 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Imbalanced Learning
Nov 01, 2022Automated Machine Learning has grown very successful in automating the time-consuming, iterative tasks of machine learning model development. However, current methods struggle when the data is imbalanced. Since many real-world datasets are naturally imbalanced, and improper handling of this issue can lead to quite useless models, this issue should be handled carefully. This paper first introduces a new benchmark to study how different AutoML methods are affected by label imbalance. Second, we propose strategies to better deal with imbalance and integrate them into an existing AutoML framework. Finally, we present a systematic study which evaluates the impact of these strategies and find that their inclusion in AutoML systems significantly increases their robustness against label imbalance.
Evaluating Continual Test-Time Adaptation for Contextual and Semantic Domain Shifts
Aug 18, 2022
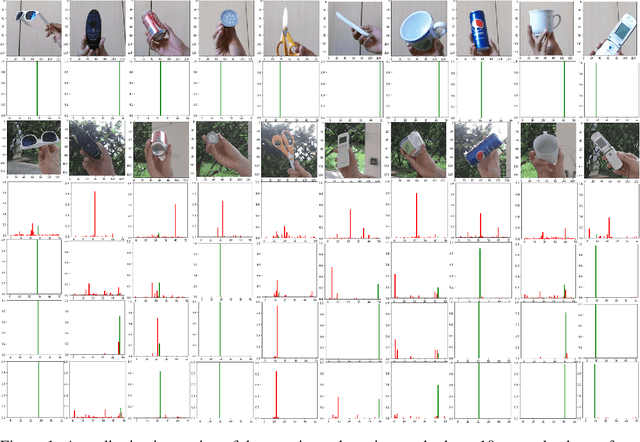

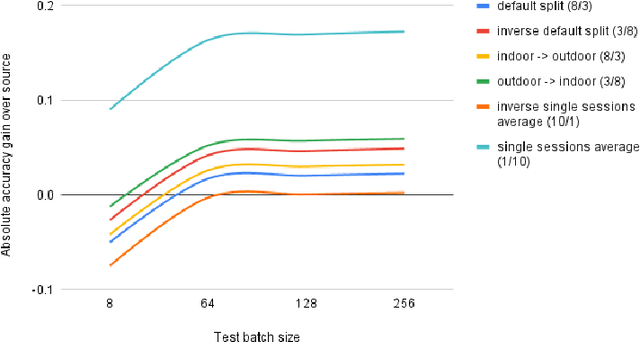
In this paper, our goal is to adapt a pre-trained Convolutional Neural Network to domain shifts at test time. We do so continually with the incoming stream of test batches, without labels. Existing literature mostly operates on artificial shifts obtained via adversarial perturbations of a test image. Motivated by this, we evaluate the state of the art on two realistic and challenging sources of domain shifts, namely contextual and semantic shifts. Contextual shifts correspond to the environment types, for example a model pre-trained on indoor context has to adapt to the outdoor context on CORe-50 [7]. Semantic shifts correspond to the capture types, for example a model pre-trained on natural images has to adapt to cliparts, sketches and paintings on DomainNet [10]. We include in our analysis recent techniques such as Prediction-Time Batch Normalization (BN) [8], Test Entropy Minimization (TENT) [16] and Continual Test-Time Adaptation (CoTTA) [17]. Our findings are three-fold: i) Test-time adaptation methods perform better and forget less on contextual shifts compared to semantic shifts, ii) TENT outperforms other methods on short-term adaptation, whereas CoTTA outpeforms other methods on long-term adaptation, iii) BN is most reliable and robust.
