 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to use parametric models in reinforcement learning?
Jun 12, 2019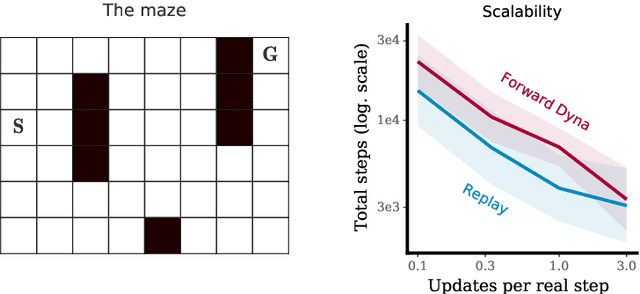
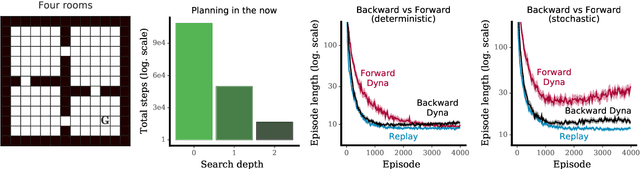

We examine the question of when and how parametric models are most useful in reinforcement learning. In particular, we look at commonalities and differences between parametric models and experience replay. Replay-based learning algorithms share important traits with model-based approaches, including the ability to plan: to use more computation without additional data to improve predictions and behaviour. We discuss when to expect benefits from either approach, and interpret prior work in this context. We hypothesise that, under suitable conditions, replay-based algorithms should be competitive to or better than model-based algorithms if the model is used only to generate fictional transitions from observed states for an update rule that is otherwise model-free. We validated this hypothesis on Atari 2600 video games. The replay-based algorithm attained state-of-the-art data efficiency, improving over prior results with parametric models.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019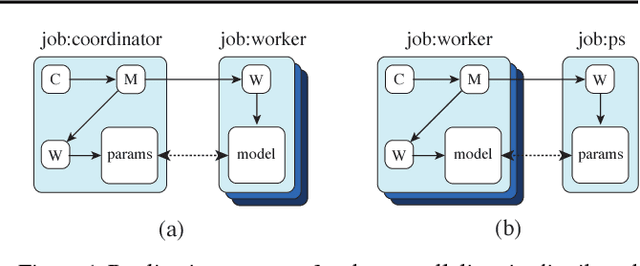

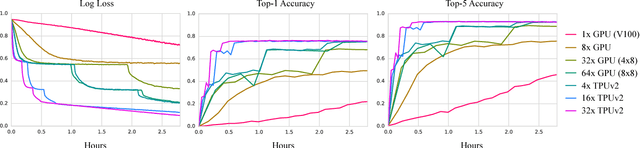
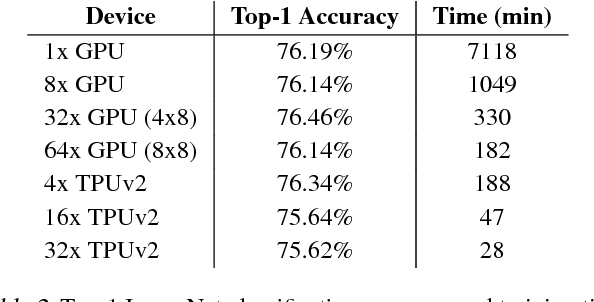
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
Randomized Prior Functions for Deep Reinforcement Learning
Jun 08, 2018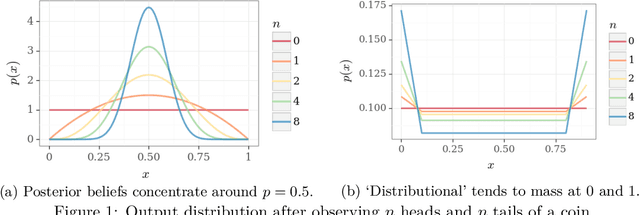
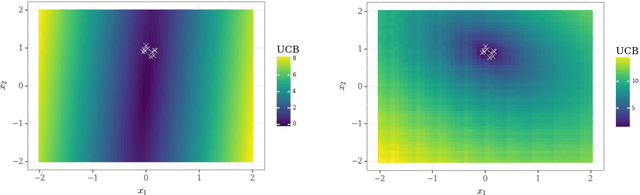
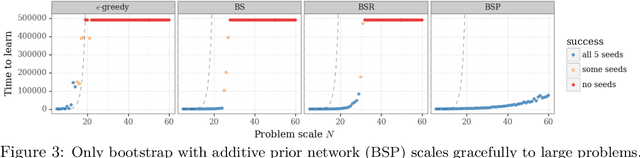
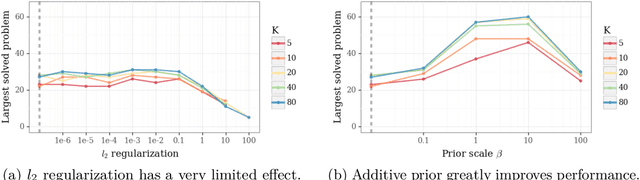
