 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Likelihood for Contextual Bandits
Jun 21, 2019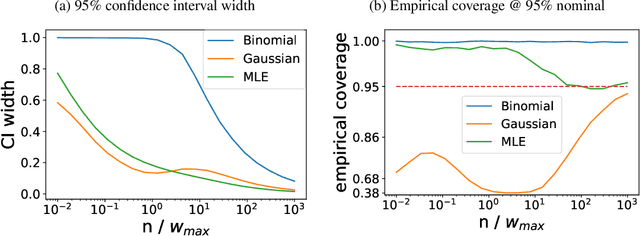
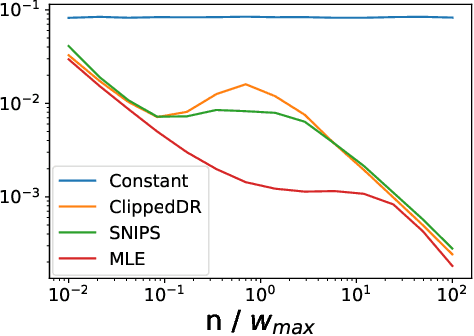
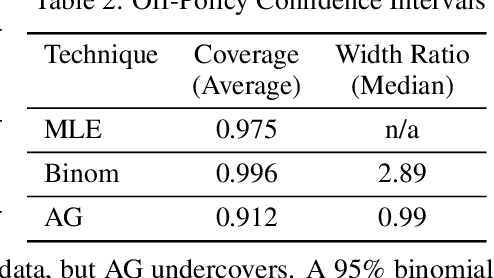
We apply empirical likelihood techniques to contextual bandit policy value estimation, confidence intervals, and learning. We propose a tighter estimator for off-policy evaluation with improved statistical performance over previous proposals. Coupled with this estimator is a confidence interval which also improves over previous proposals. We then harness these to improve learning from contextual bandit data. Each of these is empirically evaluated to show good performance against strong baselines in finite sample regimes.
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
Jun 09, 2019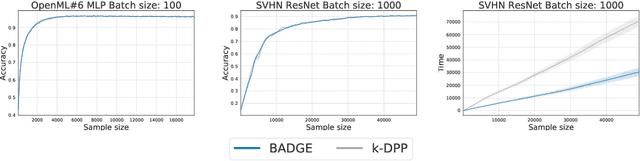
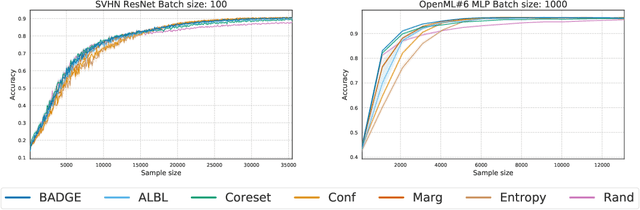
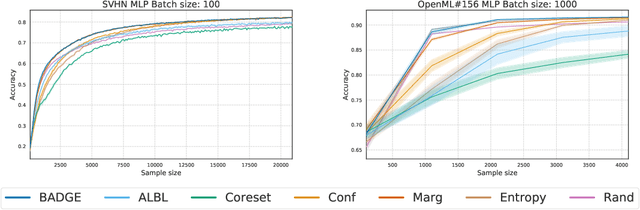
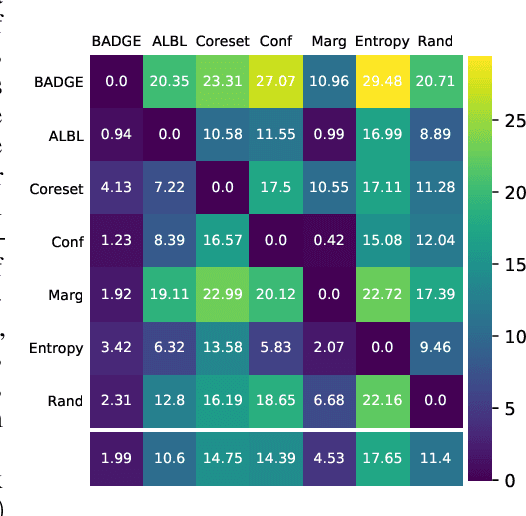
We design a new algorithm for batch active learning with deep neural network models. Our algorithm, Batch Active learning by Diverse Gradient Embeddings (BADGE), samples groups of points that are disparate and high-magnitude when represented in a hallucinated gradient space, a strategy designed to incorporate both predictive uncertainty and sample diversity into every selected batch. Crucially, BADGE trades off between diversity and uncertainty without requiring any hand-tuned hyperparameters. We show that while other approaches sometimes succeed for particular batch sizes or architectures, BADGE consistently performs as well or better, making it a versatile option for practical active learning problems.