AMLB: an AutoML Benchmark
Jul 25, 2022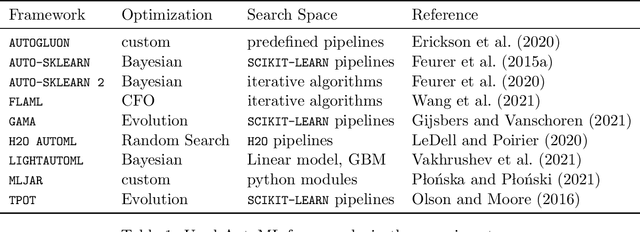
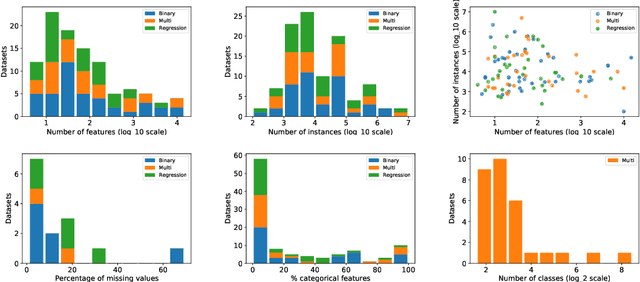
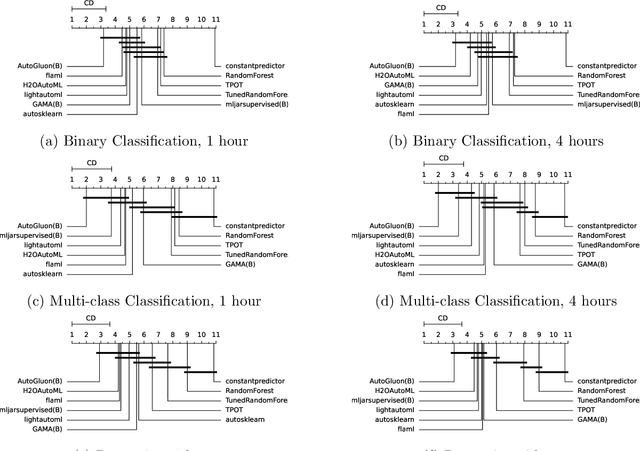
Comparing different AutoML frameworks is notoriously challenging and often done incorrectly. We introduce an open and extensible benchmark that follows best practices and avoids common mistakes when comparing AutoML frameworks. We conduct a thorough comparison of 9 well-known AutoML frameworks across 71 classification and 33 regression tasks. The differences between the AutoML frameworks are explored with a multi-faceted analysis, evaluating model accuracy, its trade-offs with inference time, and framework failures. We also use Bradley-Terry trees to discover subsets of tasks where the relative AutoML framework rankings differ. The benchmark comes with an open-source tool that integrates with many AutoML frameworks and automates the empirical evaluation process end-to-end: from framework installation and resource allocation to in-depth evaluation. The benchmark uses public data sets, can be easily extended with other AutoML frameworks and tasks, and has a website with up-to-date results.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
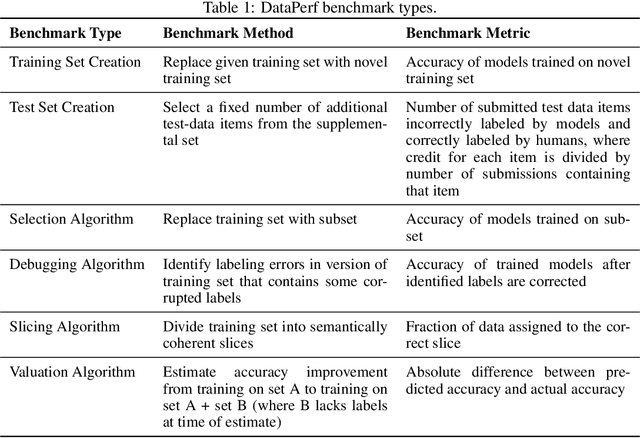
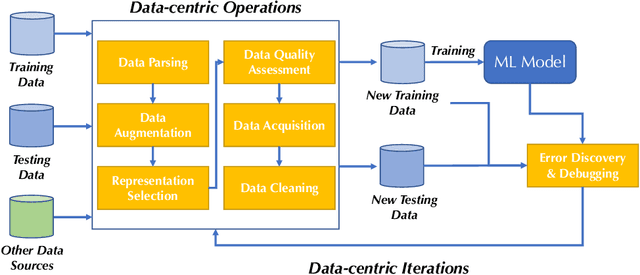
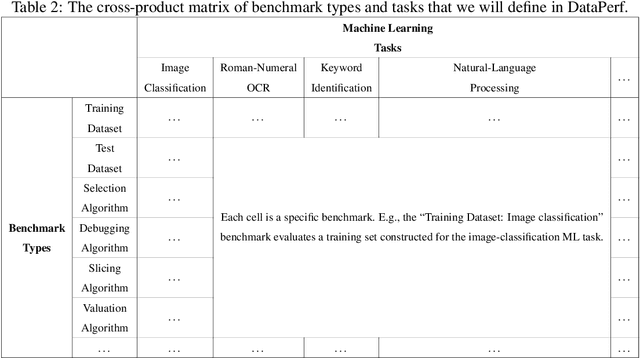
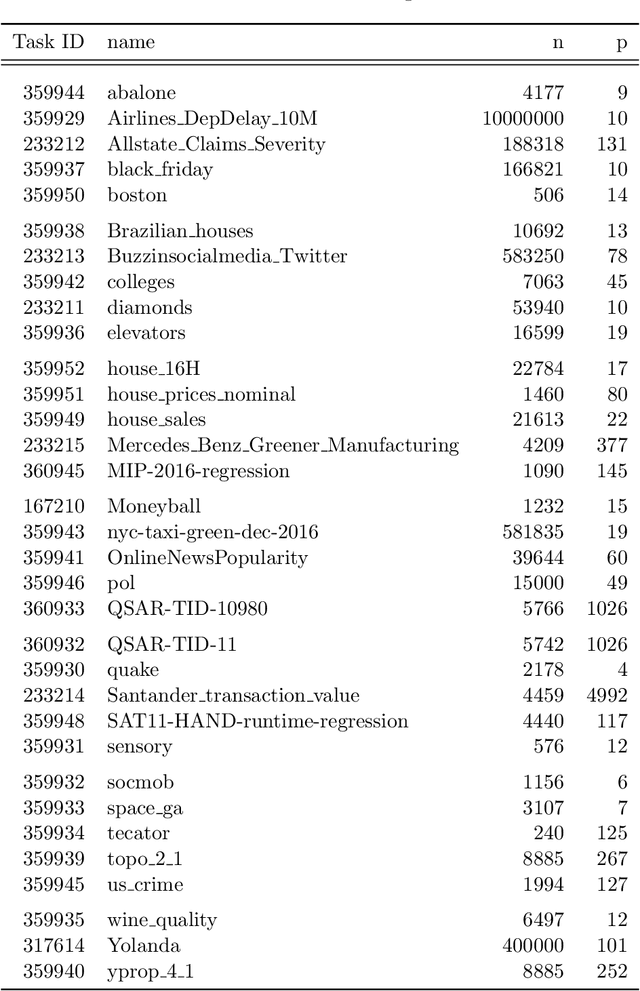
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Open-Ended Learning Strategies for Learning Complex Locomotion Skills
