 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISC: Dense Integrated Semantic Context for Large-Scale Open-Set Semantic Mapping
Mar 04, 2026Open-set semantic mapping enables language-driven robotic perception, but current instance-centric approaches are bottlenecked by context-depriving and computationally expensive crop-based feature extraction. To overcome this fundamental limitation, we introduce DISC (Dense Integrated Semantic Context), featuring a novel single-pass, distance-weighted extraction mechanism. By deriving high-fidelity CLIP embeddings directly from the vision transformer's intermediate layers, our approach eliminates the latency and domain-shift artifacts of traditional image cropping, yielding pure, mask-aligned semantic representations. To fully leverage these features in large-scale continuous mapping, DISC is built upon a fully GPU-accelerated architecture that replaces periodic offline processing with precise, on-the-fly voxel-level instance refinement. We evaluate our approach on standard benchmarks (Replica, ScanNet) and a newly generated large-scale-mapping dataset based on Habitat-Matterport 3D (HM3DSEM) to assess scalability across complex scenes in multi-story buildings. Extensive evaluations demonstrate that DISC significantly surpasses current state-of-the-art zero-shot methods in both semantic accuracy and query retrieval, providing a robust, real-time capable framework for robotic deployment. The full source code, data generation and evaluation pipelines will be made available at https://github.com/DFKI-NI/DISC.
Agentic AI for Robot Control: Flexible but still Fragile
Feb 13, 2026Recent work leverages the capabilities and commonsense priors of generative models for robot control. In this paper, we present an agentic control system in which a reasoning-capable language model plans and executes tasks by selecting and invoking robot skills within an iterative planner and executor loop. We deploy the system on two physical robot platforms in two settings: (i) tabletop grasping, placement, and box insertion in indoor mobile manipulation (Mobipick) and (ii) autonomous agricultural navigation and sensing (Valdemar). Both settings involve uncertainty, partial observability, sensor noise, and ambiguous natural-language commands. The system exposes structured introspection of its planning and decision process, reacts to exogenous events via explicit event checks, and supports operator interventions that modify or redirect ongoing execution. Across both platforms, our proof-of-concept experiments reveal substantial fragility, including non-deterministic suboptimal behavior, instruction-following errors, and high sensitivity to prompt specification. At the same time, the architecture is flexible: transfer to a different robot and task domain largely required updating the system prompt (domain model, affordances, and action catalogue) and re-binding the same tool interface to the platform-specific skill API.
Uncertainty-Resilient Active Intention Recognition for Robotic Assistants
Aug 26, 2025



Purposeful behavior in robotic assistants requires the integration of multiple components and technological advances. Often, the problem is reduced to recognizing explicit prompts, which limits autonomy, or is oversimplified through assumptions such as near-perfect information. We argue that a critical gap remains unaddressed -- specifically, the challenge of reasoning about the uncertain outcomes and perception errors inherent to human intention recognition. In response, we present a framework designed to be resilient to uncertainty and sensor noise, integrating real-time sensor data with a combination of planners. Centered around an intention-recognition POMDP, our approach addresses cooperative planning and acting under uncertainty. Our integrated framework has been successfully tested on a physical robot with promising results.
Acting and Planning with Hierarchical Operational Models on a Mobile Robot: A Study with RAE+UPOM
Jul 15, 2025



Robotic task execution faces challenges due to the inconsistency between symbolic planner models and the rich control structures actually running on the robot. In this paper, we present the first physical deployment of an integrated actor-planner system that shares hierarchical operational models for both acting and planning, interleaving the Reactive Acting Engine (RAE) with an anytime UCT-like Monte Carlo planner (UPOM). We implement RAE+UPOM on a mobile manipulator in a real-world deployment for an object collection task. Our experiments demonstrate robust task execution under action failures and sensor noise, and provide empirical insights into the interleaved acting-and-planning decision making process.
Online Knowledge Integration for 3D Semantic Mapping: A Survey
Nov 27, 2024



