 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Drifting Based on Maximal Safety Probability Learning
Sep 05, 2024This paper proposes a novel learning-based framework for autonomous driving based on the concept of maximal safety probability. Efficient learning requires rewards that are informative of desirable/undesirable states, but such rewards are challenging to design manually due to the difficulty of differentiating better states among many safe states. On the other hand, learning policies that maximize safety probability does not require laborious reward shaping but is numerically challenging because the algorithms must optimize policies based on binary rewards sparse in time. Here, we show that physics-informed reinforcement learning can efficiently learn this form of maximally safe policy. Unlike existing drift control methods, our approach does not require a specific reference trajectory or complex reward shaping, and can learn safe behaviors only from sparse binary rewards. This is enabled by the use of the physics loss that plays an analogous role to reward shaping. The effectiveness of the proposed approach is demonstrated through lane keeping in a normal cornering scenario and safe drifting in a high-speed racing scenario.
WROOM: An Autonomous Driving Approach for Off-Road Navigation
Apr 12, 2024



Off-road navigation is a challenging problem both at the planning level to get a smooth trajectory and at the control level to avoid flipping over, hitting obstacles, or getting stuck at a rough patch. There have been several recent works using classical approaches involving depth map prediction followed by smooth trajectory planning and using a controller to track it. We design an end-to-end reinforcement learning (RL) system for an autonomous vehicle in off-road environments using a custom-designed simulator in the Unity game engine. We warm-start the agent by imitating a rule-based controller and utilize Proximal Policy Optimization (PPO) to improve the policy based on a reward that incorporates Control Barrier Functions (CBF), facilitating the agent's ability to generalize effectively to real-world scenarios. The training involves agents concurrently undergoing domain-randomized trials in various environments. We also propose a novel simulation environment to replicate off-road driving scenarios and deploy our proposed approach on a real buggy RC car. Videos and additional results: https://sites.google.com/view/wroom-utd/home
Synthesis and verification of robust-adaptive safe controllers
Nov 01, 2023



Safe control with guarantees generally requires the system model to be known. It is far more challenging to handle systems with uncertain parameters. In this paper, we propose a generic algorithm that can synthesize and verify safe controllers for systems with constant, unknown parameters. In particular, we use robust-adaptive control barrier functions (raCBFs) to achieve safety. We develop new theories and techniques using sum-of-squares that enable us to pose synthesis and verification as a series of convex optimization problems. In our experiments, we show that our algorithms are general and scalable, applying them to three different polynomial systems of up to moderate size (7D). Our raCBFs are currently the most effective way to guarantee safety for uncertain systems, achieving 100% safety and up to 55% performance improvement over a robust baseline.
Spline-Based Minimum-Curvature Trajectory Optimization for Autonomous Racing
Sep 17, 2023We propose a novel B-spline trajectory optimization method for autonomous racing. We consider the unavailability of sophisticated race car and race track dynamics in early-stage autonomous motorsports development and derive methods that work with limited dynamics data and additional conservative constraints. We formulate a minimum-curvature optimization problem with only the spline control points as optimization variables. We then compare the current state-of-the-art method with our optimization result, which achieves a similar level of optimality with a 90% reduction on the decision variable dimension, and in addition offers mathematical smoothness guarantee and flexible manipulation options. We concurrently reduce the problem computation time from seconds to milliseconds for a long race track, enabling future online adaptation of the previously offline technique.
Towards Optimal Head-to-head Autonomous Racing with Curriculum Reinforcement Learning
Aug 25, 2023



Head-to-head autonomous racing is a challenging problem, as the vehicle needs to operate at the friction or handling limits in order to achieve minimum lap times while also actively looking for strategies to overtake/stay ahead of the opponent. In this work we propose a head-to-head racing environment for reinforcement learning which accurately models vehicle dynamics. Some previous works have tried learning a policy directly in the complex vehicle dynamics environment but have failed to learn an optimal policy. In this work, we propose a curriculum learning-based framework by transitioning from a simpler vehicle model to a more complex real environment to teach the reinforcement learning agent a policy closer to the optimal policy. We also propose a control barrier function-based safe reinforcement learning algorithm to enforce the safety of the agent in a more effective way while not compromising on optimality.
Risk-aware Safe Control for Decentralized Multi-agent Systems via Dynamic Responsibility Allocation
May 22, 2023Decentralized control schemes are increasingly favored in various domains that involve multi-agent systems due to the need for computational efficiency as well as general applicability to large-scale systems. However, in the absence of an explicit global coordinator, it is hard for distributed agents to determine how to efficiently interact with others. In this paper, we present a risk-aware decentralized control framework that provides guidance on how much relative responsibility share (a percentage) an individual agent should take to avoid collisions with others while moving efficiently without direct communications. We propose a novel Control Barrier Function (CBF)-inspired risk measurement to characterize the aggregate risk agents face from potential collisions under motion uncertainty. We use this measurement to allocate responsibility shares among agents dynamically and develop risk-aware decentralized safe controllers. In this way, we are able to leverage the flexibility of robots with lower risk to improve the motion flexibility for those with higher risk, thus achieving improved collective safety. We demonstrate the validity and efficiency of our proposed approach through two examples: ramp merging in autonomous driving and a multi-agent position-swapping game.
Active Probing and Influencing Human Behaviors Via Autonomous Agents
Apr 24, 2023



