 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine Tracing: A New Paradigm for Probabilistic Linear Solvers
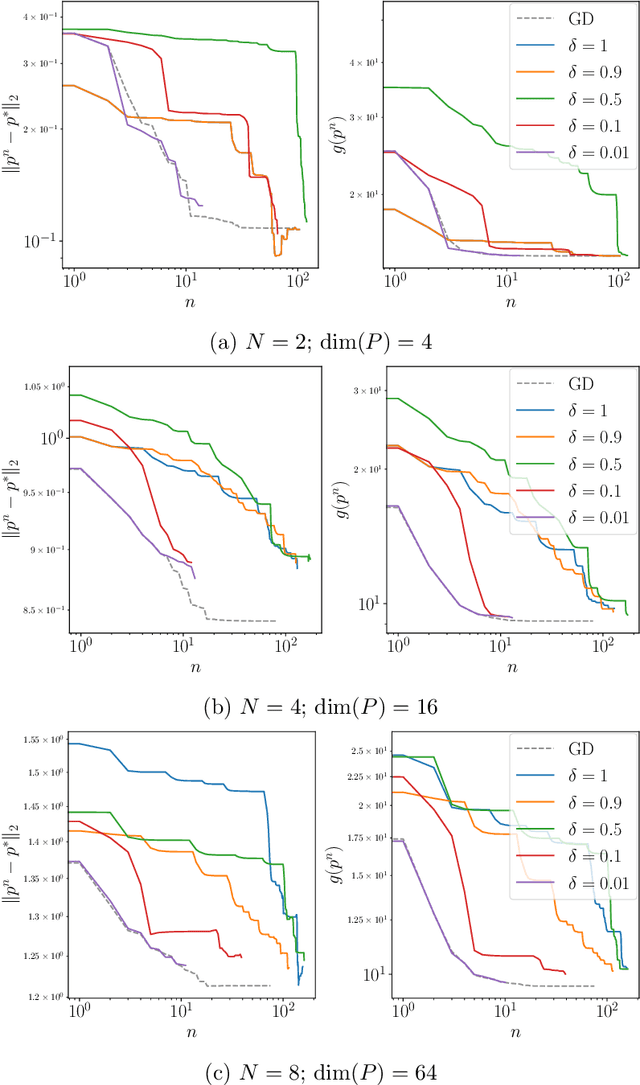
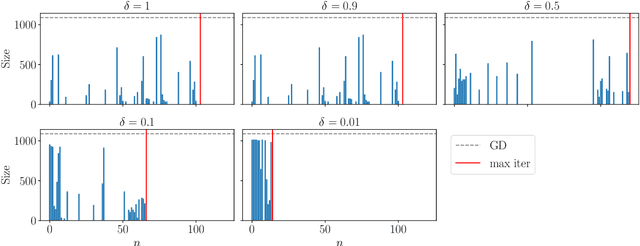
May 11, 2026Probabilistic linear solvers (PLSs) return probability distributions that quantify uncertainty due to limited computation in the solution of linear systems. The literature has traditionally distinguished between Bayesian PLSs, which condition a prior on information obtained from projections of the linear system, and probabilistic iterative methods (PIMs), which lift classical iterative solvers to probability space. In this work we show this dichotomy to be false: Bayesian PLSs are a special case of non-stationary affine PIMs. In addition, we prove that any realistic affine PIM is calibrated. These results motivate a focus on (non-stationary) affine PIMs, but their practical adoption has been limited by the significant manual effort required to implement them. To address this, we introduce affine tracing, an algorithmic framework that automatically constructs a PIM from a standard implementation of an affine iterative method by passing symbolic tracers through the computation to build an affine computational graph. We show how this graph can be transformed to compute posterior covariances, and how equality saturation can be used to perform algebraic simplifications required for computation under specific prior choices. We demonstrate the framework by automatically generating a probabilistic multigrid solver and evaluate its performance in the context of Gaussian process approximation.
