 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestore from Restored: Video Restoration with Pseudo Clean Video
Mar 09, 2020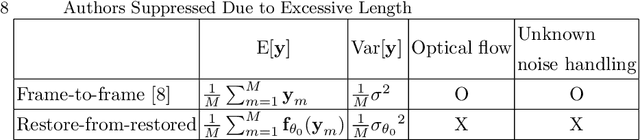
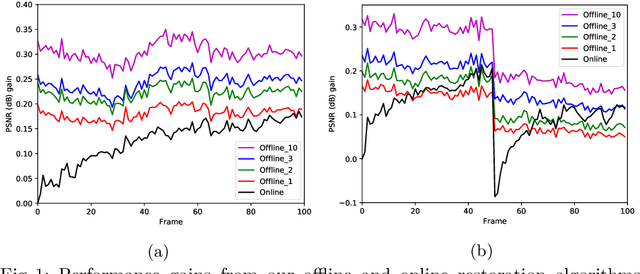

In this paper, we propose a self-supervised video denoising method called "restore-from-restored" that fine-tunes a baseline network by using a pseudo clean video at the test phase. The pseudo clean video can be obtained by applying an input noisy video to the pre-trained baseline network. By adopting a fully convolutional network (FCN) as the baseline, we can restore videos without accurate optical flow and registration due to its translation-invariant property unlike many conventional video restoration methods. Moreover, the proposed method can take advantage of the existence of many similar patches across consecutive frames (i.e., patch-recurrence), which can boost performance of the baseline network by a large margin. We analyze the restoration performance of the FCN fine-tuned with the proposed self-supervision-based training algorithm, and demonstrate that FCN can utilize recurring patches without the need for registration among adjacent frames. The proposed method can be applied to any FCN-based denoising models. In our experiments, we apply the proposed method to the state-of-the-art denoisers, and our results indicate a considerable improvementin task performance.
Restore from Restored: Single Image Denoising with Pseudo Clean Image
Mar 09, 2020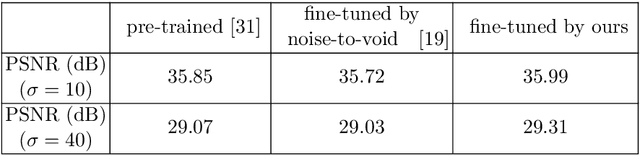

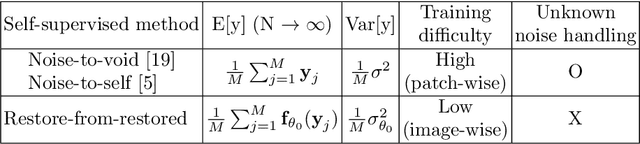
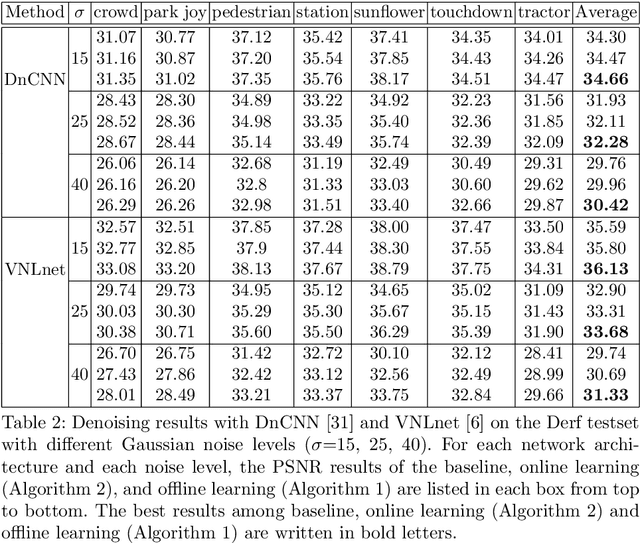
Under certain statistical assumptions of noise (e.g., zero-mean noise), recent self-supervised approaches for denoising have been introduced to learn network parameters without ground-truth clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet properly combined with conventional supervised denoising methods which train the denoising networks with a large number of external training images. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting (fine-tuning) their network parameters to the given specific input through self-supervision without changing the fully original network architectures. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous denoising benchmark datasets.
