation shows that we improve layout coverage by almost 20 points, and drop object overlap to negligible amounts. This leads to better image generation, relation fulfillment and objects quality.
Span-based Semantic Parsing for Compositional Generalization
Sep 13, 2020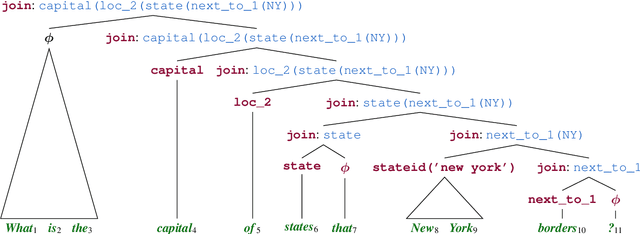
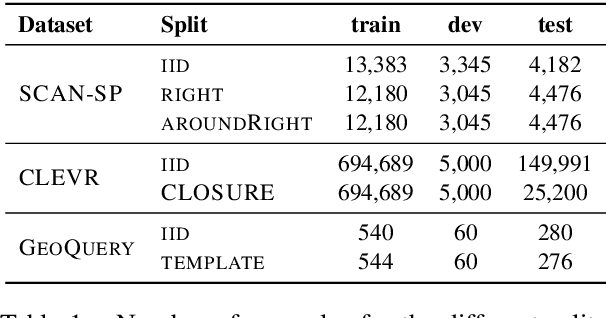

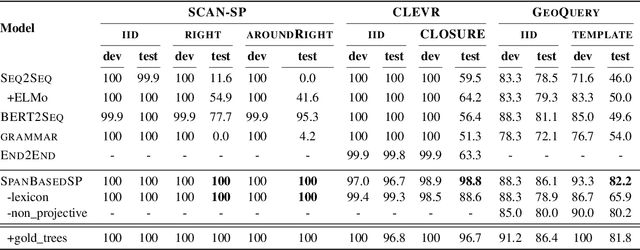
Despite the success of sequence-to-sequence (seq2seq) models in semantic parsing, recent work has shown that they fail in compositional generalization, i.e., the ability to generalize to new structures built of components observed during training. In this work, we posit that a span-based parser should lead to better compositional generalization. we propose SpanBasedSP, a parser that predicts a span tree over an input utterance, explicitly encoding how partial programs compose over spans in the input. SpanBasedSP extends Pasupat et al. (2019) to be comparable to seq2seq models by (i) training from programs, without access to gold trees, treating trees as latent variables, (ii) parsing a class of non-projective trees through an extension to standard CKY. On GeoQuery, SCAN and CLOSURE datasets, SpanBasedSP performs similarly to strong seq2seq baselines on random splits, but dramatically improves performance compared to baselines on splits that require compositional generalization: from $69.8 \rightarrow 95.3$ average accuracy.