 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfusion: Understanding Transfer Learning with Applications to Medical Imaging
Feb 14, 2019
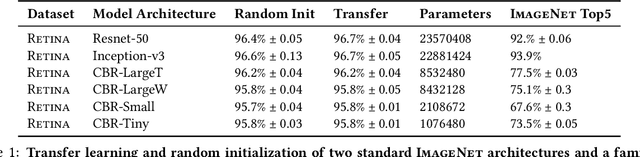
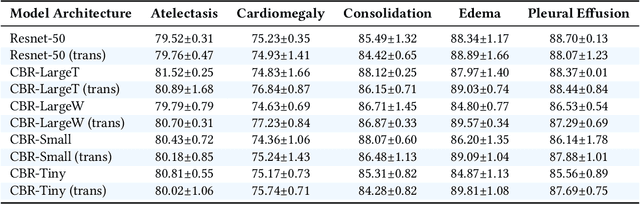
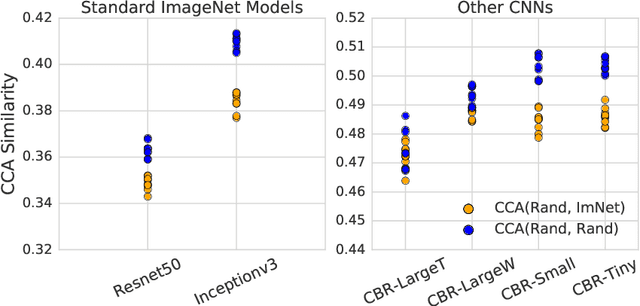
With the increasingly varied applications of deep learning, transfer learning has emerged as a critically important technique. However, the central question of how much feature reuse in transfer is the source of benefit remains unanswered. In this paper, we present an in-depth analysis of the effects of transfer, focusing on medical imaging, which is a particularly intriguing setting. Here, transfer learning is extremely popular, but data differences between pretraining and finetuing are considerable, reiterating the question of what is transferred. With experiments on two large scale medical imaging datasets, and CIFAR-10, we find transfer has almost negligible effects on performance, but significantly helps convergence speed. However, in all of these settings, convergence without transfer can be sped up dramatically by using only mean and variance statistics of the pretrained weights. Visualizing the lower layer filters shows that models trained from random initialization do not learn Gabor filters on medical images. We use CCA (canonical correlation analysis) to study the learned representations of the different models, finding that pretrained models are surprisingly similar to random initialization at higher layers. This similarity is evidenced both through model learning dynamics and a transfusion experiment, which explores the convergence speed using a subset of pretrained weights.
Discrimination in the Age of Algorithms
Feb 11, 2019
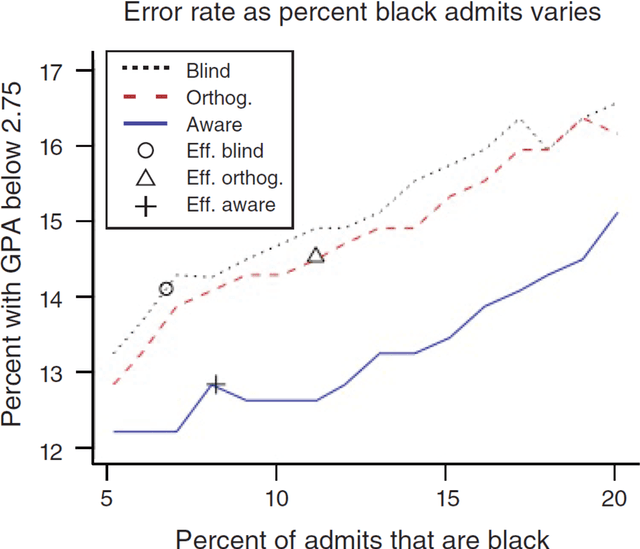
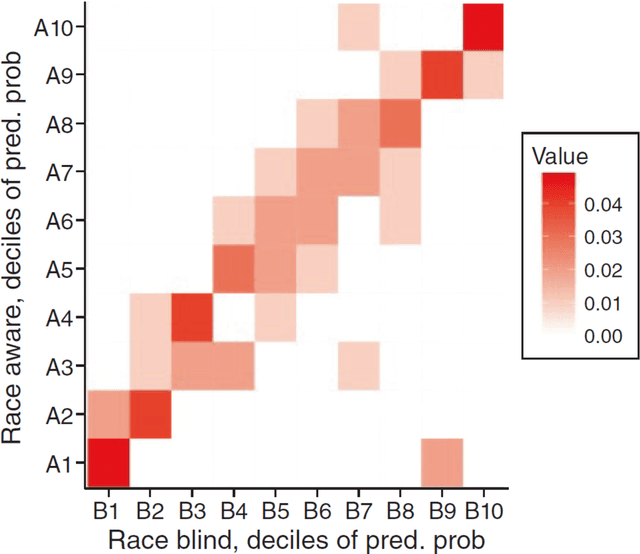
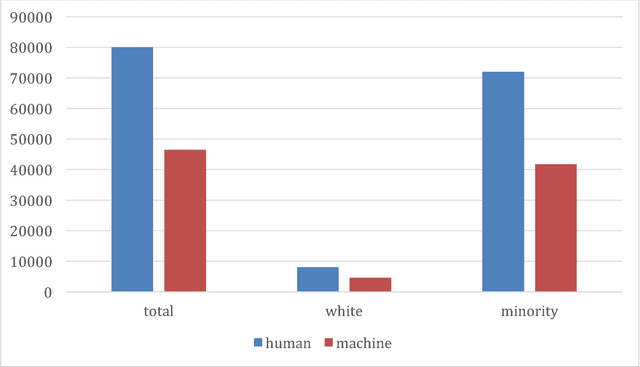