Efficient Forward Architecture Search
May 31, 2019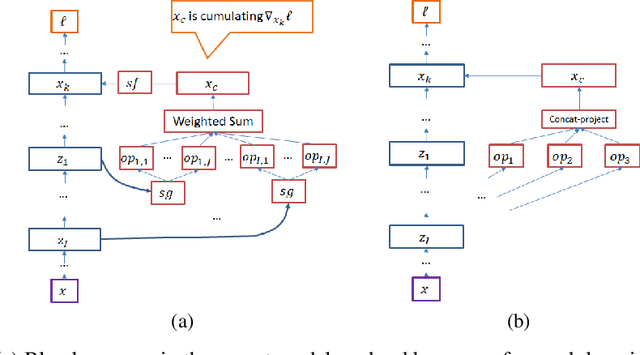
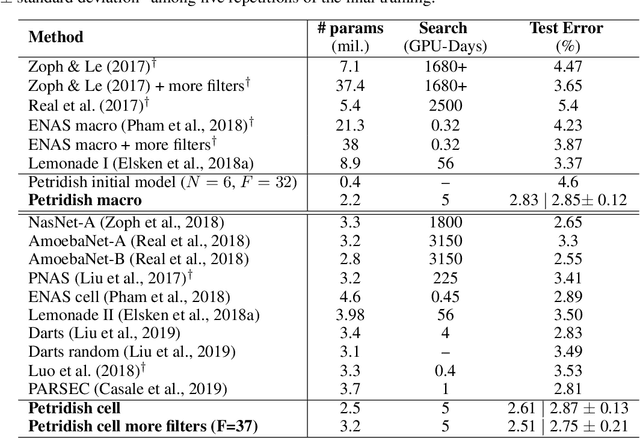
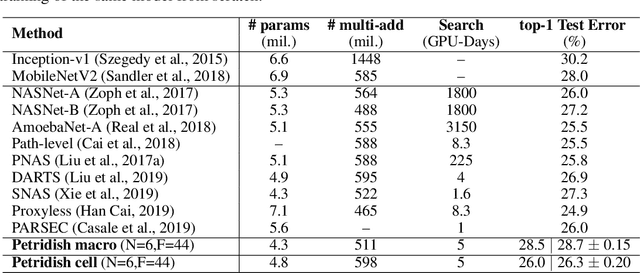
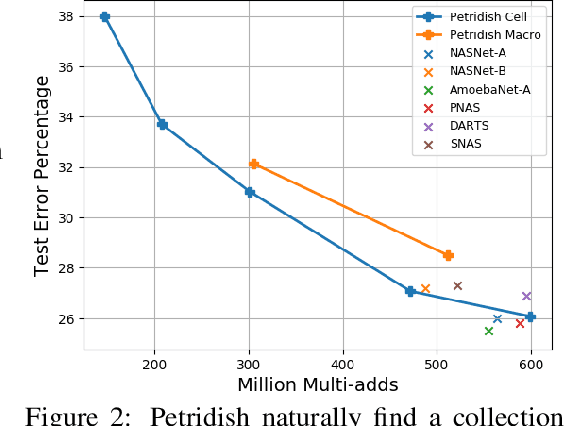
We propose a neural architecture search (NAS) algorithm, Petridish, to iteratively add shortcut connections to existing network layers. The added shortcut connections effectively perform gradient boosting on the augmented layers. The proposed algorithm is motivated by the feature selection algorithm forward stage-wise linear regression, since we consider NAS as a generalization of feature selection for regression, where NAS selects shortcuts among layers instead of selecting features. In order to reduce the number of trials of possible connection combinations, we train jointly all possible connections at each stage of growth while leveraging feature selection techniques to choose a subset of them. We experimentally show this process to be an efficient forward architecture search algorithm that can find competitive models using few GPU days in both the search space of repeatable network modules (cell-search) and the space of general networks (macro-search). Petridish is particularly well-suited for warm-starting from existing models crucial for lifelong-learning scenarios.