Constructive Disintegration and Conditional Modes
Aug 01, 2025

Conditioning, the central operation in Bayesian statistics, is formalised by the notion of disintegration of measures. However, due to the implicit nature of their definition, constructing disintegrations is often difficult. A folklore result in machine learning conflates the construction of a disintegration with the restriction of probability density functions onto the subset of events that are consistent with a given observation. We provide a comprehensive set of mathematical tools which can be used to construct disintegrations and apply these to find densities of disintegrations on differentiable manifolds. Using our results, we provide a disturbingly simple example in which the restricted density and the disintegration density drastically disagree. Motivated by applications in approximate Bayesian inference and Bayesian inverse problems, we further study the modes of disintegrations. We show that the recently introduced notion of a "conditional mode" does not coincide in general with the modes of the conditional measure obtained through disintegration, but rather the modes of the restricted measure. We also discuss the implications of the discrepancy between the two measures in practice, advocating for the utility of both approaches depending on the modelling context.
Randomised Postiterations for Calibrated BayesCG
Apr 05, 2025The Bayesian conjugate gradient method offers probabilistic solutions to linear systems but suffers from poor calibration, limiting its utility in uncertainty quantification tasks. Recent approaches leveraging postiterations to construct priors have improved computational properties but failed to correct calibration issues. In this work, we propose a novel randomised postiteration strategy that enhances the calibration of the BayesCG posterior while preserving its favourable convergence characteristics. We present theoretical guarantees for the improved calibration, supported by results on the distribution of posterior errors. Numerical experiments demonstrate the efficacy of the method in both synthetic and inverse problem settings, showing enhanced uncertainty quantification and better propagation of uncertainties through computational pipelines.
Learning to Solve Related Linear Systems
Mar 21, 2025Solving multiple parametrised related systems is an essential component of many numerical tasks. Borrowing strength from the solved systems and learning will make this process faster. In this work, we propose a novel probabilistic linear solver over the parameter space. This leverages information from the solved linear systems in a regression setting to provide an efficient posterior mean and covariance. We advocate using this as companion regression model for the preconditioned conjugate gradient method, and discuss the favourable properties of the posterior mean and covariance as the initial guess and preconditioner. We also provide several design choices for this companion solver. Numerical experiments showcase the benefits of using our novel solver in a hyperparameter optimisation problem.
Calibrated Computation-Aware Gaussian Processes
Oct 11, 2024



Gaussian processes are notorious for scaling cubically with the size of the training set, preventing application to very large regression problems. Computation-aware Gaussian processes (CAGPs) tackle this scaling issue by exploiting probabilistic linear solvers to reduce complexity, widening the posterior with additional computational uncertainty due to reduced computation. However, the most commonly used CAGP framework results in (sometimes dramatically) conservative uncertainty quantification, making the posterior unrealistic in practice. In this work, we prove that if the utilised probabilistic linear solver is calibrated, in a rigorous statistical sense, then so too is the induced CAGP. We thus propose a new CAGP framework, CAGP-GS, based on using Gauss-Seidel iterations for the underlying probabilistic linear solver. CAGP-GS performs favourably compared to existing approaches when the test set is low-dimensional and few iterations are performed. We test the calibratedness on a synthetic problem, and compare the performance to existing approaches on a large-scale global temperature regression problem.
Computation-Aware Kalman Filtering and Smoothing
May 14, 2024Kalman filtering and smoothing are the foundational mechanisms for efficient inference in Gauss-Markov models. However, their time and memory complexities scale prohibitively with the size of the state space. This is particularly problematic in spatiotemporal regression problems, where the state dimension scales with the number of spatial observations. Existing approximate frameworks leverage low-rank approximations of the covariance matrix. Since they do not model the error introduced by the computational approximation, their predictive uncertainty estimates can be overly optimistic. In this work, we propose a probabilistic numerical method for inference in high-dimensional Gauss-Markov models which mitigates these scaling issues. Our matrix-free iterative algorithm leverages GPU acceleration and crucially enables a tunable trade-off between computational cost and predictive uncertainty. Finally, we demonstrate the scalability of our method on a large-scale climate dataset.
