 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the truncation gap: challenges of learning on dynamic graphs with recurrent architectures
Dec 30, 2024



Systems characterized by evolving interactions, prevalent in social, financial, and biological domains, are effectively modeled as continuous-time dynamic graphs (CTDGs). To manage the scale and complexity of these graph datasets, machine learning (ML) approaches have become essential. However, CTDGs pose challenges for ML because traditional static graph methods do not naturally account for event timings. Newer approaches, such as graph recurrent neural networks (GRNNs), are inherently time-aware and offer advantages over static methods for CTDGs. However, GRNNs face another issue: the short truncation of backpropagation-through-time (BPTT), whose impact has not been properly examined until now. In this work, we demonstrate that this truncation can limit the learning of dependencies beyond a single hop, resulting in reduced performance. Through experiments on a novel synthetic task and real-world datasets, we reveal a performance gap between full backpropagation-through-time (F-BPTT) and the truncated backpropagation-through-time (T-BPTT) commonly used to train GRNN models. We term this gap the "truncation gap" and argue that understanding and addressing it is essential as the importance of CTDGs grows, discussing potential future directions for research in this area.
NRGBoost: Energy-Based Generative Boosted Trees
Oct 04, 2024



Despite the rise to dominance of deep learning in unstructured data domains, tree-based methods such as Random Forests (RF) and Gradient Boosted Decision Trees (GBDT) are still the workhorses for handling discriminative tasks on tabular data. We explore generative extensions of these popular algorithms with a focus on explicitly modeling the data density (up to a normalization constant), thus enabling other applications besides sampling. As our main contribution we propose an energy-based generative boosting algorithm that is analogous to the second order boosting implemented in popular packages like XGBoost. We show that, despite producing a generative model capable of handling inference tasks over any input variable, our proposed algorithm can achieve similar discriminative performance to GBDT on a number of real world tabular datasets, outperforming alternative generative approaches. At the same time, we show that it is also competitive with neural network based models for sampling.
RIFF: Inducing Rules for Fraud Detection from Decision Trees
Aug 23, 2024



Financial fraud is the cause of multi-billion dollar losses annually. Traditionally, fraud detection systems rely on rules due to their transparency and interpretability, key features in domains where decisions need to be explained. However, rule systems require significant input from domain experts to create and tune, an issue that rule induction algorithms attempt to mitigate by inferring rules directly from data. We explore the application of these algorithms to fraud detection, where rule systems are constrained to have a low false positive rate (FPR) or alert rate, by proposing RIFF, a rule induction algorithm that distills a low FPR rule set directly from decision trees. Our experiments show that the induced rules are often able to maintain or improve performance of the original models for low FPR tasks, while substantially reducing their complexity and outperforming rules hand-tuned by experts.
Adversarial training for tabular data with attack propagation
Jul 28, 2023Adversarial attacks are a major concern in security-centered applications, where malicious actors continuously try to mislead Machine Learning (ML) models into wrongly classifying fraudulent activity as legitimate, whereas system maintainers try to stop them. Adversarially training ML models that are robust against such attacks can prevent business losses and reduce the work load of system maintainers. In such applications data is often tabular and the space available for attackers to manipulate undergoes complex feature engineering transformations, to provide useful signals for model training, to a space attackers cannot access. Thus, we propose a new form of adversarial training where attacks are propagated between the two spaces in the training loop. We then test this method empirically on a real world dataset in the domain of credit card fraud detection. We show that our method can prevent about 30% performance drops under moderate attacks and is essential under very aggressive attacks, with a trade-off loss in performance under no attacks smaller than 7%.