Fast Adaptation to Super-Resolution Networks via Meta-Learning
Jan 14, 2020
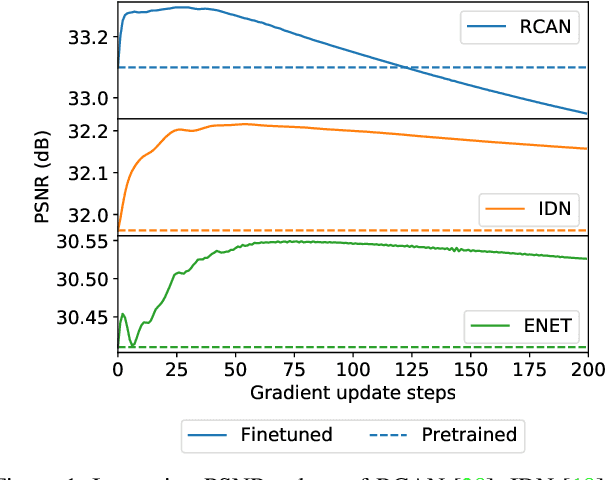
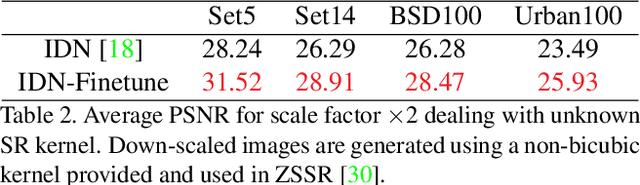
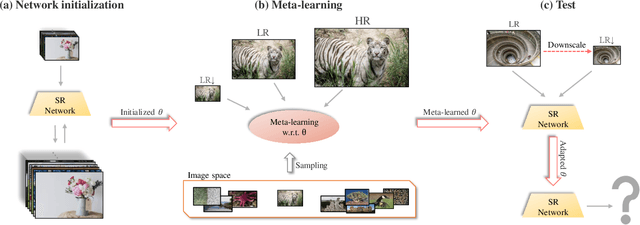
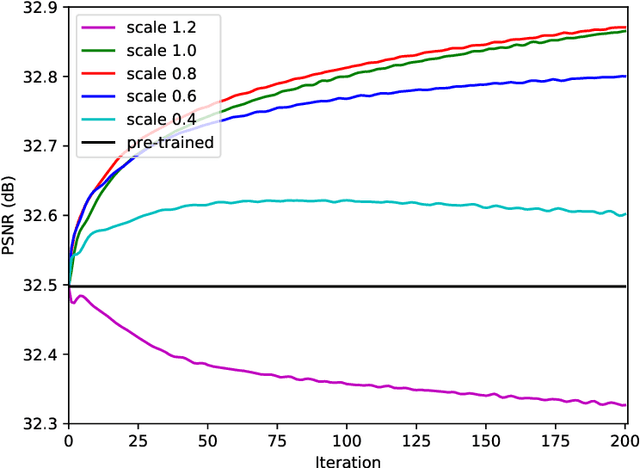
Conventional supervised super-resolution (SR) approaches are trained with massive external SR datasets but fail to exploit desirable properties of the given test image. On the other hand, self-supervised SR approaches utilize the internal information within a test image but suffer from computational complexity in run-time. In this work, we observe the opportunity for further improvement of the performance of SISR without changing the architecture of conventional SR networks by practically exploiting additional information given from the input image. In the training stage, we train the network via meta-learning; thus, the network can quickly adapt to any input image at test time. Then, in the test stage, parameters of this meta-learned network are rapidly fine-tuned with only a few iterations by only using the given low-resolution image. The adaptation at the test time takes full advantage of patch-recurrence property observed in natural images. Our method effectively handles unknown SR kernels and can be applied to any existing model. We demonstrate that the proposed model-agnostic approach consistently improves the performance of conventional SR networks on various benchmark SR datasets.
Self-Supervised Fast Adaptation for Denoising via Meta-Learning
Jan 09, 2020



Under certain statistical assumptions of noise, recent self-supervised approaches for denoising have been introduced to learn network parameters without true clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet combined with conventional supervised denoising methods which train the denoising networks with a large number of external training samples. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting their network parameters to the given input through selfsupervision without changing the networks architectures. Moreover, we propose a meta-learning algorithm to enable quick adaptation of parameters to the specific input at test time. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous benchmark datasets.