Jun 14, 2022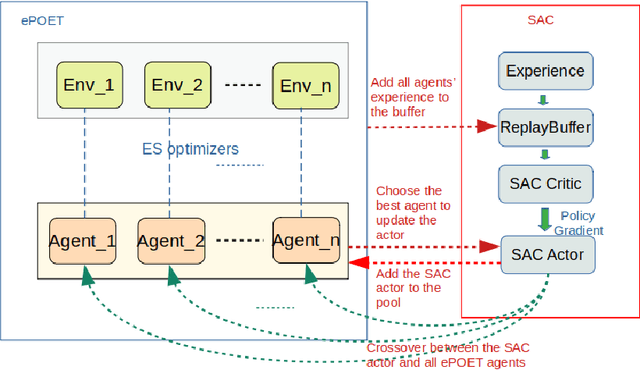

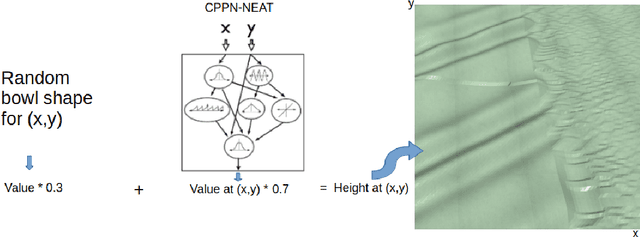
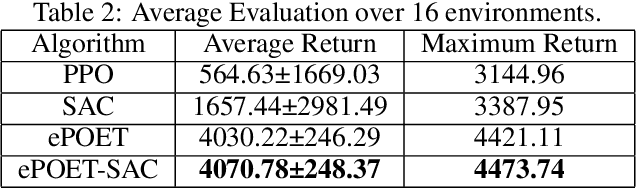
Teaching robots to learn diverse locomotion skills under complex three-dimensional environmental settings via Reinforcement Learning (RL) is still challenging. It has been shown that training agents in simple settings before moving them on to complex settings improves the training process, but so far only in the context of relatively simple locomotion skills. In this work, we adapt the Enhanced Paired Open-Ended Trailblazer (ePOET) approach to train more complex agents to walk efficiently on complex three-dimensional terrains. First, to generate more rugged and diverse three-dimensional training terrains with increasing complexity, we extend the Compositional Pattern Producing Networks - Neuroevolution of Augmenting Topologies (CPPN-NEAT) approach and include randomized shapes. Second, we combine ePOET with Soft Actor-Critic off-policy optimization, yielding ePOET-SAC, to ensure that the agent could learn more diverse skills to solve more challenging tasks. Our experimental results show that the newly generated three-dimensional terrains have sufficient diversity and complexity to guide learning, that ePOET successfully learns complex locomotion skills on these terrains, and that our proposed ePOET-SAC approach slightly improves upon ePOET.