Bayesian Numerical Methods for Nonlinear Partial Differential Equations
May 03, 2021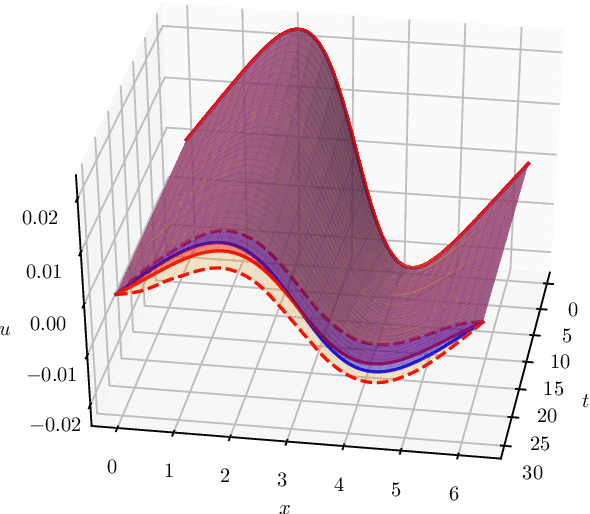
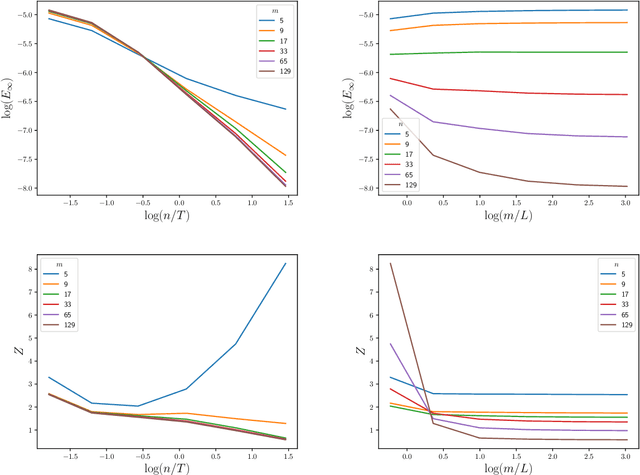
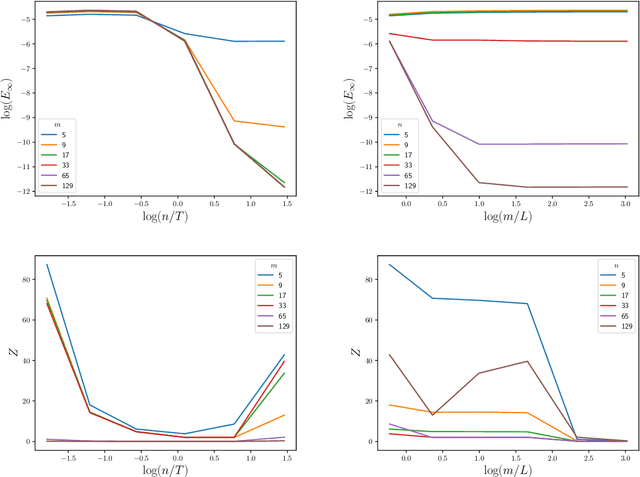
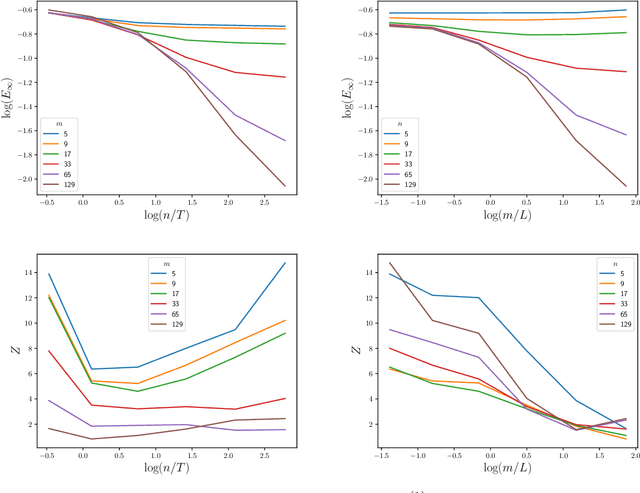
The numerical solution of differential equations can be formulated as an inference problem to which formal statistical approaches can be applied. However, nonlinear partial differential equations (PDEs) pose substantial challenges from an inferential perspective, most notably the absence of explicit conditioning formula. This paper extends earlier work on linear PDEs to a general class of initial value problems specified by nonlinear PDEs, motivated by problems for which evaluations of the right-hand-side, initial conditions, or boundary conditions of the PDE have a high computational cost. The proposed method can be viewed as exact Bayesian inference under an approximate likelihood, which is based on discretisation of the nonlinear differential operator. Proof-of-concept experimental results demonstrate that meaningful probabilistic uncertainty quantification for the unknown solution of the PDE can be performed, while controlling the number of times the right-hand-side, initial and boundary conditions are evaluated. A suitable prior model for the solution of the PDE is identified using novel theoretical analysis of the sample path properties of Mat\'{e}rn processes, which may be of independent interest.