The law forbids discrimination. But the ambiguity of human decision-making often makes it extraordinarily hard for the legal system to know whether anyone has actually discriminated. To understand how algorithms affect discrimination, we must therefore also understand how they affect the problem of detecting discrimination. By one measure, algorithms are fundamentally opaque, not just cognitively but even mathematically. Yet for the task of proving discrimination, processes involving algorithms can provide crucial forms of transparency that are otherwise unavailable. These benefits do not happen automatically. But with appropriate requirements in place, the use of algorithms will make it possible to more easily examine and interrogate the entire decision process, thereby making it far easier to know whether discrimination has occurred. By forcing a new level of specificity, the use of algorithms also highlights, and makes transparent, central tradeoffs among competing values. Algorithms are not only a threat to be regulated; with the right safeguards in place, they have the potential to be a positive force for equity.
Core-fringe link prediction
Nov 28, 2018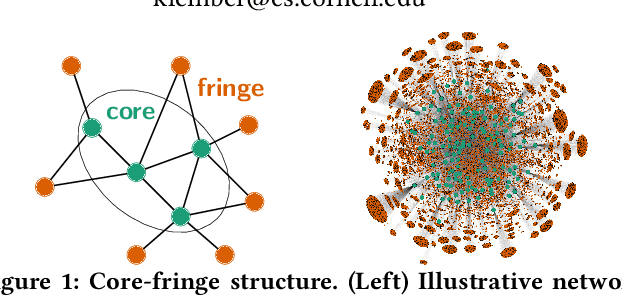
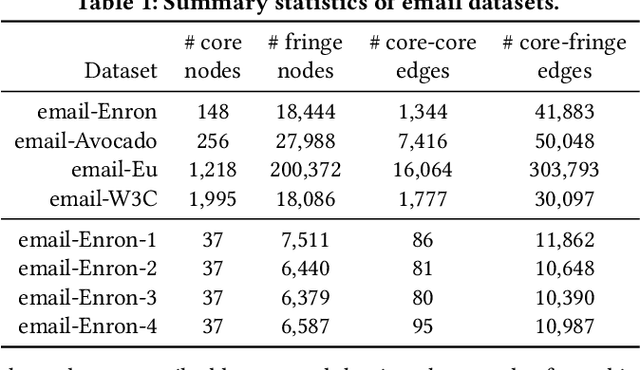
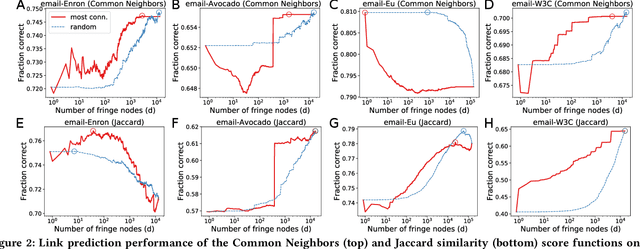
Data collection often involves the partial measurement of a larger system. A common example arises in the process collecting network data: we often obtain network datasets by recording all of the interactions among a small set of core nodes, so that we end up with a measurement of the network consisting of these core nodes together with a potentially much larger set of fringe nodes that have links to the core. Given the ubiquity of this process for assembling network data, it becomes crucial to understand the role of such a core-fringe structure. Here we study how the inclusion of fringe nodes affects the standard task of network link prediction. One might initially think the inclusion of any additional data is useful, and hence that