Warm-starting DARTS using meta-learning
May 12, 2022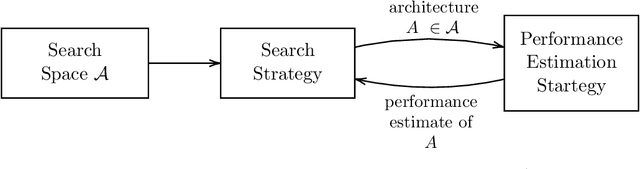

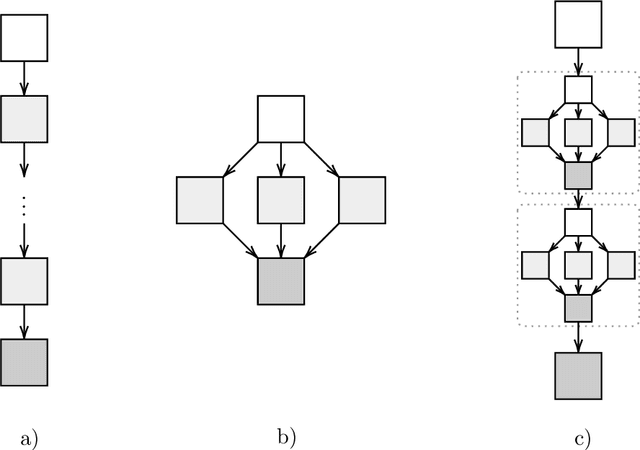
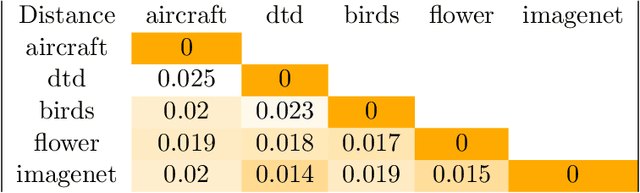
Neural architecture search (NAS) has shown great promise in the field of automated machine learning (AutoML). NAS has outperformed hand-designed networks and made a significant step forward in the field of automating the design of deep neural networks, thus further reducing the need for human expertise. However, most research is done targeting a single specific task, leaving research of NAS methods over multiple tasks mostly overlooked. Generally, there exist two popular ways to find an architecture for some novel task. Either searching from scratch, which is ineffective by design, or transferring discovered architectures from other tasks, which provides no performance guarantees and is probably not optimal. In this work, we present a meta-learning framework to warm-start Differentiable architecture search (DARTS). DARTS is a NAS method that can be initialized with a transferred architecture and is able to quickly adapt to new tasks. A task similarity measure is used to determine which transfer architecture is selected, as transfer architectures found on similar tasks will likely perform better. Additionally, we employ a simple meta-transfer architecture that was learned over multiple tasks. Experiments show that warm-started DARTS is able to find competitive performing architectures while reducing searching costs on average by 60%.
Advances in MetaDL: AAAI 2021 challenge and workshop
Feb 01, 2022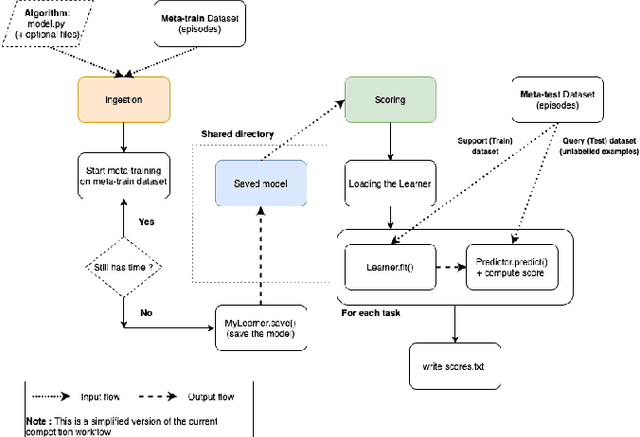


To stimulate advances in metalearning using deep learning techniques (MetaDL), we organized in 2021 a challenge and an associated workshop. This paper presents the design of the challenge and its results, and summarizes presentations made at the workshop. The challenge focused on few-shot learning classification tasks of small images. Participants' code submissions were run in a uniform manner, under tight computational constraints. This put pressure on solution designs to use existing architecture backbones and/or pre-trained networks. Winning methods featured various classifiers trained on top of the second last layer of popular CNN backbones, fined-tuned on the meta-training data (not necessarily in an episodic manner), then trained on the labeled support and tested on the unlabeled query sets of the meta-test data.