FairGBM: Gradient Boosting with Fairness Constraints
Sep 19, 2022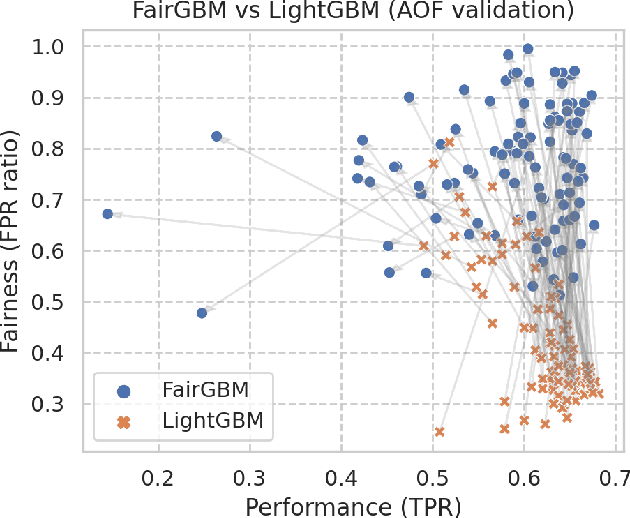
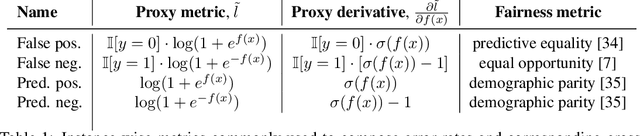
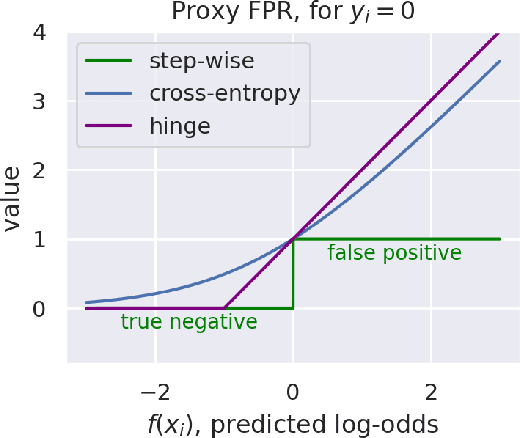
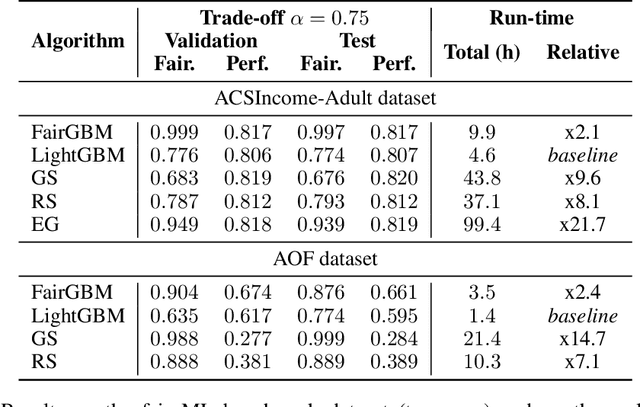
Machine Learning (ML) algorithms based on gradient boosted decision trees (GBDT) are still favored on many tabular data tasks across various mission critical applications, from healthcare to finance. However, GBDT algorithms are not free of the risk of bias and discriminatory decision-making. Despite GBDT's popularity and the rapid pace of research in fair ML, existing in-processing fair ML methods are either inapplicable to GBDT, incur in significant train time overhead, or are inadequate for problems with high class imbalance. We present FairGBM, a learning framework for training GBDT under fairness constraints with little to no impact on predictive performance when compared to unconstrained LightGBM. Since common fairness metrics are non-differentiable, we employ a "proxy-Lagrangian" formulation using smooth convex error rate proxies to enable gradient-based optimization. Additionally, our open-source implementation shows an order of magnitude speedup in training time when compared with related work, a pivotal aspect to foster the widespread adoption of FairGBM by real-world practitioners.
Understanding Unfairness in Fraud Detection through Model and Data Bias Interactions
Jul 13, 2022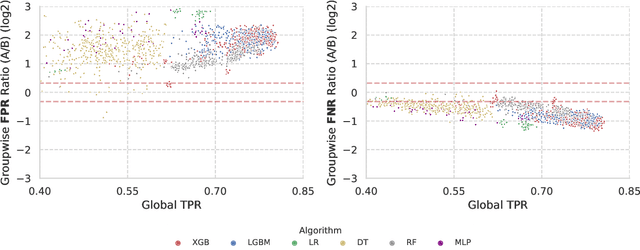
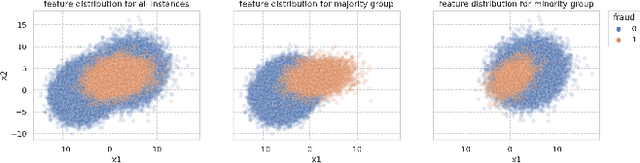
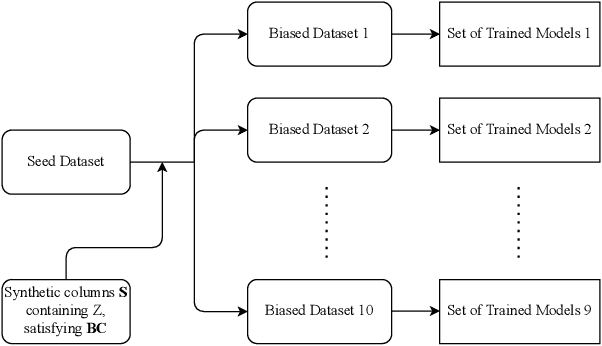
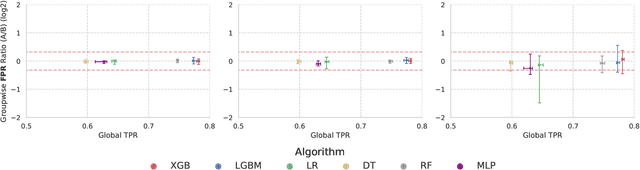
In recent years, machine learning algorithms have become ubiquitous in a multitude of high-stakes decision-making applications. The unparalleled ability of machine learning algorithms to learn patterns from data also enables them to incorporate biases embedded within. A biased model can then make decisions that disproportionately harm certain groups in society -- limiting their access to financial services, for example. The awareness of this problem has given rise to the field of Fair ML, which focuses on studying, measuring, and mitigating unfairness in algorithmic prediction, with respect to a set of protected groups (e.g., race or gender). However, the underlying causes for algorithmic unfairness still remain elusive, with researchers divided between blaming either the ML algorithms or the data they are trained on. In this work, we maintain that algorithmic unfairness stems from interactions between models and biases in the data, rather than from isolated contributions of either of them. To this end, we propose a taxonomy to characterize data bias and we study a set of hypotheses regarding the fairness-accuracy trade-offs that fairness-blind ML algorithms exhibit under different data bias settings. On our real-world account-opening fraud use case, we find that each setting entails specific trade-offs, affecting fairness in expected value and variance -- the latter often going unnoticed. Moreover, we show how algorithms compare differently in terms of accuracy and fairness, depending on the biases affecting the data. Finally, we note that under specific data bias conditions, simple pre-processing interventions can successfully balance group-wise error rates, while the same techniques fail in more complex settings.