it should be beneficial to include all fringe nodes that are available. However, we find that this is not true; in fact, there is substantial variability in the value of the fringe nodes for prediction. In some datasets, once an algorithm is selected, including any additional data from the fringe can actually hurt prediction performance; in other datasets, including some amount of fringe information is useful before prediction performance saturates or even declines; and in further cases, including the entire fringe leads to the best performance. While such variety might seem surprising, we show that these behaviors are exhibited by simple random graph models.
Direct Uncertainty Prediction for Medical Second Opinions
Sep 13, 2018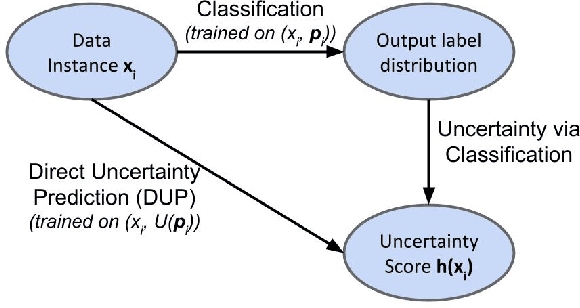

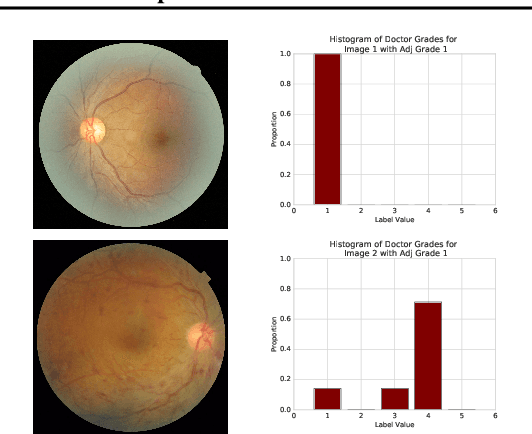

A persistent challenge in the practice of medicine (and machine learning) is the disagreement of highly trained human experts on data instances, such as patient image scans. We study the application of machine learning to predict which instances are likely to give rise to maximal expert disagreement. As necessitated by this, we develop predictors on datasets with noisy and scarce labels. Our central methodological finding is that direct prediction of a scalar uncertainty score performs better than the two-step process of (i) training a classifier (ii) using the classifier outputs to derive an uncertainty score. This is seen in both a synthetic setting whose parameters we can control, and a paradigmatic healthcare application involving multiple labels by medical domain experts. We evaluate these direct uncertainty models on a gold standard adjudicated set, where they accurately predict when an individual expert will disagree with an unknown ground truth. We explore the consequences for using these predictors to identify the need for a medical second opinion and a machine learning data curation application.