Autonomous agents (robots) face tremendous challenges while interacting with heterogeneous human agents in close proximity. One of these challenges is that the autonomous agent does not have an accurate model tailored to the specific human that the autonomous agent is interacting with, which could sometimes result in inefficient human-robot interaction and suboptimal system dynamics. Developing an online method to enable the autonomous agent to learn information about the human model is therefore an ongoing research goal. Existing approaches position the robot as a passive learner in the environment to observe the physical states and the associated human response. This passive design, however, only allows the robot to obtain information that the human chooses to exhibit, which sometimes doesn't capture the human's full intention. In this work, we present an online optimization-based probing procedure for the autonomous agent to clarify its belief about the human model in an active manner. By optimizing an information radius, the autonomous agent chooses the action that most challenges its current conviction. This procedure allows the autonomous agent to actively probe the human agents to reveal information that's previously unavailable to the autonomous agent. With this gathered information, the autonomous agent can interactively influence the human agent for some designated objectives. Our main contributions include a coherent theoretical framework that unifies the probing and influence procedures and two case studies in autonomous driving that show how active probing can help to create better participant experience during influence, like higher efficiency or less perturbations.
Adaptive Planning and Control with Time-Varying Tire Models for Autonomous Racing Using Extreme Learning Machine
Mar 14, 2023



Autonomous racing is a challenging problem, as the vehicle needs to operate at the friction or handling limits in order to achieve minimum lap times. Autonomous race cars require highly accurate perception, state estimation, planning and precise application of controls. What makes it even more challenging is the accurate identification of vehicle model parameters that dictate the effects of the lateral tire slip, which may change over time, for example, due to wear and tear of the tires. Current works either propose model identification offline or need good parameters to start with (within 15-20\% of actual value), which is not enough to account for major changes in tire model that occur during actual races when driving at the control limits. We propose a unified framework which learns the tire model online from the collected data, as well as adjusts the model based on environmental changes even if the model parameters change by a higher margin. We demonstrate our approach in numeric and high-fidelity simulators for a 1:43 scale race car and a full-size car.
Towards Safety Assured End-to-End Vision-Based Control for Autonomous Racing
Mar 03, 2023