Dealing with uncertainty is essential for efficient reinforcement learning. There is a growing literature on uncertainty estimation for deep learning from fixed datasets, but many of the most popular approaches are poorly-suited to sequential decision problems. Other methods, such as bootstrap sampling, have no mechanism for uncertainty that does not come from the observed data. We highlight why this can be a crucial shortcoming and propose a simple remedy through addition of a randomized untrainable `prior' network to each ensemble member. We prove that this approach is efficient with linear representations, provide simple illustrations of its efficacy with nonlinear representations and show that this approach scales to large-scale problems far better than previous attempts.
Universal Reinforcement Learning Algorithms: Survey and Experiments
May 30, 2017
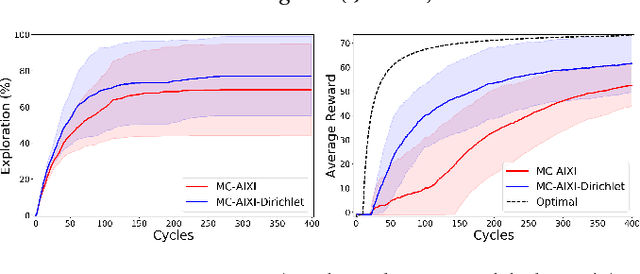
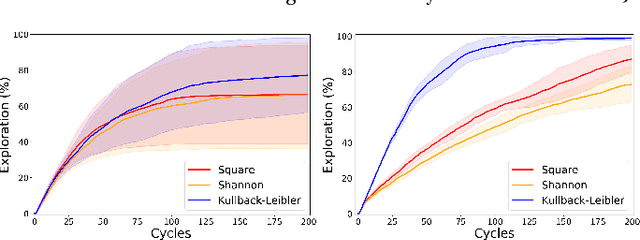

Many state-of-the-art reinforcement learning (RL) algorithms typically assume that the environment is an ergodic Markov Decision Process (MDP). In contrast, the field of universal reinforcement learning (URL) is concerned with algorithms that make as few assumptions as possible about the environment. The universal Bayesian agent AIXI and a family of related URL algorithms have been developed in this setting. While numerous theoretical optimality results have been proven for these agents, there has been no empirical investigation of their behavior to date. We present a short and accessible survey of these URL algorithms under a unified notation and framework, along with results of some experiments that qualitatively illustrate some properties of the resulting policies, and their relative performance on partially-observable gridworld environments. We also present an open-source reference implementation of the algorithms which we hope will facilitate further understanding of, and experimentation with, these ideas.