A Probabilistic Taylor Expansion with Applications in Filtering and Differential Equations
Feb 01, 2021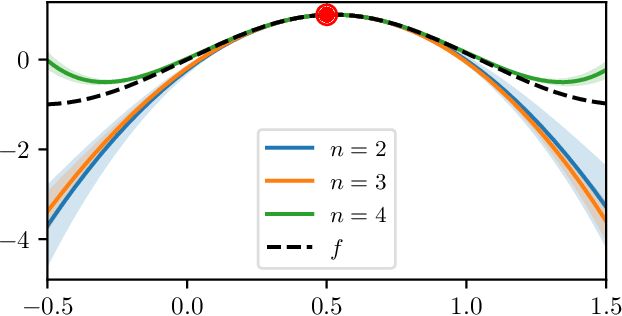
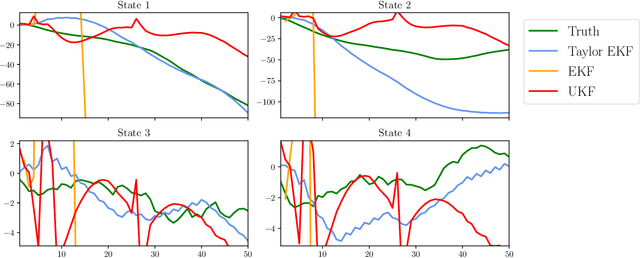
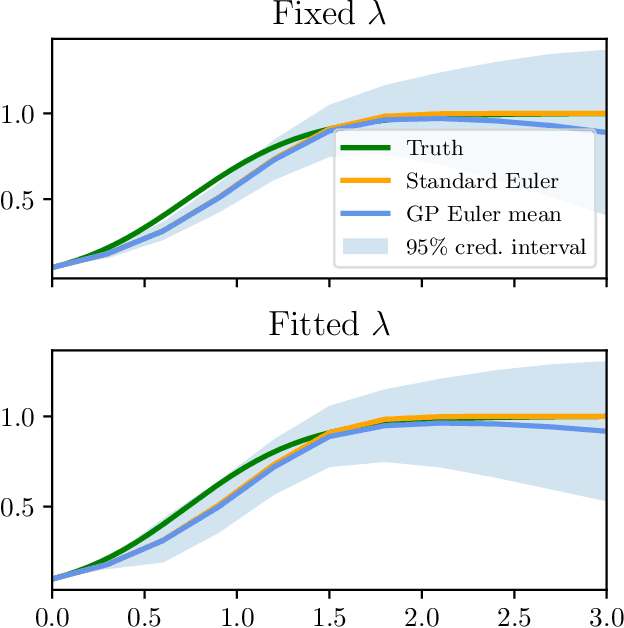
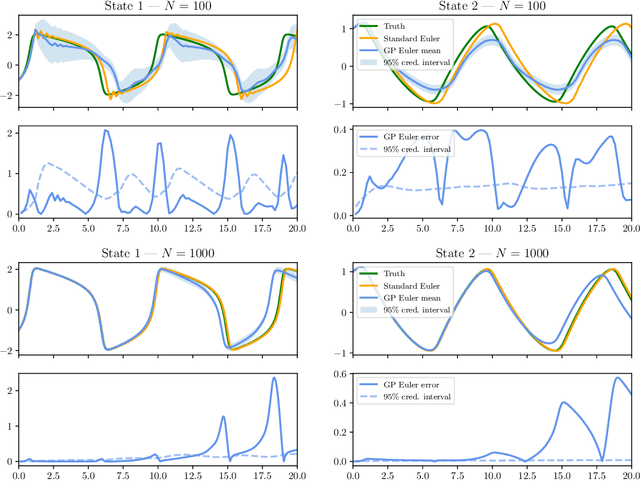
We study a class of Gaussian processes for which the posterior mean, for a particular choice of data, replicates a truncated Taylor expansion of any order. The data consists of derivative evaluations at the expansion point and the prior covariance kernel belongs to the class of Taylor kernels, which can be written in a certain power series form. This permits statistical modelling of the uncertainty in a variety of algorithms that exploit first and second order Taylor expansions. To demonstrate the utility of this Gaussian process model we introduce new probabilistic versions of the classical extended Kalman filter for non-linear state estimation and the Euler method for solving ordinary differential equations.
