 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
1-Bit Wonder: Improving QAT Performance in the Low-Bit Regime through K-Means Quantization
Feb 17, 2026Quantization-aware training (QAT) is an effective method to drastically reduce the memory footprint of LLMs while keeping performance degradation at an acceptable level. However, the optimal choice of quantization format and bit-width presents a challenge in practice. The full design space of quantization is not fully explored in the context of QAT, and the precise trade-off between quantization and downstream performance is poorly understood, as comparisons often rely solely on perplexity-based evaluations. In this work, we address these shortcomings with an empirical study of QAT in the low-bit regime. We show that k-means based weight quantization outperforms integer formats and can be implemented efficiently on standard hardware. Furthermore, we find that, under a fixed inference memory budget, the best performance on generative downstream tasks is achieved with $1$-bit quantized weights.
Temporal Knowledge Graph Completion using Box Embeddings
Sep 18, 2021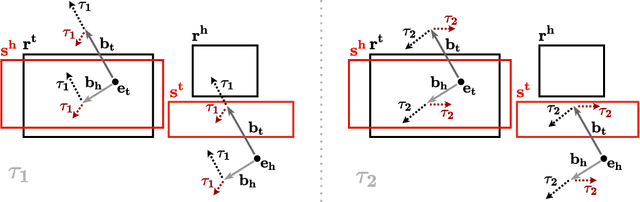

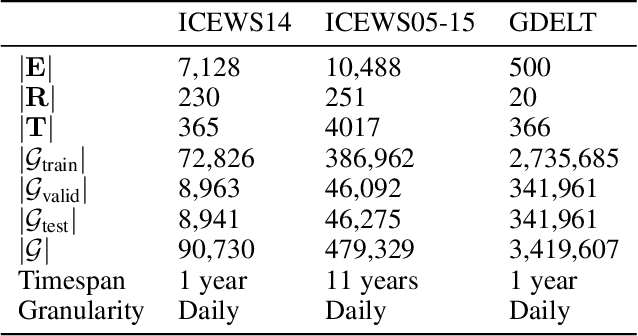
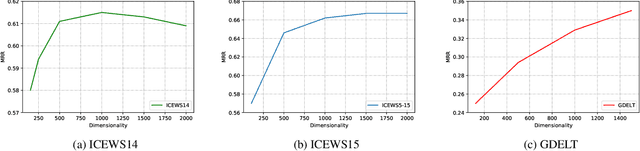
Knowledge graph completion is the task of inferring missing facts based on existing data in a knowledge graph. Temporal knowledge graph completion (TKGC) is an extension of this task to temporal knowledge graphs, where each fact is additionally associated with a time stamp. Current approaches for TKGC primarily build on existing embedding models which are developed for (static) knowledge graph completion, and extend these models to incorporate time, where the idea is to learn latent representations for entities, relations, and timestamps and then use the learned representations to predict missing facts at various time steps. In this paper, we propose BoxTE, a box embedding model for TKGC, building on the static knowledge graph embedding model BoxE. We show that BoxTE is fully expressive, and possesses strong inductive capacity in the temporal setting. We then empirically evaluate our model and show that it achieves state-of-the-art results on several TKGC benchmarks.