AIXIjs: A Software Demo for General Reinforcement Learning
May 22, 2017
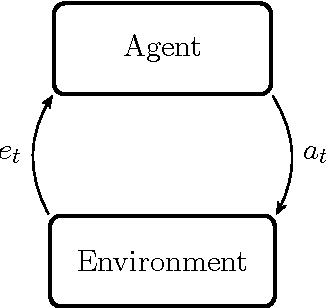
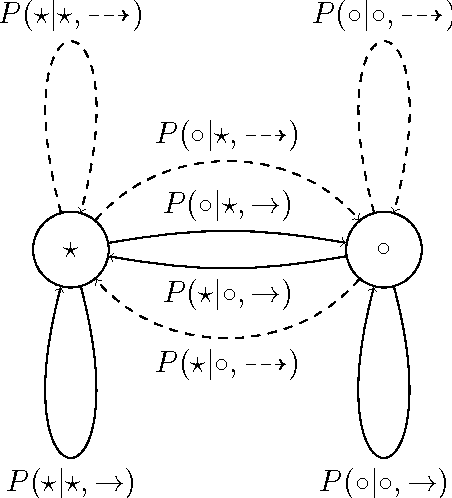
Reinforcement learning is a general and powerful framework with which to study and implement artificial intelligence. Recent advances in deep learning have enabled RL algorithms to achieve impressive performance in restricted domains such as playing Atari video games (Mnih et al., 2015) and, recently, the board game Go (Silver et al., 2016). However, we are still far from constructing a generally intelligent agent. Many of the obstacles and open questions are conceptual: What does it mean to be intelligent? How does one explore and learn optimally in general, unknown environments? What, in fact, does it mean to be optimal in the general sense? The universal Bayesian agent AIXI (Hutter, 2005) is a model of a maximally intelligent agent, and plays a central role in the sub-field of general reinforcement learning (GRL). Recently, AIXI has been shown to be flawed in important ways; it doesn't explore enough to be asymptotically optimal (Orseau, 2010), and it can perform poorly with certain priors (Leike and Hutter, 2015). Several variants of AIXI have been proposed to attempt to address these shortfalls: among them are entropy-seeking agents (Orseau, 2011), knowledge-seeking agents (Orseau et al., 2013), Bayes with bursts of exploration (Lattimore, 2013), MDL agents (Leike, 2016a), Thompson sampling (Leike et al., 2016), and optimism (Sunehag and Hutter, 2015). We present AIXIjs, a JavaScript implementation of these GRL agents. This implementation is accompanied by a framework for running experiments against various environments, similar to OpenAI Gym (Brockman et al., 2016), and a suite of interactive demos that explore different properties of the agents, similar to REINFORCEjs (Karpathy, 2015). We use AIXIjs to present numerous experiments illustrating fundamental properties of, and differences between, these agents.
Generalised Discount Functions applied to a Monte-Carlo AImu Implementation
Mar 03, 2017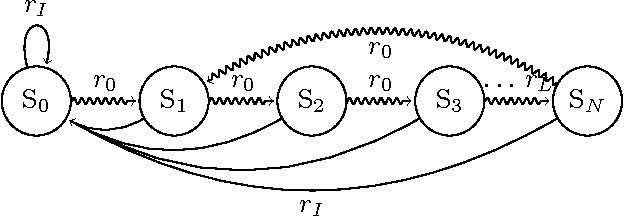
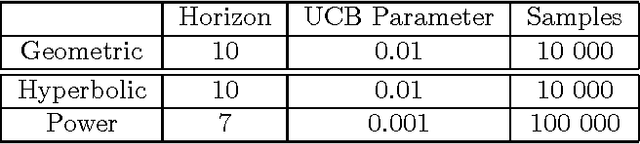
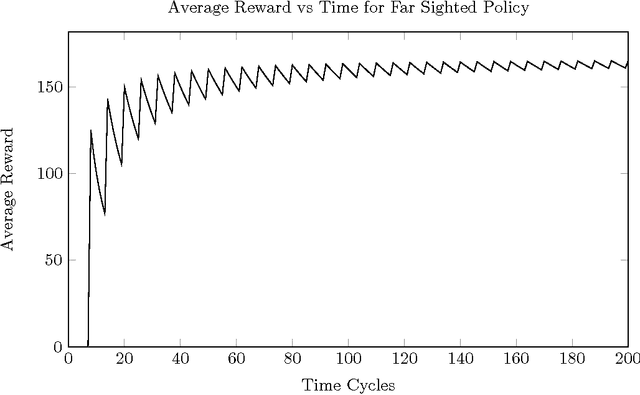
In recent years, work has been done to develop the theory of General Reinforcement Learning (GRL). However, there are few examples demonstrating these results in a concrete way. In particular, there are no examples demonstrating the known results regarding gener- alised discounting. We have added to the GRL simulation platform AIXIjs the functionality to assign an agent arbitrary discount functions, and an environment which can be used to determine the effect of discounting on an agent's policy. Using this, we investigate how geometric, hyperbolic and power discounting affect an informed agent in a simple MDP. We experimentally reproduce a number of theoretical results, and discuss some related subtleties. It was found that the agent's behaviour followed what is expected theoretically, assuming appropriate parameters were chosen for the Monte-Carlo Tree Search (MCTS) planning algorithm.