Simplicity Creates Inequity: Implications for Fairness, Stereotypes, and Interpretability
Sep 12, 2018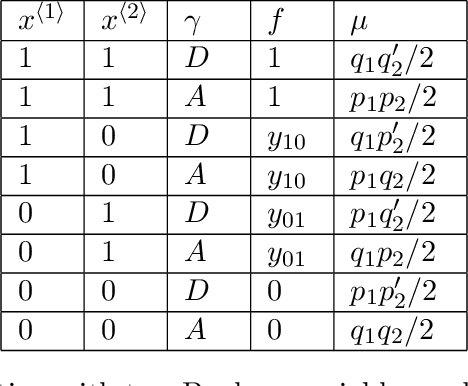
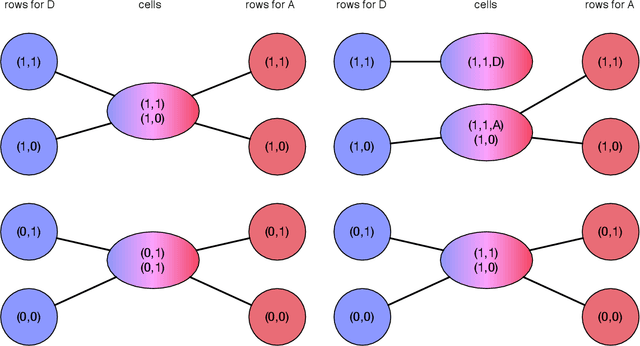

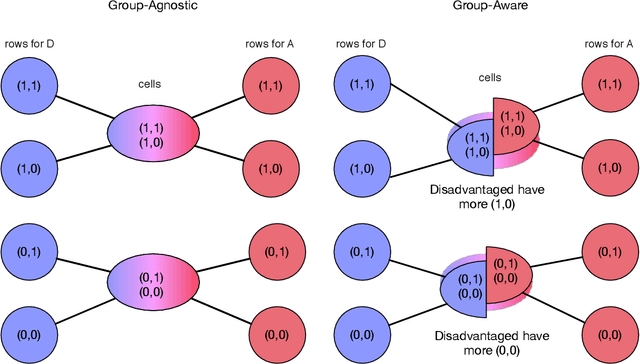
Algorithmic predictions are increasingly used to aid, or in some cases supplant, human decision-making, and this development has placed new demands on the outputs of machine learning procedures. To facilitate human interaction, we desire that they output prediction functions that are in some fashion simple or interpretable. And because they influence consequential decisions, we also desire equitable prediction functions, ones whose allocations benefit (or at the least do not harm) disadvantaged groups. We develop a formal model to explore the relationship between simplicity and equity. Although the two concepts appear to be motivated by qualitatively distinct goals, our main result shows a fundamental inconsistency between them. Specifically, we formalize a general framework for producing simple prediction functions, and in this framework we show that every simple prediction function is strictly improvable: there exists a more complex prediction function that is both strictly more efficient and also strictly more equitable. Put another way, using a simple prediction function both reduces utility for disadvantaged groups and reduces overall welfare. Our result is not only about algorithms but about any process that produces simple models, and as such connects to the psychology of stereotypes and to an earlier economics literature on statistical discrimination.
How Do Classifiers Induce Agents To Invest Effort Strategically?
Jul 13, 2018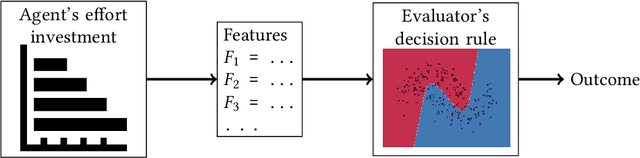
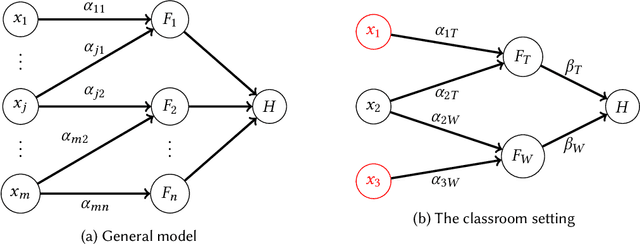
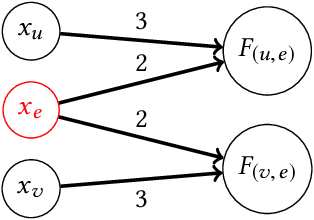
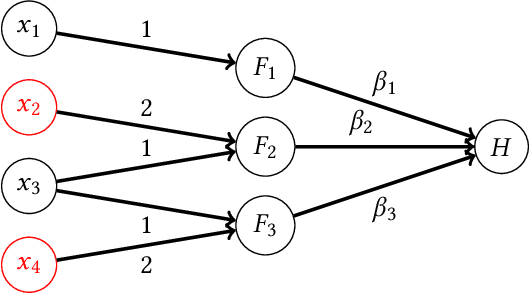
Machine learning is often used to produce decision-making rules that classify or evaluate individuals. When these individuals have incentives to be classified a certain way, they may behave strategically to influence their outcomes. We develop a model for how strategic agents can invest effort in order to change the outcomes they receive, and we give a tight characterization of when such agents can be incentivized to invest specified forms of effort into improving their outcomes as opposed to "gaming" the classifier. We show that whenever any "reasonable" mechanism can do so, a simple linear mechanism suffices.