Contextual Bandits with Continuous Actions: Smoothing, Zooming, and Adapting
Feb 05, 2019
We study contextual bandit learning with an abstract policy class and continuous action space. We obtain two qualitatively different regret bounds: one competes with a smoothed version of the policy class under no continuity assumptions, while the other requires standard Lipschitz assumptions. Both bounds exhibit data-dependent "zooming" behavior and, with no tuning, yield improved guarantees for benign problems. We also study adapting to unknown smoothness parameters, establishing a price-of-adaptivity and deriving optimal adaptive algorithms that require no additional information.
Provably efficient RL with Rich Observations via Latent State Decoding
Jan 25, 2019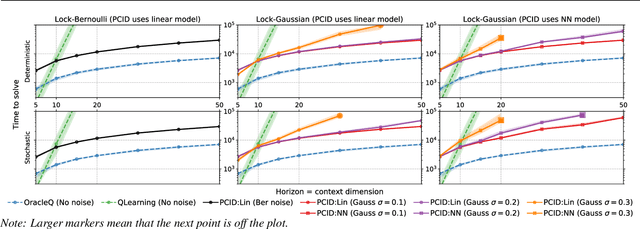
We study the exploration problem in episodic MDPs with rich observations generated from a small number of latent states. Under certain identifiability assumptions, we demonstrate how to estimate a mapping from the observations to latent states inductively through a sequence of regression and clustering steps---where previously decoded latent states provide labels for later regression problems---and use it to construct good exploration policies. We provide finite-sample guarantees on the quality of the learned state decoding function and exploration policies, and complement our theory with an empirical evaluation on a class of hard exploration problems. Our method exponentially improves over $Q$-learning with na\"ive exploration, even when $Q$-learning has cheating access to latent states.
Warm-starting Contextual Bandits: Robustly Combining Supervised and Bandit Feedback
Jan 02, 2019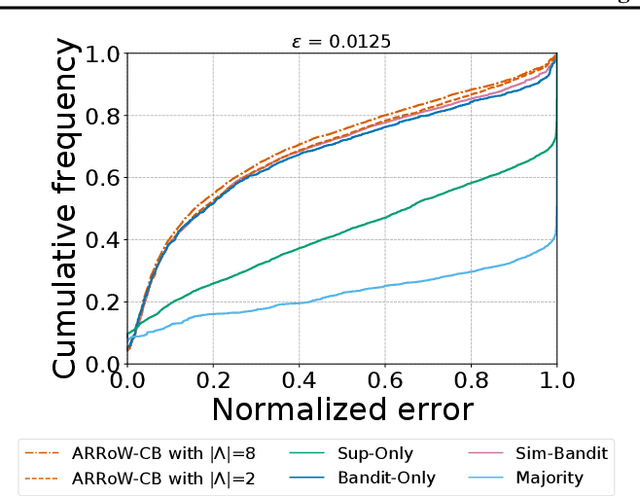
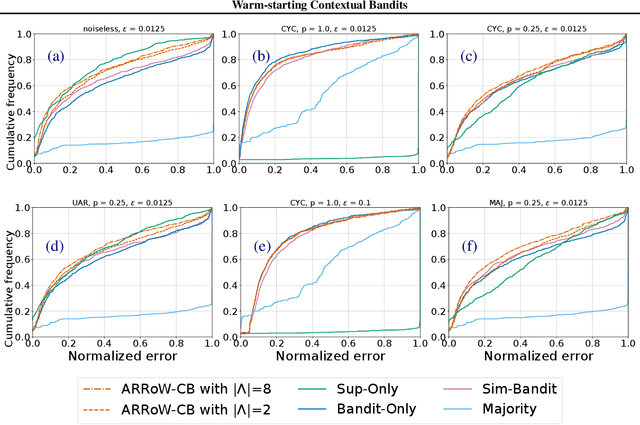
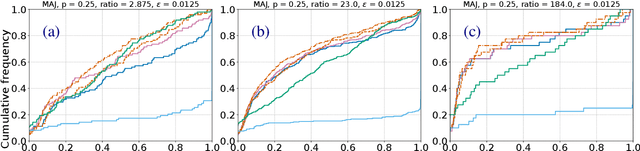
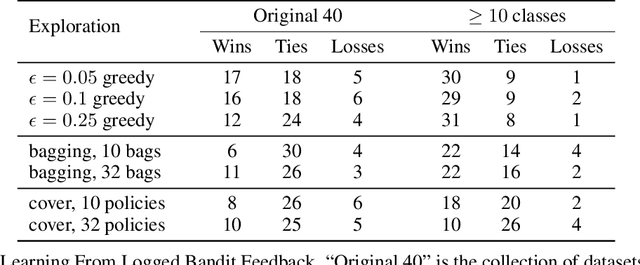
We investigate the feasibility of learning from both fully-labeled supervised data and contextual bandit data. We specifically consider settings in which the underlying learning signal may be different between these two data sources. Theoretically, we state and prove no-regret algorithms for learning that is robust to divergences between the two sources. Empirically, we evaluate some of these algorithms on a large selection of datasets, showing that our approaches are feasible, and helpful in practice.