ARMS: Automated rules management system for fraud detection
Feb 14, 2020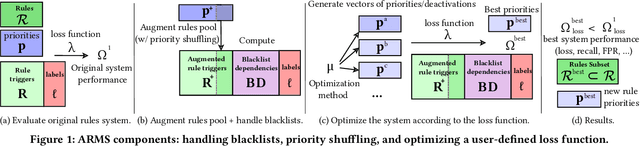
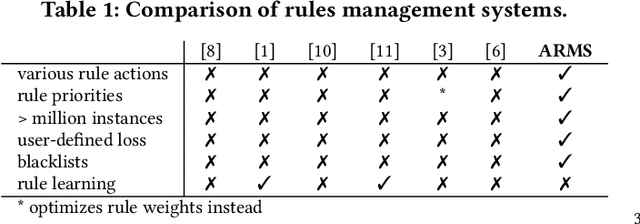
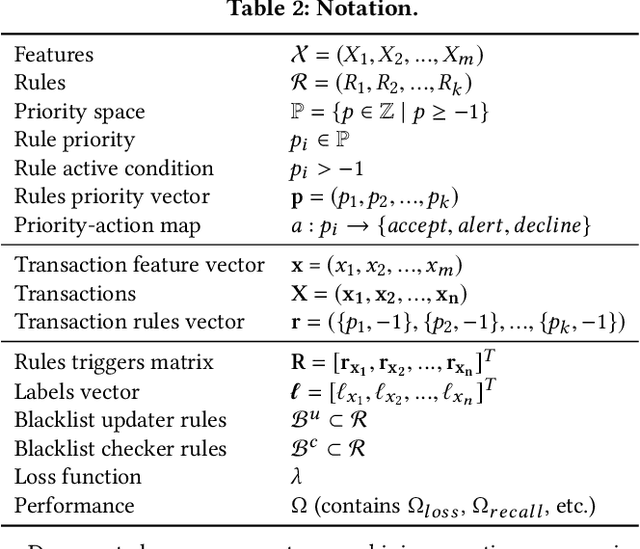
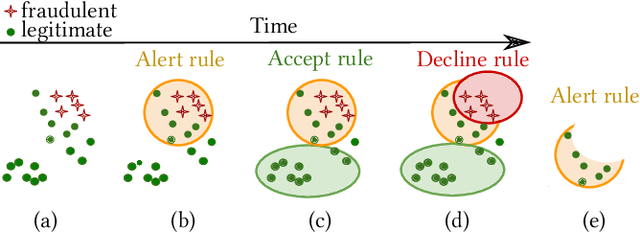
Fraud detection is essential in financial services, with the potential of greatly reducing criminal activities and saving considerable resources for businesses and customers. We address online fraud detection, which consists of classifying incoming transactions as either legitimate or fraudulent in real-time. Modern fraud detection systems consist of a machine learning model and rules defined by human experts. Often, the rules performance degrades over time due to concept drift, especially of adversarial nature. Furthermore, they can be costly to maintain, either because they are computationally expensive or because they send transactions for manual review. We propose ARMS, an automated rules management system that evaluates the contribution of individual rules and optimizes the set of active rules using heuristic search and a user-defined loss-function. It complies with critical domain-specific requirements, such as handling different actions (e.g., accept, alert, and decline), priorities, blacklists, and large datasets (i.e., hundreds of rules and millions of transactions). We use ARMS to optimize the rule-based systems of two real-world clients. Results show that it can maintain the original systems' performance (e.g., recall, or false-positive rate) using only a fraction of the original rules (~ 50% in one case, and ~ 20% in the other).