Semantic mapping is a key component of robots operating in and interacting with objects in structured environments. Traditionally, geometric and knowledge representations within a semantic map have only been loosely integrated. However, recent advances in deep learning now allow full integration of prior knowledge, represented as knowledge graphs or language concepts, into sensor data processing and semantic mapping pipelines. Semantic scene graphs and language models enable modern semantic mapping approaches to incorporate graph-based prior knowledge or to leverage the rich information in human language both during and after the mapping process. This has sparked substantial advances in semantic mapping, leading to previously impossible novel applications. This survey reviews these recent developments comprehensively, with a focus on online integration of knowledge into semantic mapping. We specifically focus on methods using semantic scene graphs for integrating symbolic prior knowledge and language models for respective capture of implicit common-sense knowledge and natural language concepts
Towards Intention Recognition for Robotic Assistants Through Online POMDP Planning
Nov 26, 2024


Intention recognition, or the ability to anticipate the actions of another agent, plays a vital role in the design and development of automated assistants that can support humans in their daily tasks. In particular, industrial settings pose interesting challenges that include potential distractions for a decision-maker as well as noisy or incomplete observations. In such a setting, a robotic assistant tasked with helping and supporting a human worker must interleave information gathering actions with proactive tasks of its own, an approach that has been referred to as active goal recognition. In this paper we describe a partially observable model for online intention recognition, show some preliminary experimental results and discuss some of the challenges present in this family of problems.
Mesh-based Object Tracking for Dynamic Semantic 3D Scene Graphs via Ray Tracing
Aug 09, 2024



In this paper, we present a novel method for 3D geometric scene graph generation using range sensors and RGB cameras. We initially detect instance-wise keypoints with a YOLOv8s model to compute 6D pose estimates of known objects by solving PnP. We use a ray tracing approach to track a geometric scene graph consisting of mesh models of object instances. In contrast to classical point-to-point matching, this leads to more robust results, especially under occlusions between objects instances. We show that using this hybrid strategy leads to robust self-localization, pre-segmentation of the range sensor data and accurate pose tracking of objects using the same environmental representation. All detected objects are integrated into a semantic scene graph. This scene graph then serves as a front end to a semantic mapping framework to allow spatial reasoning.
RadaRays: Real-time Simulation of Rotating FMCW Radar for Mobile Robotics via Hardware-accelerated Ray Tracing
Oct 05, 2023



RadaRays allows for the accurate modeling and simulation of rotating FMCW radar sensors in complex environments, including the simulation of reflection, refraction, and scattering of radar waves. Our software is able to handle large numbers of objects and materials, making it suitable for use in a variety of mobile robotics applications. We demonstrate the effectiveness of RadaRays through a series of experiments and show that it can more accurately reproduce the behavior of FMCW radar sensors in a variety of environments, compared to the ray casting-based lidar-like simulations that are commonly used in simulators for autonomous driving such as CARLA. Our experiments additionally serve as valuable reference point for researchers to evaluate their own radar simulations. By using RadaRays, developers can significantly reduce the time and cost associated with prototyping and testing FMCW radar-based algorithms. We also provide a Gazebo plugin that makes our work accessible to the mobile robotics community.
MICP-L: Fast parallel simulative Range Sensor to Mesh registration for Robot Localization
Oct 25, 2022



