 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
V$^2$Dial: Unification of Video and Visual Dialog via Multimodal Experts
Mar 03, 2025We present V$^2$Dial - a novel expert-based model specifically geared towards simultaneously handling image and video input data for multimodal conversational tasks. Current multimodal models primarily focus on simpler tasks (e.g., VQA, VideoQA, video-text retrieval) and often neglect the more challenging conversational counterparts, such as video and visual/image dialog. Moreover, works on both conversational tasks evolved separately from each other despite their apparent similarities limiting their applicability potential. To this end, we propose to unify both tasks using a single model that for the first time jointly learns the spatial and temporal features of images and videos by routing them through dedicated experts and aligns them using matching and contrastive learning techniques. Furthermore, we systemically study the domain shift between the two tasks by investigating whether and to what extent these seemingly related tasks can mutually benefit from their respective training data. Extensive evaluations on the widely used video and visual dialog datasets of AVSD and VisDial show that our model achieves new state-of-the-art results across four benchmarks both in zero-shot and fine-tuning settings.
Multi-Modal Video Dialog State Tracking in the Wild
Jul 02, 2024We present MST-MIXER - a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.
Limits of Theory of Mind Modelling in Dialogue-Based Collaborative Plan Acquisition
May 21, 2024Recent work on dialogue-based collaborative plan acquisition (CPA) has suggested that Theory of Mind (ToM) modelling can improve missing knowledge prediction in settings with asymmetric skill-sets and knowledge. Although ToM was claimed to be important for effective collaboration, its real impact on this novel task remains under-explored. By representing plans as graphs and by exploiting task-specific constraints we show that, as performance on CPA nearly doubles when predicting one's own missing knowledge, the improvements due to ToM modelling diminish. This phenomenon persists even when evaluating existing baseline methods. To better understand the relevance of ToM for CPA, we report a principled performance comparison of models with and without ToM features. Results across different models and ablations consistently suggest that learned ToM features are indeed more likely to reflect latent patterns in the data with no perceivable link to ToM. This finding calls for a deeper understanding of the role of ToM in CPA and beyond, as well as new methods for modelling and evaluating mental states in computational collaborative agents.
OLViT: Multi-Modal State Tracking via Attention-Based Embeddings for Video-Grounded Dialog
Feb 20, 2024We present the Object Language Video Transformer (OLViT) - a novel model for video dialog operating over a multi-modal attention-based dialog state tracker. Existing video dialog models struggle with questions requiring both spatial and temporal localization within videos, long-term temporal reasoning, and accurate object tracking across multiple dialog turns. OLViT addresses these challenges by maintaining a global dialog state based on the output of an Object State Tracker (OST) and a Language State Tracker (LST): while the OST attends to the most important objects within the video, the LST keeps track of the most important linguistic co-references to previous dialog turns. In stark contrast to previous works, our approach is generic by nature and is therefore capable of learning continuous multi-modal dialog state representations of the most relevant objects and rounds. As a result, they can be seamlessly integrated into Large Language Models (LLMs) and offer high flexibility in dealing with different datasets and tasks. Evaluations on the challenging DVD (response classification) and SIMMC 2.1 (response generation) datasets show that OLViT achieves new state-of-the-art performance across both datasets.
$\mathbb{VD}$-$\mathbb{GR}$: Boosting $\mathbb{V}$isual $\mathbb{D}$ialog with Cascaded Spatial-Temporal Multi-Modal $\mathbb{GR}$aphs
Oct 25, 2023We propose $\mathbb{VD}$-$\mathbb{GR}$ - a novel visual dialog model that combines pre-trained language models (LMs) with graph neural networks (GNNs). Prior works mainly focused on one class of models at the expense of the other, thus missing out on the opportunity of combining their respective benefits. At the core of $\mathbb{VD}$-$\mathbb{GR}$ is a novel integration mechanism that alternates between spatial-temporal multi-modal GNNs and BERT layers, and that covers three distinct contributions: First, we use multi-modal GNNs to process the features of each modality (image, question, and dialog history) and exploit their local structures before performing BERT global attention. Second, we propose hub-nodes that link to all other nodes within one modality graph, allowing the model to propagate information from one GNN (modality) to the other in a cascaded manner. Third, we augment the BERT hidden states with fine-grained multi-modal GNN features before passing them to the next $\mathbb{VD}$-$\mathbb{GR}$ layer. Evaluations on VisDial v1.0, VisDial v0.9, VisDialConv, and VisPro show that $\mathbb{VD}$-$\mathbb{GR}$ achieves new state-of-the-art results across all four datasets.
