 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUE: Neural Networks Calibration via Learning Uncertainty-Error alignment
May 28, 2025



Reliable uncertainty estimation is critical for deploying neural networks (NNs) in real-world applications. While existing calibration techniques often rely on post-hoc adjustments or coarse-grained binning methods, they remain limited in scalability, differentiability, and generalization across domains. In this work, we introduce CLUE (Calibration via Learning Uncertainty-Error Alignment), a novel approach that explicitly aligns predicted uncertainty with observed error during training, grounded in the principle that well-calibrated models should produce uncertainty estimates that match their empirical loss. CLUE adopts a novel loss function that jointly optimizes predictive performance and calibration, using summary statistics of uncertainty and loss as proxies. The proposed method is fully differentiable, domain-agnostic, and compatible with standard training pipelines. Through extensive experiments on vision, regression, and language modeling tasks, including out-of-distribution and domain-shift scenarios, we demonstrate that CLUE achieves superior calibration quality and competitive predictive performance with respect to state-of-the-art approaches without imposing significant computational overhead.
GreenFactory: Ensembling Zero-Cost Proxies to Estimate Performance of Neural Networks
May 14, 2025Determining the performance of a Deep Neural Network during Neural Architecture Search processes is essential for identifying optimal architectures and hyperparameters. Traditionally, this process requires training and evaluation of each network, which is time-consuming and resource-intensive. Zero-cost proxies estimate performance without training, serving as an alternative to traditional training. However, recent proxies often lack generalization across diverse scenarios and provide only relative rankings rather than predicted accuracies. To address these limitations, we propose GreenFactory, an ensemble of zero-cost proxies that leverages a random forest regressor to combine multiple predictors' strengths and directly predict model test accuracy. We evaluate GreenFactory on NATS-Bench, achieving robust results across multiple datasets. Specifically, GreenFactory achieves high Kendall correlations on NATS-Bench-SSS, indicating substantial agreement between its predicted scores and actual performance: 0.907 for CIFAR-10, 0.945 for CIFAR-100, and 0.920 for ImageNet-16-120. Similarly, on NATS-Bench-TSS, we achieve correlations of 0.921 for CIFAR-10, 0.929 for CIFAR-100, and 0.908 for ImageNet-16-120, showcasing its reliability in both search spaces.
Error-Driven Uncertainty Aware Training
May 02, 2024



Neural networks are often overconfident about their predictions, which undermines their reliability and trustworthiness. In this work, we present a novel technique, named Error-Driven Uncertainty Aware Training (EUAT), which aims to enhance the ability of neural models to estimate their uncertainty correctly, namely to be highly uncertain when they output inaccurate predictions and low uncertain when their output is accurate. The EUAT approach operates during the model's training phase by selectively employing two loss functions depending on whether the training examples are correctly or incorrectly predicted by the model. This allows for pursuing the twofold goal of i) minimizing model uncertainty for correctly predicted inputs and ii) maximizing uncertainty for mispredicted inputs, while preserving the model's misprediction rate. We evaluate EUAT using diverse neural models and datasets in the image recognition domains considering both non-adversarial and adversarial settings. The results show that EUAT outperforms existing approaches for uncertainty estimation (including other uncertainty-aware training techniques, calibration, ensembles, and DEUP) by providing uncertainty estimates that not only have higher quality when evaluated via statistical metrics (e.g., correlation with residuals) but also when employed to build binary classifiers that decide whether the model's output can be trusted or not and under distributional data shifts.
Adversarial training for tabular data with attack propagation
Jul 28, 2023Adversarial attacks are a major concern in security-centered applications, where malicious actors continuously try to mislead Machine Learning (ML) models into wrongly classifying fraudulent activity as legitimate, whereas system maintainers try to stop them. Adversarially training ML models that are robust against such attacks can prevent business losses and reduce the work load of system maintainers. In such applications data is often tabular and the space available for attackers to manipulate undergoes complex feature engineering transformations, to provide useful signals for model training, to a space attackers cannot access. Thus, we propose a new form of adversarial training where attacks are propagated between the two spaces in the training loop. We then test this method empirically on a real world dataset in the domain of credit card fraud detection. We show that our method can prevent about 30% performance drops under moderate attacks and is essential under very aggressive attacks, with a trade-off loss in performance under no attacks smaller than 7%.