Probabilistic Iterative Methods for Linear Systems
Jan 11, 2021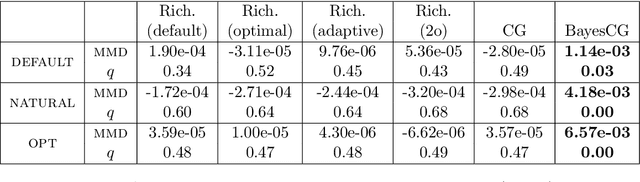
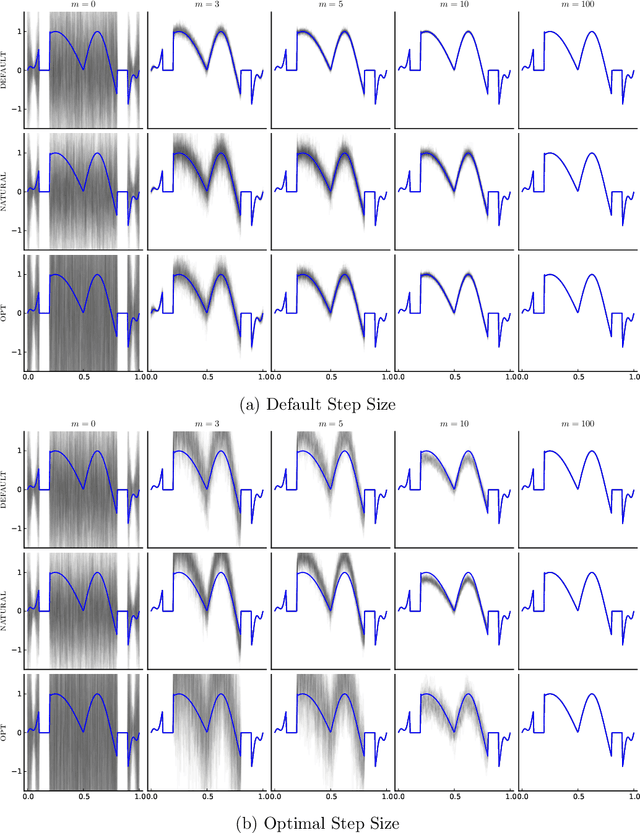
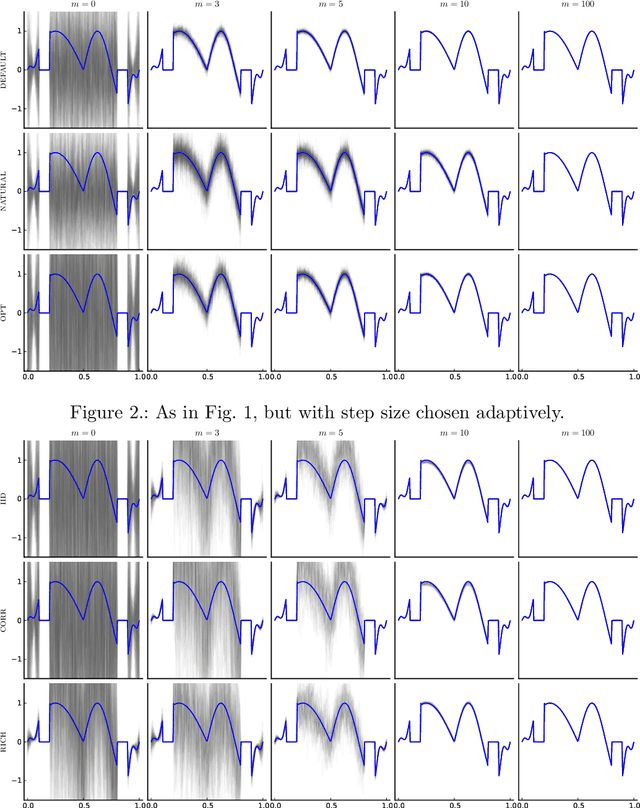
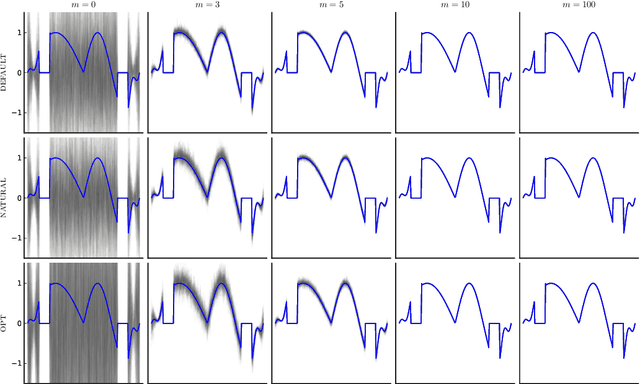
This paper presents a probabilistic perspective on iterative methods for approximating the solution $\mathbf{x}_* \in \mathbb{R}^d$ of a nonsingular linear system $\mathbf{A} \mathbf{x}_* = \mathbf{b}$. In the approach a standard iterative method on $\mathbb{R}^d$ is lifted to act on the space of probability distributions $\mathcal{P}(\mathbb{R}^d)$. Classically, an iterative method produces a sequence $\mathbf{x}_m$ of approximations that converge to $\mathbf{x}_*$. The output of the iterative methods proposed in this paper is, instead, a sequence of probability distributions $\mu_m \in \mathcal{P}(\mathbb{R}^d)$. The distributional output both provides a "best guess" for $\mathbf{x}_*$, for example as the mean of $\mu_m$, and also probabilistic uncertainty quantification for the value of $\mathbf{x}_*$ when it has not been exactly determined. Theoretical analysis is provided in the prototypical case of a stationary linear iterative method. In this setting we characterise both the rate of contraction of $\mu_m$ to an atomic measure on $\mathbf{x}_*$ and the nature of the uncertainty quantification being provided. We conclude with an empirical illustration that highlights the insight into solution uncertainty that can be provided by probabilistic iterative methods.