Model-Based Reinforcement Learning in Contextual Decision Processes
Nov 21, 2018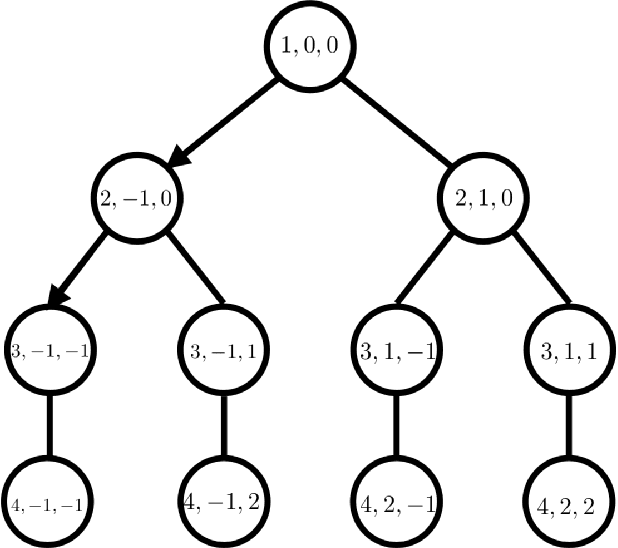
We study the sample complexity of model-based reinforcement learning in general contextual decision processes. We design new algorithms for RL with an abstract model class and analyze their statistical properties. Our algorithms have sample complexity governed by a new structural parameter called the witness rank, which we show to be small in several settings of interest, including Factored MDPs and reactive POMDPs. We also show that the witness rank of a problem is never larger than the recently proposed Bellman rank parameter governing the sample complexity of the model-free algorithm OLIVE (Jiang et al., 2017), the only other provably sample efficient algorithm at this level of generality. Focusing on the special case of Factored MDPs, we prove an exponential lower bound for all model-free approaches, including OLIVE, which when combined with our algorithmic results demonstrates exponential separation between model-based and model-free RL in some rich-observation settings.
On Oracle-Efficient PAC RL with Rich Observations
Oct 31, 2018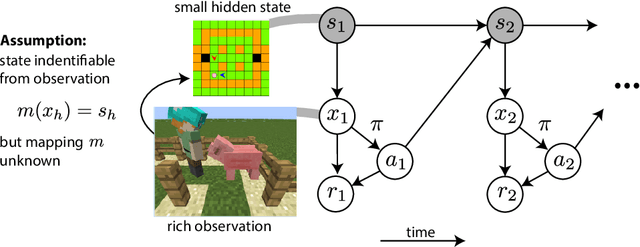
We study the computational tractability of PAC reinforcement learning with rich observations. We present new provably sample-efficient algorithms for environments with deterministic hidden state dynamics and stochastic rich observations. These methods operate in an oracle model of computation -- accessing policy and value function classes exclusively through standard optimization primitives -- and therefore represent computationally efficient alternatives to prior algorithms that require enumeration. With stochastic hidden state dynamics, we prove that the only known sample-efficient algorithm, OLIVE, cannot be implemented in the oracle model. We also present several examples that illustrate fundamental challenges of tractable PAC reinforcement learning in such general settings.