Can Deep Reinforcement Learning Solve Erdos-Selfridge-Spencer Games?
Jun 29, 2018
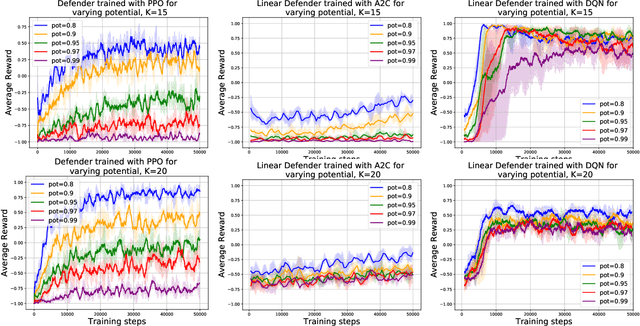
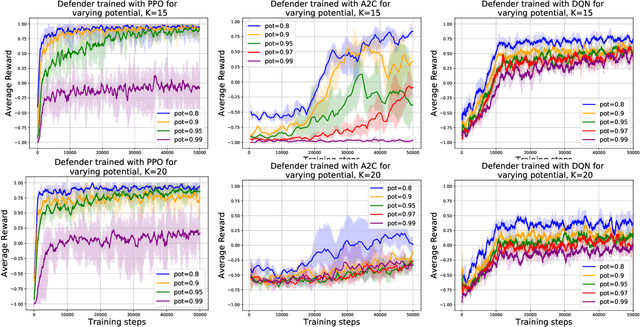
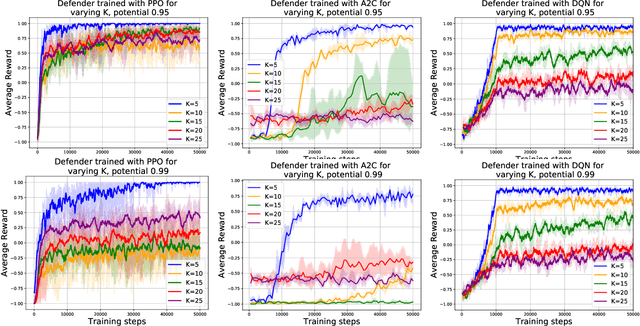
Deep reinforcement learning has achieved many recent successes, but our understanding of its strengths and limitations is hampered by the lack of rich environments in which we can fully characterize optimal behavior, and correspondingly diagnose individual actions against such a characterization. Here we consider a family of combinatorial games, arising from work of Erdos, Selfridge, and Spencer, and we propose their use as environments for evaluating and comparing different approaches to reinforcement learning. These games have a number of appealing features: they are challenging for current learning approaches, but they form (i) a low-dimensional, simply parametrized environment where (ii) there is a linear closed form solution for optimal behavior from any state, and (iii) the difficulty of the game can be tuned by changing environment parameters in an interpretable way. We use these Erdos-Selfridge-Spencer games not only to compare different algorithms, but test for generalization, make comparisons to supervised learning, analyse multiagent play, and even develop a self play algorithm. Code can be found at: https://github.com/rubai5/ESS_Game
Found Graph Data and Planted Vertex Covers
May 03, 2018
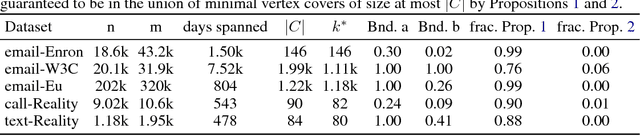
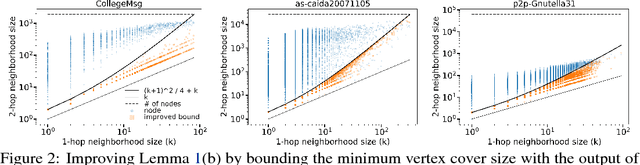

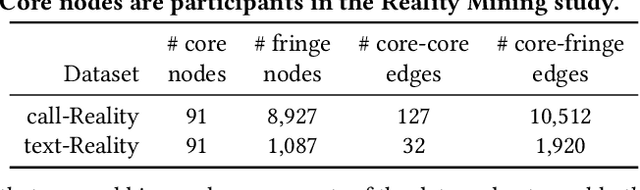
A typical way in which network data is recorded is to measure all the interactions among a specified set of core nodes; this produces a graph containing this core together with a potentially larger set of fringe nodes that have links to the core. Interactions between pairs of nodes in the fringe, however, are not recorded by this process, and hence not present in the resulting graph data. For example, a phone service provider may only have records of calls in which at least one of the participants is a customer; this can include calls between a customer and a non-customer, but not between pairs of non-customers. Knowledge of which nodes belong to the core is an important piece of metadata that is crucial for interpreting the network dataset. But in many cases, this metadata is not available, either because it has been lost due to difficulties in data provenance, or because the network consists of found data obtained in settings such as counter-surveillance. This leads to a natural