Key Instance Selection for Unsupervised Video Object Segmentation
Jul 26, 2019

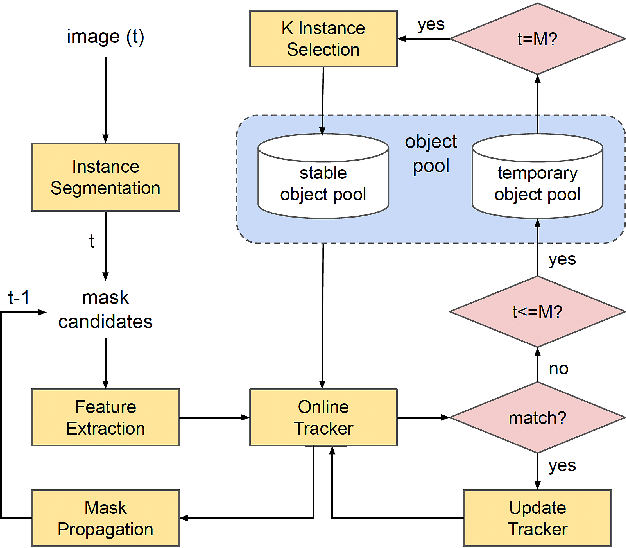
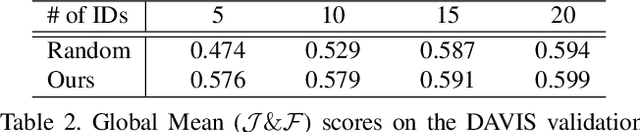
This paper proposes key instance selection based on video saliency covering objectness and dynamics for unsupervised video object segmentation (UVOS). Our method takes frames sequentially and extracts object proposals with corresponding masks for each frame. We link objects according to their similarity until the M-th frame and then assign them unique IDs (i.e., instances). Similarity measure takes into account multiple properties such as ReID descriptor, expected trajectory, and semantic co-segmentation result. After M-th frame, we select K IDs based on video saliency and frequency of appearance; then only these key IDs are tracked through the remaining frames. Thanks to these technical contributions, our results are ranked third on the leaderboard of UVOS DAVIS challenge.
Discriminative Few-Shot Learning Based on Directional Statistics
Jun 05, 2019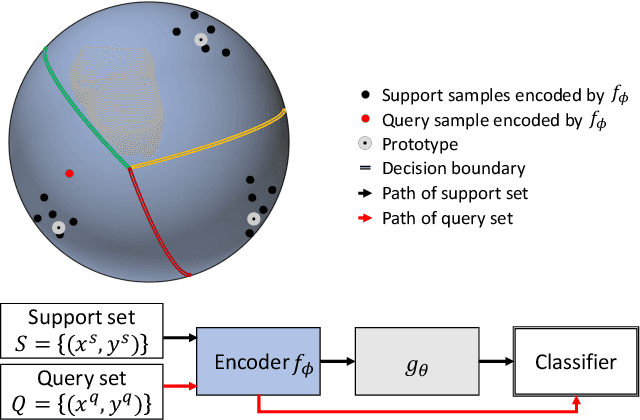

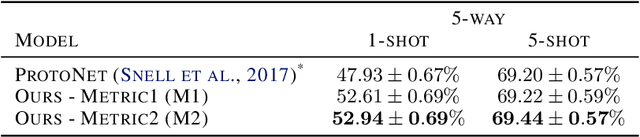
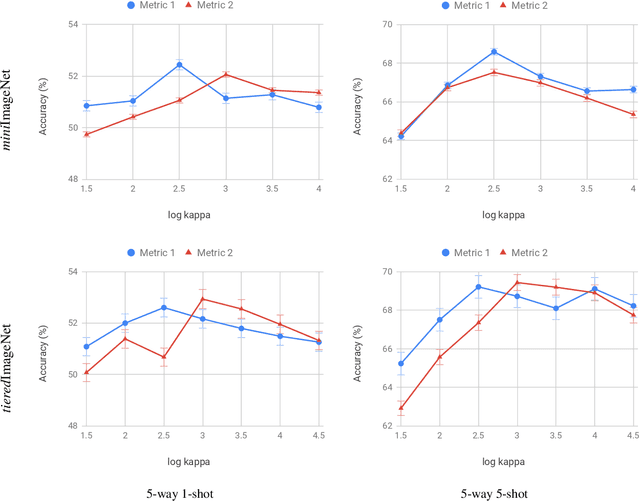
Metric-based few-shot learning methods try to overcome the difficulty due to the lack of training examples by learning embedding to make comparison easy. We propose a novel algorithm to generate class representatives for few-shot classification tasks. As a probabilistic model for learned features of inputs, we consider a mixture of von Mises-Fisher distributions which is known to be more expressive than Gaussian in a high dimensional space. Then, from a discriminative classifier perspective, we get a better class representative considering inter-class correlation which has not been addressed by conventional few-shot learning algorithms. We apply our method to \emph{mini}ImageNet and \emph{tiered}ImageNet datasets, and show that the proposed approach outperforms other comparable methods in few-shot classification tasks.