Probabilistic Gradients for Fast Calibration of Differential Equation Models
Sep 03, 2020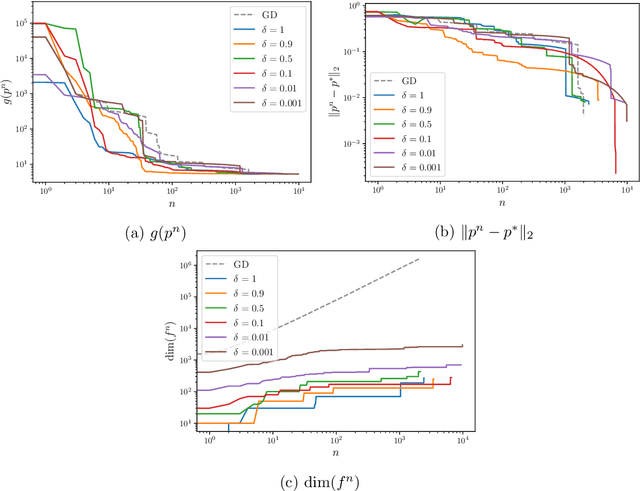
Calibration of large-scale differential equation models to observational or experimental data is a widespread challenge throughout applied sciences and engineering. A crucial bottleneck in state-of-the art calibration methods is the calculation of local sensitivities, i.e. derivatives of the loss function with respect to the estimated parameters, which often necessitates several numerical solves of the underlying system of partial or ordinary differential equations. In this paper we present a new probabilistic approach to computing local sensitivities. The proposed method has several advantages over classical methods. Firstly, it operates within a constrained computational budget and provides a probabilistic quantification of uncertainty incurred in the sensitivities from this constraint. Secondly, information from previous sensitivity estimates can be recycled in subsequent computations, reducing the overall computational effort for iterative gradient-based calibration methods. The methodology presented is applied to two challenging test problems and compared against classical methods.