Neuro-Symbolic Visual Dialog
Aug 22, 2022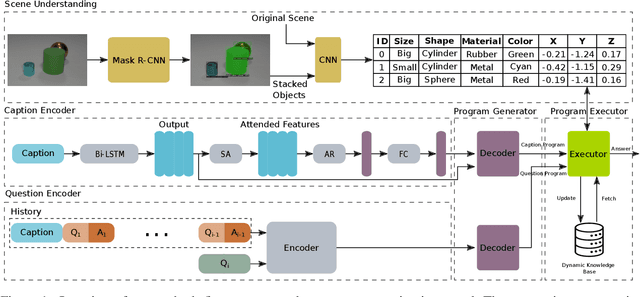
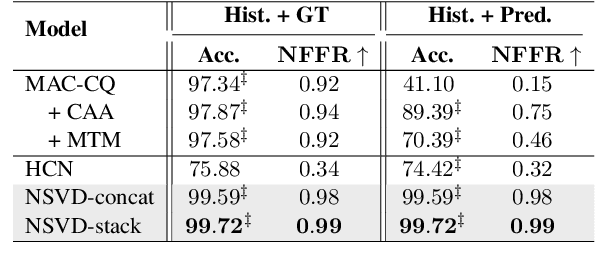
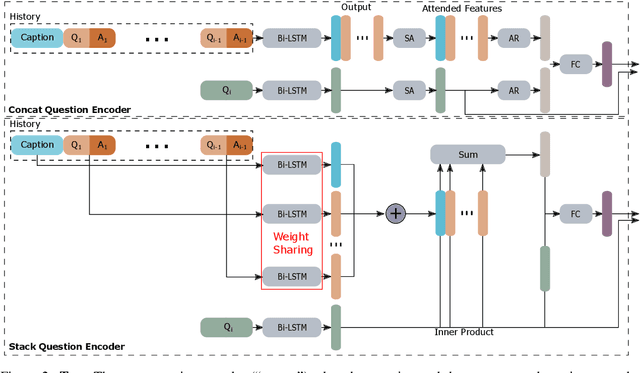
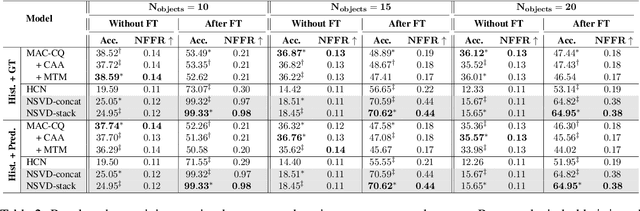
We propose Neuro-Symbolic Visual Dialog (NSVD) -the first method to combine deep learning and symbolic program execution for multi-round visually-grounded reasoning. NSVD significantly outperforms existing purely-connectionist methods on two key challenges inherent to visual dialog: long-distance co-reference resolution as well as vanishing question-answering performance. We demonstrate the latter by proposing a more realistic and stricter evaluation scheme in which we use predicted answers for the full dialog history when calculating accuracy. We describe two variants of our model and show that using this new scheme, our best model achieves an accuracy of 99.72% on CLEVR-Dialog -a relative improvement of more than 10% over the state of the art while only requiring a fraction of training data. Moreover, we demonstrate that our neuro-symbolic models have a higher mean first failure round, are more robust against incomplete dialog histories, and generalise better not only to dialogs that are up to three times longer than those seen during training but also to unseen question types and scenes.