Attention-based Recurrent Neural Network for Urban Vehicle Trajectory Prediction
Dec 18, 2018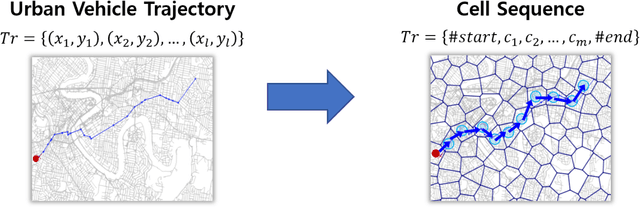

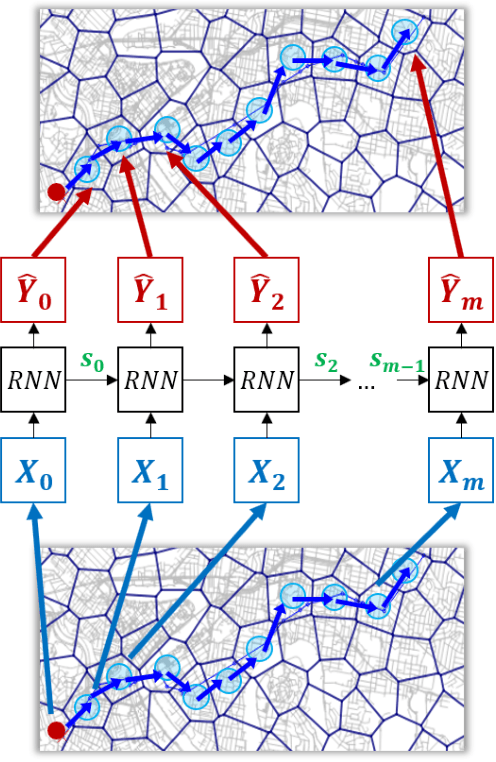
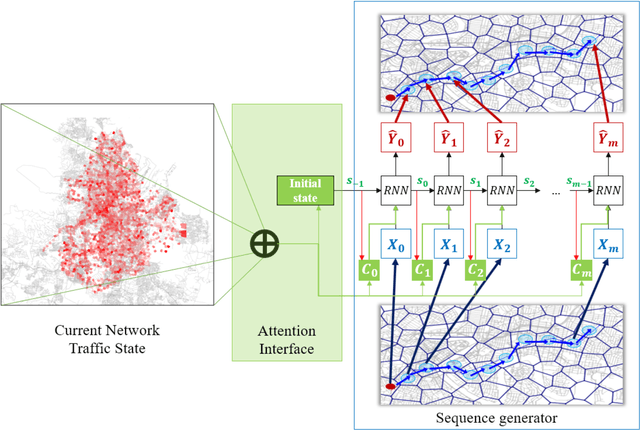
As the number of various positioning sensors and location-based devices increase, a huge amount of spatial and temporal information data is collected and accumulated. These data are expressed as trajectory data by connecting the data points in chronological sequence, and thses data contain movement information of any moving object. Particularly, in this study, urban vehicle trajectory prediction is studied using trajectory data of vehicles in urban traffic network. In the previous work, Recurrent Neural Network model for urban vehicle trajectory prediction is proposed. For the further improvement of the model, in this study, we propose Attention-based Recurrent Neural Network model for urban vehicle trajectory prediction. In this proposed model, we use attention mechanism to incorporate network traffic state data into urban vehicle trajectory prediction. The model is evaluated by using the Bluetooth data collected in Brisbane, Australia, which contains the movement information of private vehicles. The performance of the model is evaluated with 5 metrics, which are BLEU-1, BLEU-2, BLEU-3, BLEU-4, and METEOR. The result shows that ARNN model have better performance compared to RNN model.