Hyper-parameter Tuning for Adversarially Robust Models
Apr 05, 2023



This work focuses on the problem of hyper-parameter tuning (HPT) for robust (i.e., adversarially trained) models, with the twofold goal of i) establishing which additional HPs are relevant to tune in adversarial settings, and ii) reducing the cost of HPT for robust models. We pursue the first goal via an extensive experimental study based on 3 recent models widely adopted in the prior literature on adversarial robustness. Our findings show that the complexity of the HPT problem, already notoriously expensive, is exacerbated in adversarial settings due to two main reasons: i) the need of tuning additional HPs which balance standard and adversarial training; ii) the need of tuning the HPs of the standard and adversarial training phases independently. Fortunately, we also identify new opportunities to reduce the cost of HPT for robust models. Specifically, we propose to leverage cheap adversarial training methods to obtain inexpensive, yet highly correlated, estimations of the quality achievable using state-of-the-art methods (PGD). We show that, by exploiting this novel idea in conjunction with a recent multi-fidelity optimizer (taKG), the efficiency of the HPT process can be significantly enhanced.
HyperJump: Accelerating HyperBand via Risk Modelling
Aug 05, 2021
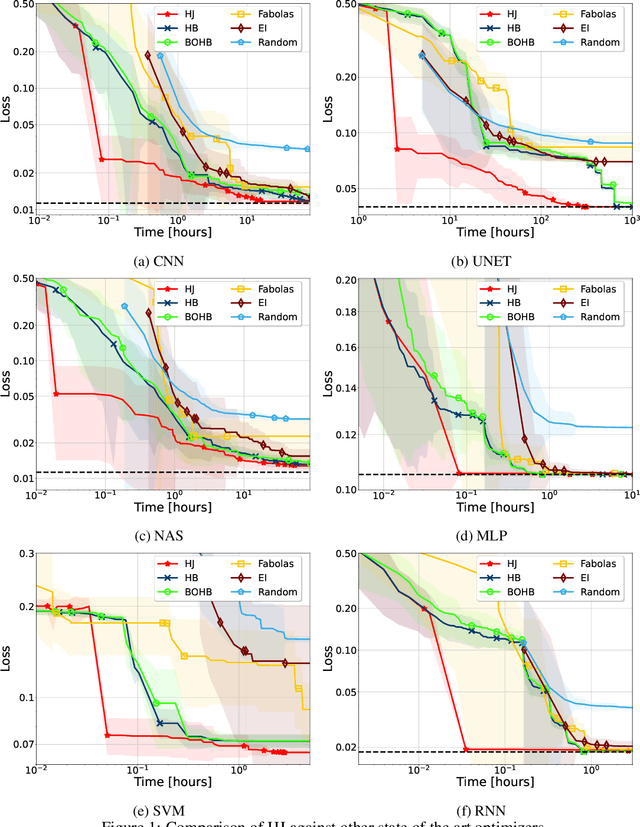
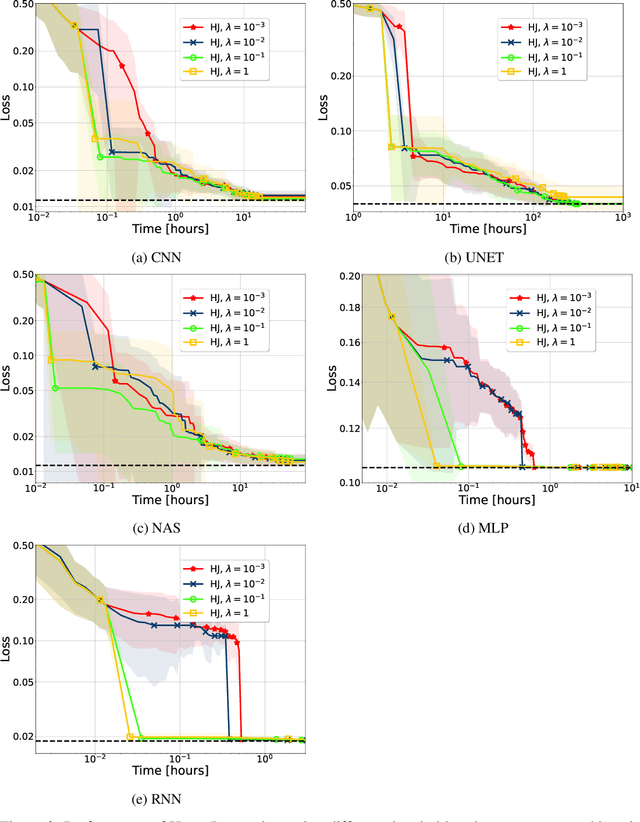
In the literature on hyper-parameter tuning, a number of recent solutions rely on low-fidelity observations (e.g., training with sub-sampled datasets or for short periods of time) to extrapolate good configurations to use when performing full training. Among these, HyperBand is arguably one of the most popular solutions, due to its efficiency and theoretically provable robustness. In this work, we introduce HyperJump, a new approach that builds on HyperBand's robust search strategy and complements it with novel model-based risk analysis techniques that accelerate the search by jumping the evaluation of low risk configurations, i.e., configurations that are likely to be discarded by HyperBand. We evaluate HyperJump on a suite of hyper-parameter optimization problems and show that it provides over one-order of magnitude speed-ups on a variety of deep-learning and kernel-based learning problems when compared to HyperBand as well as to a number of state of the art optimizers.