Contextual Memory Trees
Jul 17, 2018

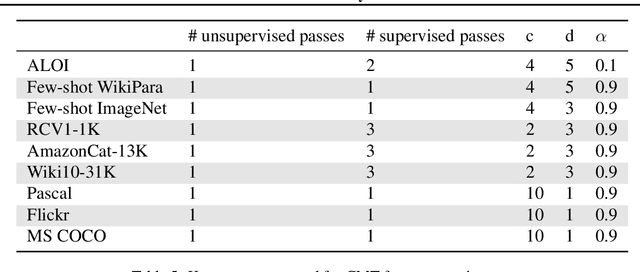
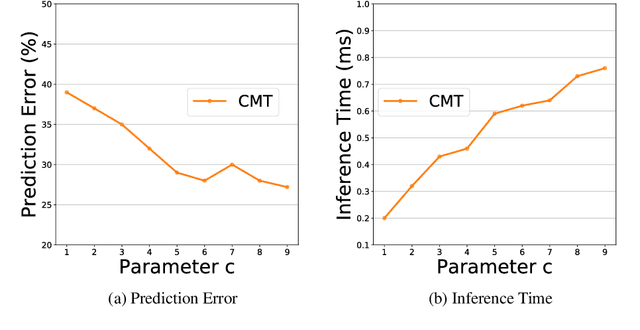
We design and study a Contextual Memory Tree (CMT), a learning memory controller that inserts new memories into an experience store of unbounded size. It is designed to efficiently query for memories from that store, supporting logarithmic time insertion and retrieval operations. Hence CMT can be integrated into existing statistical learning algorithms as an augmented memory unit without substantially increasing training and inference computation. We demonstrate the efficacy of CMT by augmenting existing multi-class and multi-label classification algorithms with CMT and observe statistical improvement. We also test CMT learning on several image-captioning tasks to demonstrate that it performs computationally better than a simple nearest neighbors memory system while benefitting from reward learning.
A Reductions Approach to Fair Classification
Jul 16, 2018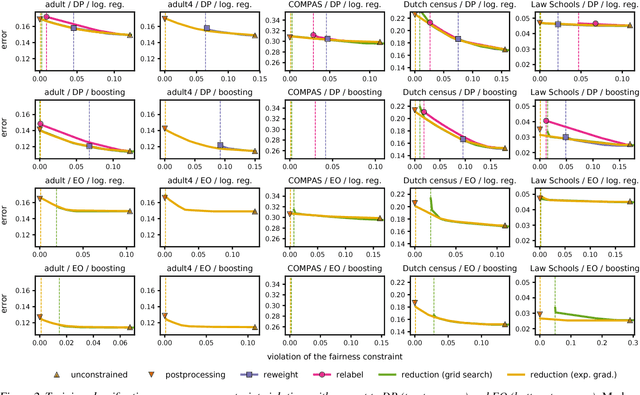
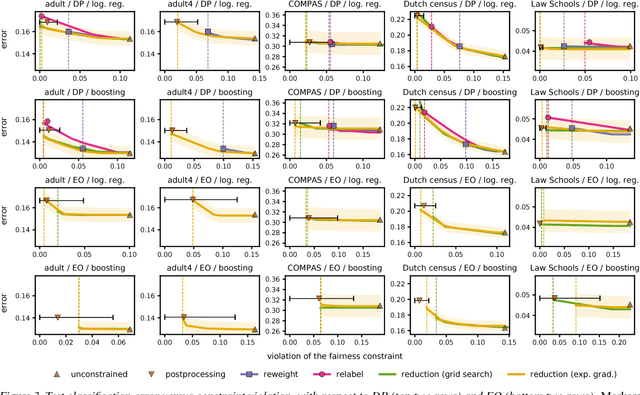
We present a systematic approach for achieving fairness in a binary classification setting. While we focus on two well-known quantitative definitions of fairness, our approach encompasses many other previously studied definitions as special cases. The key idea is to reduce fair classification to a sequence of cost-sensitive classification problems, whose solutions yield a randomized classifier with the lowest (empirical) error subject to the desired constraints. We introduce two reductions that work for any representation of the cost-sensitive classifier and compare favorably to prior baselines on a variety of data sets, while overcoming several of their disadvantages.