algorithmic problem, namely the recovery of the core set. Since the core set forms a vertex cover of the graph, we essentially have a planted vertex cover problem, but with an arbitrary underlying graph. We develop a theoretical framework for analyzing this planted vertex cover problem, based on results in the theory of fixed-parameter tractability, together with algorithms for recovering the core. Our algorithms are fast, simple to implement, and out-perform several methods based on network core-periphery structure on various real-world datasets.
Fair Division via Social Comparison
Feb 25, 2018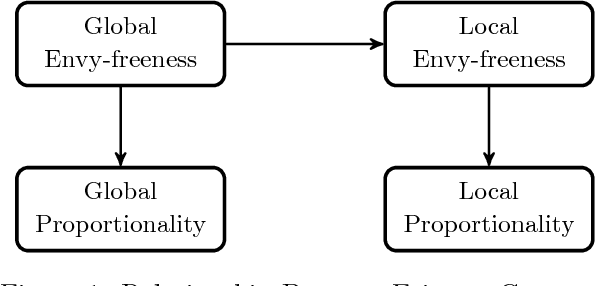
In the classical cake cutting problem, a resource must be divided among agents with different utilities so that each agent believes they have received a fair share of the resource relative to the other agents. We introduce a variant of the problem in which we model an underlying social network on the agents with a graph, and agents only evaluate their shares relative to their neighbors' in the network. This formulation captures many situations in which it is unrealistic to assume a global view, and also exposes interesting phenomena in the original problem. Specifically, we say an allocation is locally envy-free if no agent envies a neighbor's allocation and locally proportional if each agent values her own allocation as much as the average value of her neighbor's allocations, with the former implying the latter. While global envy-freeness implies local envy-freeness, global proportionality does not imply local proportionality, or vice versa. A general result is that for any two distinct graphs on the same set of nodes and an allocation, there exists a set of valuation functions such that the allocation is locally proportional on one but not the other. We fully characterize the set of graphs for which an oblivious single-cutter protocol-- a protocol that uses a single agent to cut the cake into pieces --admits a bounded protocol with $O(n^2)$ query complexity for locally envy-free allocations in the Robertson-Webb model. We also consider the price of envy-freeness, which compares the total utility of an optimal allocation to the best utility of an allocation that is envy-free. We show that a lower bound of $\Omega(\sqrt{n})$ on the price of envy-freeness for global allocations in fact holds for local envy-freeness in any connected undirected graph. Thus, sparse graphs surprisingly do not provide more flexibility with respect to the quality of envy-free allocations.