TrimTuner: Efficient Optimization of Machine Learning Jobs in the Cloud via Sub-Sampling
Nov 09, 2020
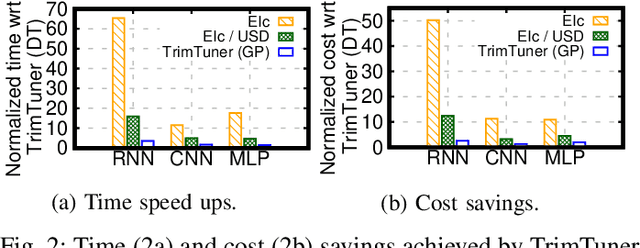
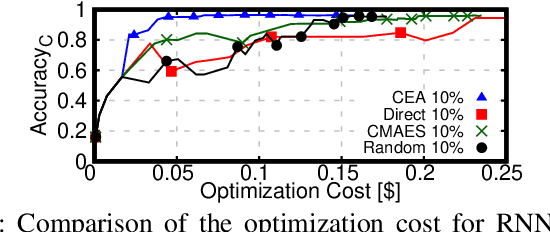
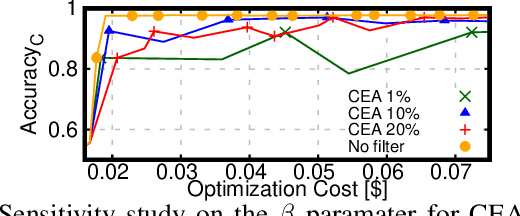
This work introduces TrimTuner, the first system for optimizing machine learning jobs in the cloud to exploit sub-sampling techniques to reduce the cost of the optimization process while keeping into account user-specified constraints. TrimTuner jointly optimizes the cloud and application-specific parameters and, unlike state of the art works for cloud optimization, eschews the need to train the model with the full training set every time a new configuration is sampled. Indeed, by leveraging sub-sampling techniques and data-sets that are up to 60x smaller than the original one, we show that TrimTuner can reduce the cost of the optimization process by up to 50x. Further, TrimTuner speeds-up the recommendation process by 65x with respect to state of the art techniques for hyper-parameter optimization that use sub-sampling techniques. The reasons for this improvement are twofold: i) a novel domain specific heuristic that reduces the number of configurations for which the acquisition function has to be evaluated; ii) the adoption of an ensemble of decision trees that enables boosting the speed of the recommendation process by one additional order of magnitude.
On Bootstrapping Machine Learning Performance Predictors via Analytical Models
Oct 19, 2014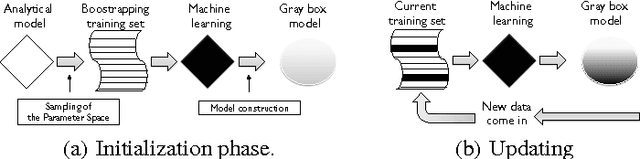
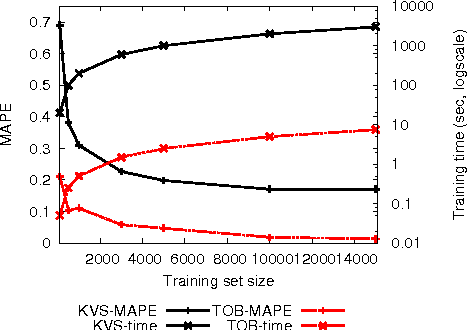
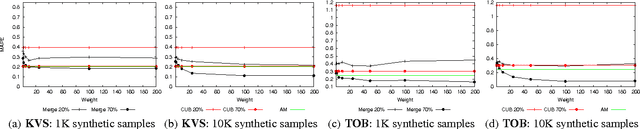
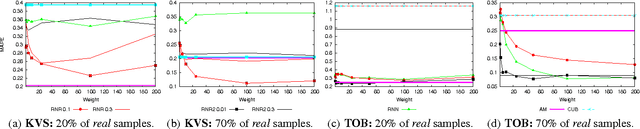
Performance modeling typically relies on two antithetic methodologies: white box models, which exploit knowledge on system's internals and capture its dynamics using analytical approaches, and black box techniques, which infer relations among the input and output variables of a system based on the evidences gathered during an initial training phase. In this paper we investigate a technique, which we name Bootstrapping, which aims at reconciling these two methodologies and at compensating the cons of the one with the pros of the other. We thoroughly analyze the design space of this gray box modeling technique, and identify a number of algorithmic and parametric trade-offs which we evaluate via two realistic case studies, a Key-Value Store and a Total Order Broadcast service.