Online AutoML: An adaptive AutoML framework for online learning
Jan 24, 2022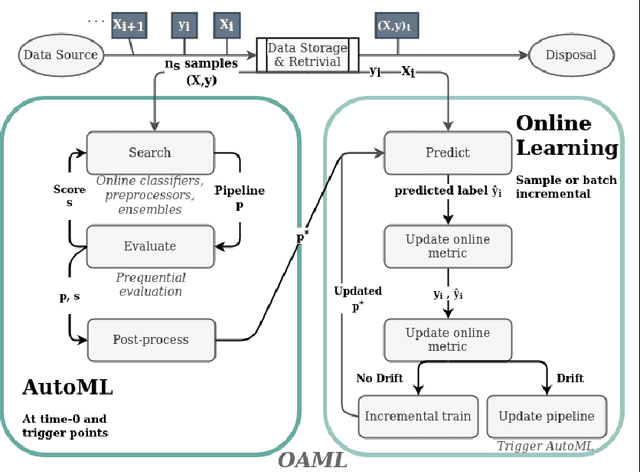
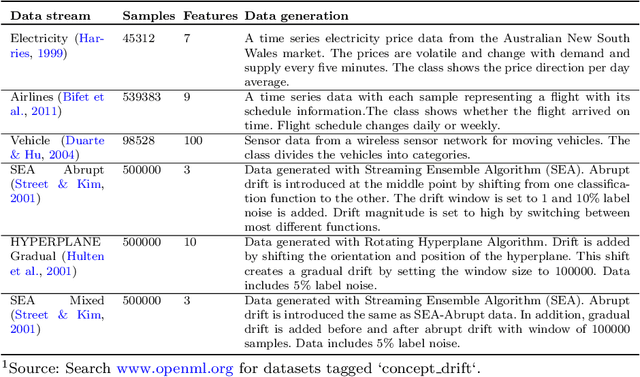
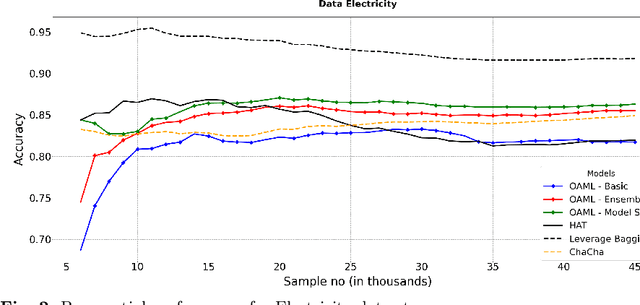
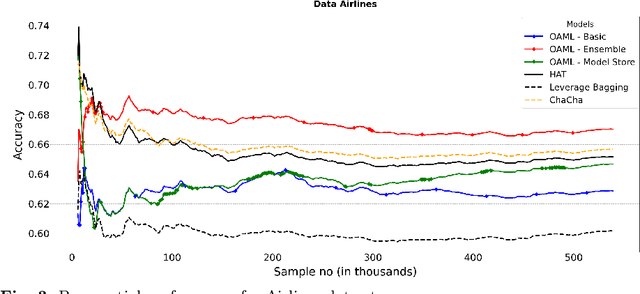
Automated Machine Learning (AutoML) has been used successfully in settings where the learning task is assumed to be static. In many real-world scenarios, however, the data distribution will evolve over time, and it is yet to be shown whether AutoML techniques can effectively design online pipelines in dynamic environments. This study aims to automate pipeline design for online learning while continuously adapting to data drift. For this purpose, we design an adaptive Online Automated Machine Learning (OAML) system, searching the complete pipeline configuration space of online learners, including preprocessing algorithms and ensembling techniques. This system combines the inherent adaptation capabilities of online learners with the fast automated pipeline (re)optimization capabilities of AutoML. Focusing on optimization techniques that can adapt to evolving objectives, we evaluate asynchronous genetic programming and asynchronous successive halving to optimize these pipelines continually. We experiment on real and artificial data streams with varying types of concept drift to test the performance and adaptation capabilities of the proposed system. The results confirm the utility of OAML over popular online learning algorithms and underscore the benefits of continuous pipeline redesign in the presence of data drift.