Doubly Nested Network for Resource-Efficient Inference
Jun 20, 2018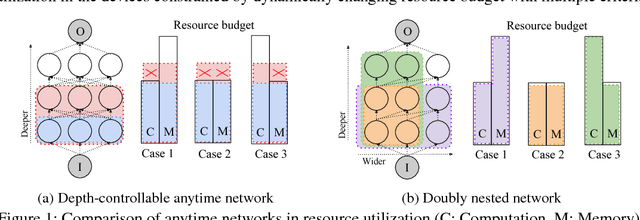
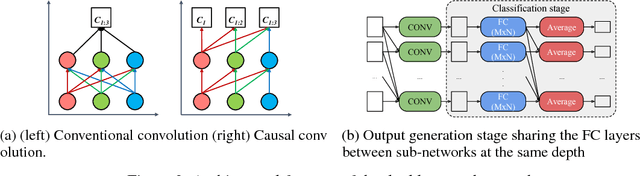
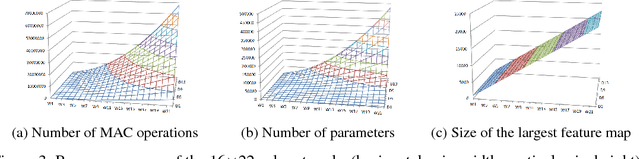
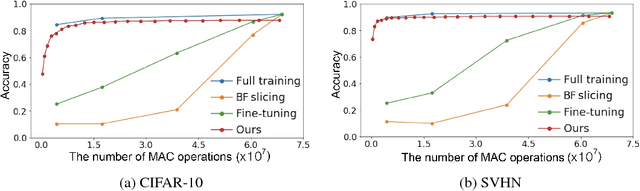
We propose doubly nested network(DNNet) where all neurons represent their own sub-models that solve the same task. Every sub-model is nested both layer-wise and channel-wise. While nesting sub-models layer-wise is straight-forward with deep-supervision as proposed in \cite{xie2015holistically}, channel-wise nesting has not been explored in the literature to our best knowledge. Channel-wise nesting is non-trivial as neurons between consecutive layers are all connected to each other. In this work, we introduce a technique to solve this problem by sorting channels topologically and connecting neurons accordingly. For the purpose, channel-causal convolutions are used. Slicing doubly nested network gives a working sub-network. The most notable application of our proposed network structure with slicing operation is resource-efficient inference. At test time, computing resources such as time and memory available for running the prediction algorithm can significantly vary across devices and applications. Given a budget constraint, we can slice the network accordingly and use a sub-model for inference within budget, requiring no additional computation such as training or fine-tuning after deployment. We demonstrate the effectiveness of our approach in several practical scenarios of utilizing available resource efficiently.
Meta Continual Learning
Jun 11, 2018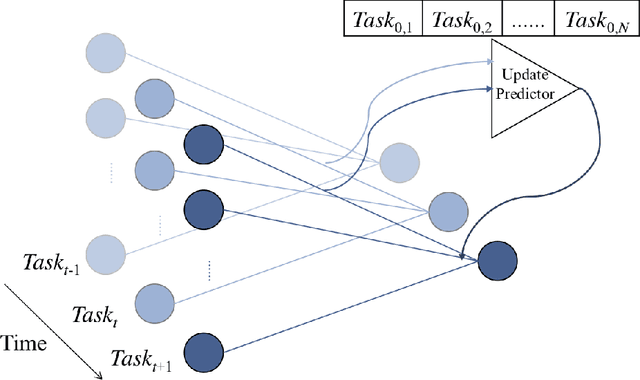

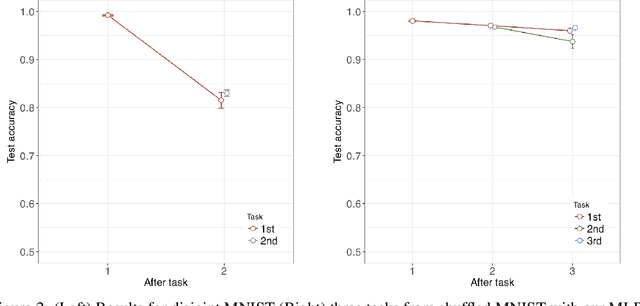
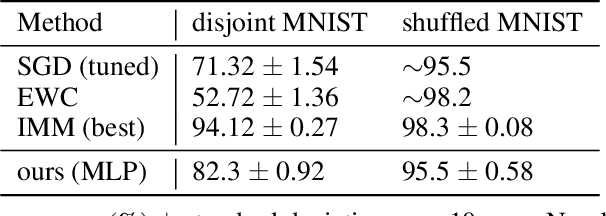
Using neural networks in practical settings would benefit from the ability of the networks to learn new tasks throughout their lifetimes without forgetting the previous tasks. This ability is limited in the current deep neural networks by a problem called catastrophic forgetting, where training on new tasks tends to severely degrade performance on previous tasks. One way to lessen the impact of the forgetting problem is to constrain parameters that are important to previous tasks to stay close to the optimal parameters. Recently, multiple competitive approaches for computing the importance of the parameters with respect to the previous tasks have been presented. In this paper, we propose a learning to optimize algorithm for mitigating catastrophic forgetting. Instead of trying to formulate a new constraint function ourselves, we propose to train another neural network to predict parameter update steps that respect the importance of parameters to the previous tasks. In the proposed meta-training scheme, the update predictor is trained to minimize loss on a combination of current and past tasks. We show experimentally that the proposed approach works in the continual learning setting.