Autonomous car racing is a challenging task, as it requires precise applications of control while the vehicle is operating at cornering speeds. Traditional autonomous pipelines require accurate pre-mapping, localization, and planning which make the task computationally expensive and environment-dependent. Recent works propose use of imitation and reinforcement learning to train end-to-end deep neural networks and have shown promising results for high-speed racing. However, the end-to-end models may be dangerous to be deployed on real systems, as the neural networks are treated as black-box models devoid of any provable safety guarantees. In this work we propose a decoupled approach where an optimal end-to-end controller and a state prediction end-to-end model are learned together, and the predicted state of the vehicle is used to formulate a control barrier function for safeguarding the vehicle to stay within lane boundaries. We validate our algorithm both on a high-fidelity Carla driving simulator and a 1/10-scale RC car on a real track. The evaluation results suggest that using an explicit safety controller helps to learn the task safely with fewer iterations and makes it possible to safely navigate the vehicle on the track along the more challenging racing line.
Spatio-temporal Motion Planning for Autonomous Vehicles with Trapezoidal Prism Corridors and Bézier Curves
Sep 30, 2022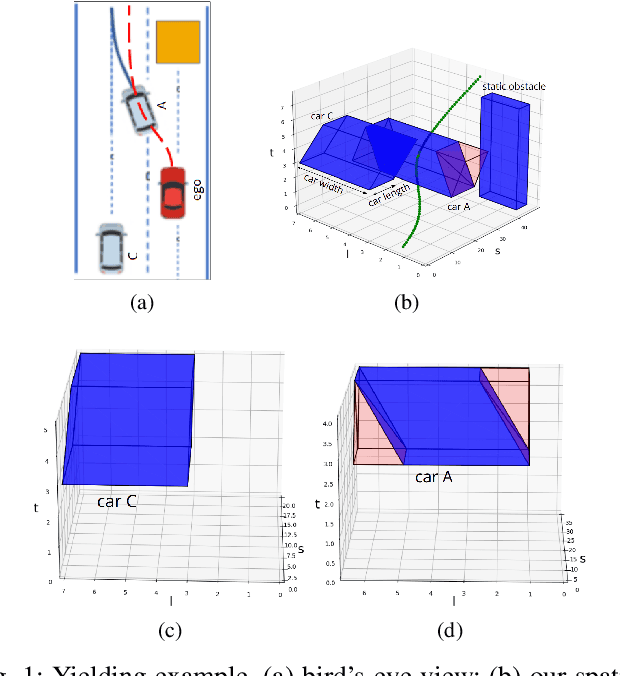
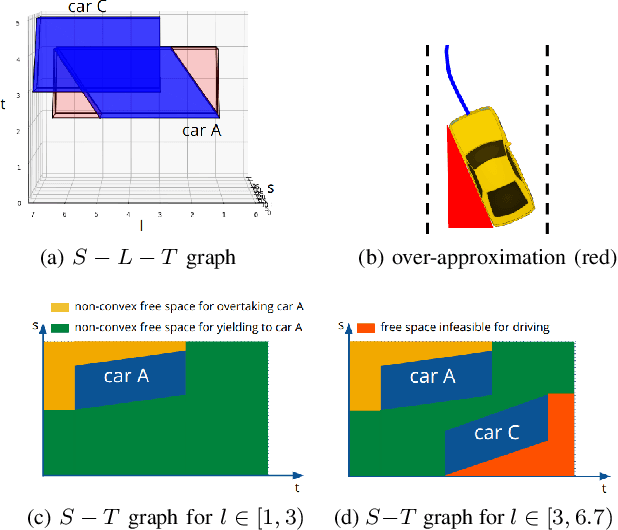
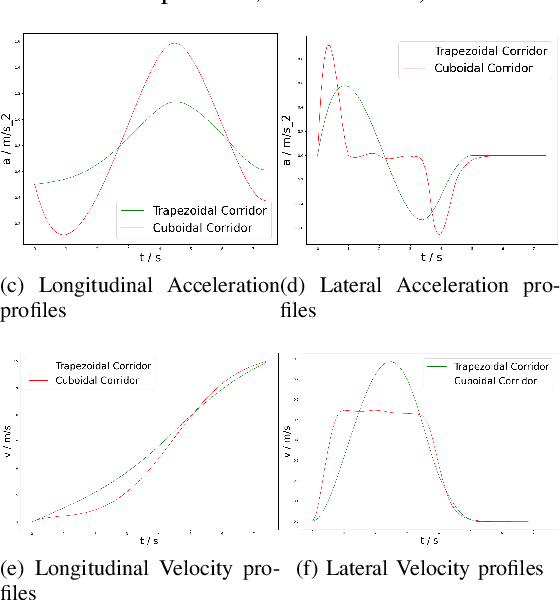
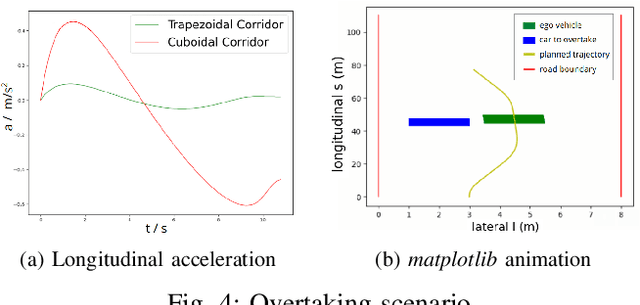
Safety-guaranteed motion planning is critical for self-driving cars to generate collision-free trajectories. A layered motion planning approach with decoupled path and speed planning is widely used for this purpose. This approach is prone to be suboptimal in the presence of dynamic obstacles. Spatial-temporal approaches deal with path planning and speed planning simultaneously; however, the existing methods only support simple-shaped corridors like cuboids, which restrict the search space for optimization in complex scenarios. We propose to use trapezoidal prism-shaped corridors for optimization, which significantly enlarges the solution space compared to the existing cuboidal corridors-based method. Finally, a piecewise B\'{e}zier curve optimization is conducted in our proposed corridors. This formulation theoretically guarantees the safety of the continuous-time trajectory. We validate the efficiency and effectiveness of the proposed approach in numerical and CommonRoad simulations.