Automated Reinforcement Learning: An Overview
Jan 13, 2022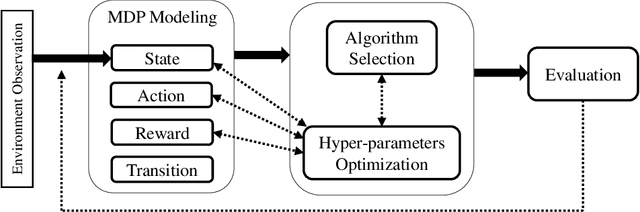
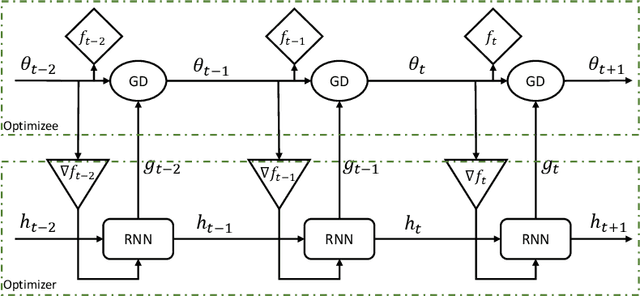
Reinforcement Learning and recently Deep Reinforcement Learning are popular methods for solving sequential decision making problems modeled as Markov Decision Processes. RL modeling of a problem and selecting algorithms and hyper-parameters require careful considerations as different configurations may entail completely different performances. These considerations are mainly the task of RL experts; however, RL is progressively becoming popular in other fields where the researchers and system designers are not RL experts. Besides, many modeling decisions, such as defining state and action space, size of batches and frequency of batch updating, and number of timesteps are typically made manually. For these reasons, automating different components of RL framework is of great importance and it has attracted much attention in recent years. Automated RL provides a framework in which different components of RL including MDP modeling, algorithm selection and hyper-parameter optimization are modeled and defined automatically. In this article, we explore the literature and present recent work that can be used in automated RL. Moreover, we discuss the challenges, open questions and research directions in AutoRL.
Frugal Machine Learning
Nov 05, 2021
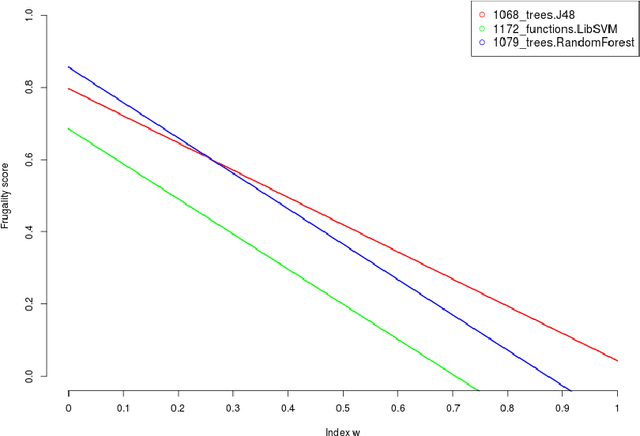
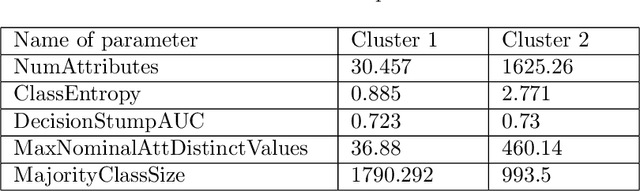
Machine learning, already at the core of increasingly many systems and applications, is set to become even more ubiquitous with the rapid rise of wearable devices and the Internet of Things. In most machine learning applications, the main focus is on the quality of the results achieved (e.g., prediction accuracy), and hence vast amounts of data are being collected, requiring significant computational resources to build models. In many scenarios, however, it is infeasible or impractical to set up large centralized data repositories. In personal health, for instance, privacy issues may inhibit the sharing of detailed personal data. In such cases, machine learning should ideally be performed on wearable devices themselves, which raises major computational limitations such as the battery capacity of smartwatches. This paper thus investigates frugal learning, aimed to build the most accurate possible models using the least amount of resources. A wide range of learning algorithms is examined through a frugal lens, analyzing their accuracy/runtime performance on a wide range of data sets. The most promising algorithms are thereafter assessed in a real-world scenario by implementing them in a smartwatch and letting them learn activity recognition models on the watch itself.