Auto-Meta: Automated Gradient Based Meta Learner Search
Jun 11, 2018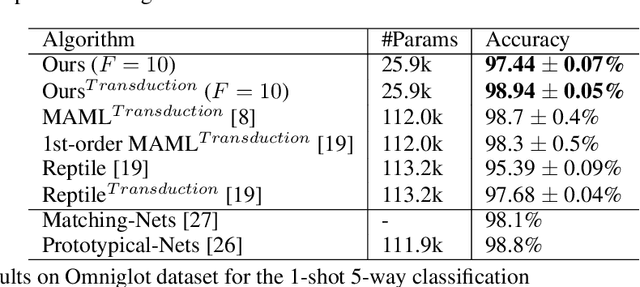
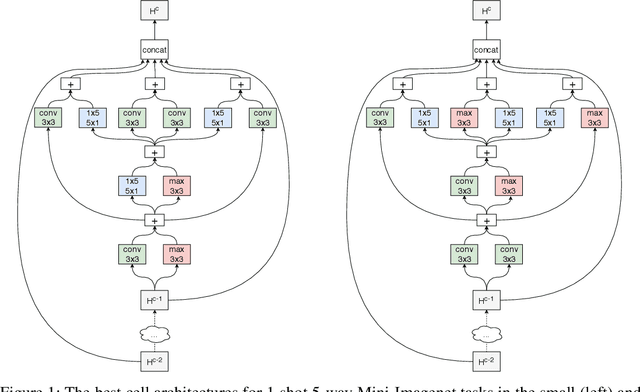
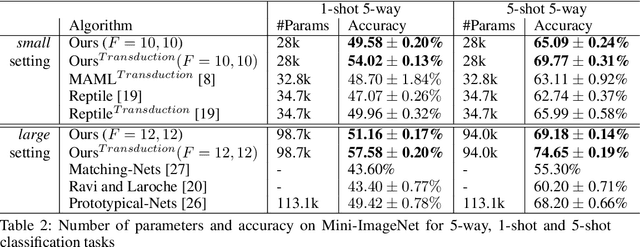
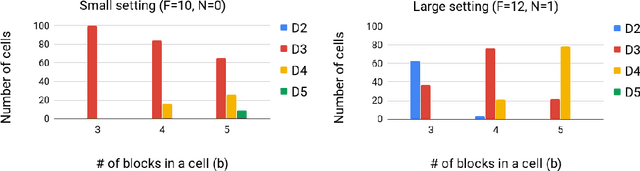
Fully automating machine learning pipeline is one of the outstanding challenges of general artificial intelligence, as practical machine learning often requires costly human driven process, such as hyper-parameter tuning, algorithmic selection, and model selection. In this work, we consider the problem of executing automated, yet scalable search for finding optimal gradient based meta-learners in practice. As a solution, we apply progressive neural architecture search to proto-architectures by appealing to the model agnostic nature of general gradient based meta learners. In the presence of recent universality result of Finn \textit{et al.}\cite{finn:universality_maml:DBLP:/journals/corr/abs-1710-11622}, our search is a priori motivated in that neural network architecture search dynamics---automated or not---may be quite different from that of the classical setting with the same target tasks, due to the presence of the gradient update operator. A posteriori, our search algorithm, given appropriately designed search spaces, finds gradient based meta learners with non-intuitive proto-architectures that are narrowly deep, unlike the inception-like structures previously observed in the resulting architectures of traditional NAS algorithms. Along with these notable findings, the searched gradient based meta-learner achieves state-of-the-art results on the few shot classification problem on Mini-ImageNet with $76.29\%$ accuracy, which is an $13.18\%$ improvement over results reported in the original MAML paper. To our best knowledge, this work is the first successful AutoML implementation in the context of meta learning.