Simplicial Closure and Higher-order Link Prediction
Feb 20, 2018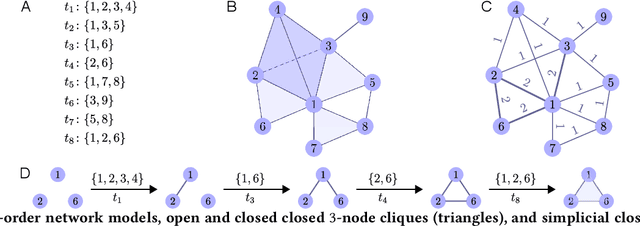
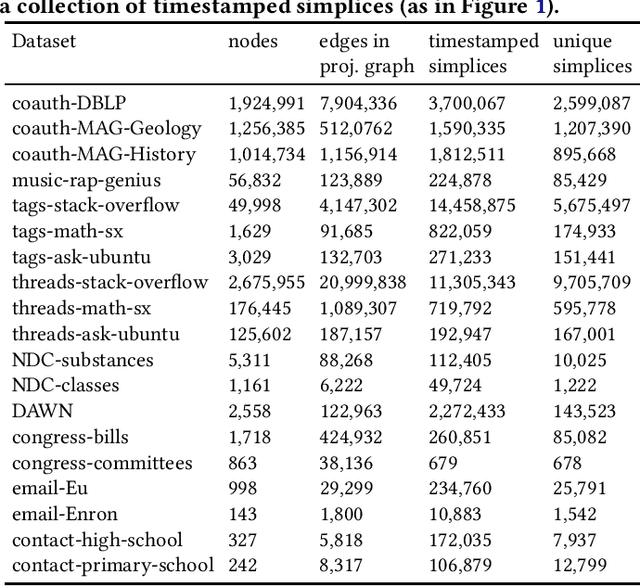
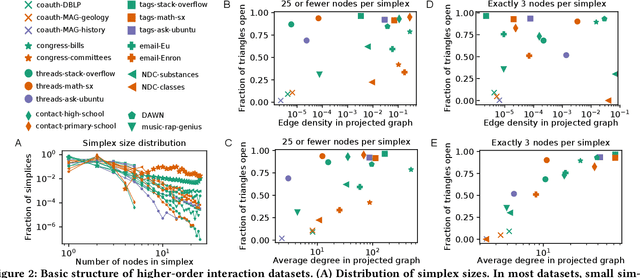
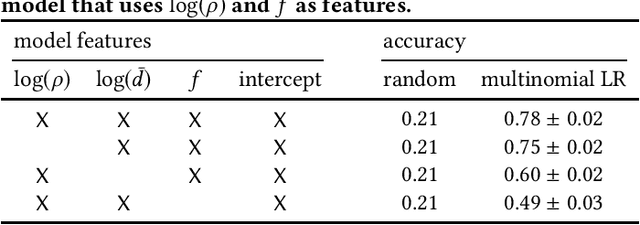
Networks provide a powerful formalism for modeling complex systems, by representing the underlying set of pairwise interactions. But much of the structure within these systems involves interactions that take place among more than two nodes at once; for example, communication within a group rather than person-to-person, collaboration among a team rather than a pair of co-authors, or biological interaction between a set of molecules rather than just two. We refer to these type of simultaneous interactions on sets of more than two nodes as higher-order interactions; they are ubiquitous, but the empirical study of them has lacked a general framework for evaluating higher-order models. Here we introduce such a framework, based on link prediction, a fundamental problem in network analysis. The traditional link prediction problem seeks to predict the appearance of new links in a network, and here we adapt it to predict which (larger) sets of elements will have future interactions. We study the temporal evolution of 19 datasets from a variety of domains, and use our higher-order formulation of link prediction to assess the types of structural features that are most predictive of new multi-way interactions. Among our results, we find that different domains vary considerably in their distribution of higher-order structural parameters, and that the higher-order link prediction problem exhibits some fundamental differences from traditional pairwise link prediction, with a greater role for local rather than long-range information in predicting the appearance of new interactions.