Triangle mesh-based maps have proven to be a powerful 3D representation of the environment, allowing robots to navigate using universal methods, indoors as well as in challenging outdoor environments with tunnels, hills and varying slopes. However, any robot that navigates autonomously necessarily requires stable, accurate, and continuous localization in such a mesh map where it plans its paths and missions. We present MICP-L, a novel and very fast \textit{Mesh ICP Localization} method that can register one or more range sensors directly on a triangle mesh map to continuously localize a robot, determining its 6D pose in the map. Correspondences between a range sensor and the mesh are found through simulations accelerated with the latest RTX hardware. With MICP-L, a correction can be performed quickly and in parallel even with combined data from different range sensor models. With this work, we aim to significantly advance the development in the field of mesh-based environment representation for autonomous robotic applications. MICP-L is open source and fully integrated with ROS and tf.
Rmagine: 3D Range Sensor Simulation in Polygonal Maps via Raytracing for Embedded Hardware on Mobile Robots
Sep 27, 2022
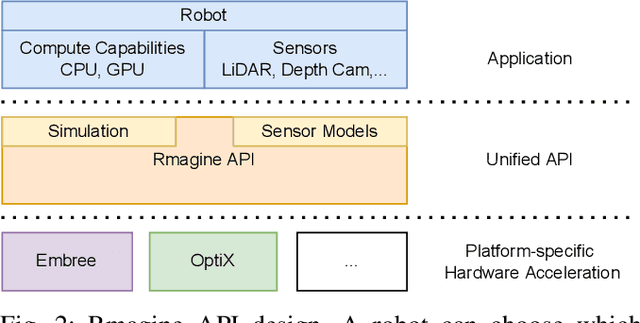
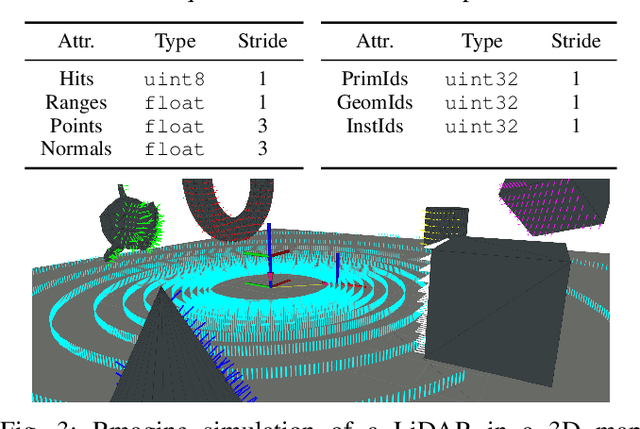
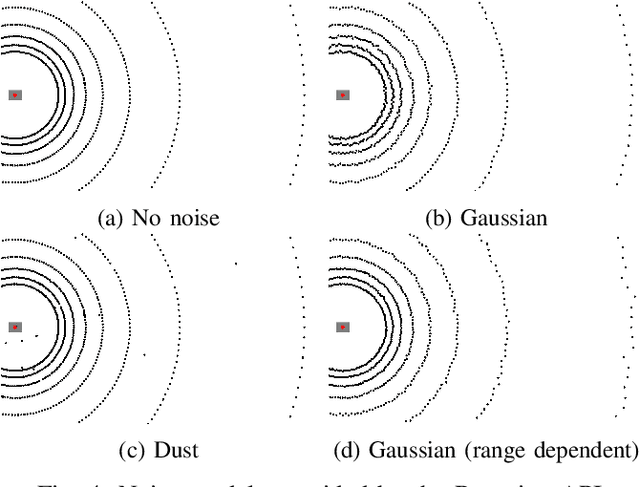
Sensor simulation has emerged as a promising and powerful technique to find solutions to many real-world robotic tasks like localization and pose tracking.However, commonly used simulators have high hardware requirements and are therefore used mostly on high-end computers. In this paper, we present an approach to simulate range sensors directly on embedded hardware of mobile robots that use triangle meshes as environment map. This library called Rmagine allows a robot to simulate sensor data for arbitrary range sensors directly on board via raytracing. Since robots typically only have limited computational resources, the Rmagine aims at being flexible and lightweight, while scaling well even to large environment maps. It runs on several platforms like Laptops or embedded computing boards like Nvidia Jetson by putting an unified API over the specific proprietary libraries provided by the hardware manufacturers. This work is designed to support the future development of robotic applications depending on simulation of range data that could previously not be computed in reasonable time on mobile systems.